一、字典基础:python的"哈希宝石"
字典(dict)是python中的一种可变容器模型,可以存储任意类型的对象。字典中的每个元素都是一个键值对(key-value pair),键(key)必须是不可变类型,通常是字符串或数字,而值(value)则可以是任意python对象。
# 创建一个简单的字典
user_profile = {
"username": "python_lover",
"age": 28,
"skills": ["python", "django", "flask"],
"is_active": true
}
字典就像是一本真实的字典(词典),我们可以通过"单词"(键)快速查找其"释义"(值),这种设计使得字典的查找效率非常高,时间复杂度为o(1)。
二、字典常用方法全解析
1. 基本操作
| 方法 | 描述 | 示例 | 时间复杂度 |
|---|---|---|---|
| dict[key] | 获取键对应的值 | user_profile["username"] | o(1) |
| dict[key] = value | 设置键值对 | user_profile["email"] = "user@example.com" | o(1) |
| del dict[key] | 删除键值对 | del user_profile["is_active"] | o(1) |
| key in dict | 检查键是否存在 | "age" in user_profile | o(1) |
2. 字典遍历
# 遍历键
for key in user_profile:
print(f"key: {key}")
# 遍历值
for value in user_profile.values():
print(f"value: {value}")
# 遍历键值对
for key, value in user_profile.items():
print(f"{key}: {value}")
3. 常用方法详解
get() - 安全获取值
# 传统方式可能引发keyerror
age = user_profile["age"]
# 更安全的方式
age = user_profile.get("age", 0) # 如果age不存在,返回默认值0
setdefault() - 智能设置默认值
# 统计单词频率的经典用法
word_counts = {}
for word in ["apple", "banana", "apple", "orange"]:
word_counts.setdefault(word, 0)
word_counts[word] += 1
update() - 批量更新字典
# 合并两个字典
default_settings = {"theme": "light", "notifications": true}
user_settings = {"theme": "dark", "language": "en"}
default_settings.update(user_settings)
# 结果: {'theme': 'dark', 'notifications': true, 'language': 'en'}
pop()和popitem() - 删除元素
# 删除指定键并返回其值
removed_value = user_profile.pop("age")
# 删除并返回最后一个键值对(3.7+版本有序)
last_item = user_profile.popitem()
4. 字典推导式
# 创建一个数字到其平方的映射
squares = {x: x*x for x in range(1, 6)}
# 结果: {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# 条件过滤
even_squares = {x: x*x for x in range(10) if x % 2 == 0}
三、字典的高级应用
1. 使用defaultdict简化代码
from collections import defaultdict
# 自动为不存在的键初始化默认值
word_counts = defaultdict(int)
for word in ["apple", "banana", "apple"]:
word_counts[word] += 1
2. 有序字典ordereddict
from collections import ordereddict # 记住元素插入顺序(在python 3.7+中普通dict也有序) ordered_dict = ordereddict() ordered_dict["first"] = 1 ordered_dict["second"] = 2
3. 合并字典的多种方式
# python 3.9+ 新特性
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 3, "c": 4}
merged = dict1 | dict2 # {'a': 1, 'b': 3, 'c': 4}
# 传统方式
merged = {**dict1, **dict2}
四、性能优化与内部实现
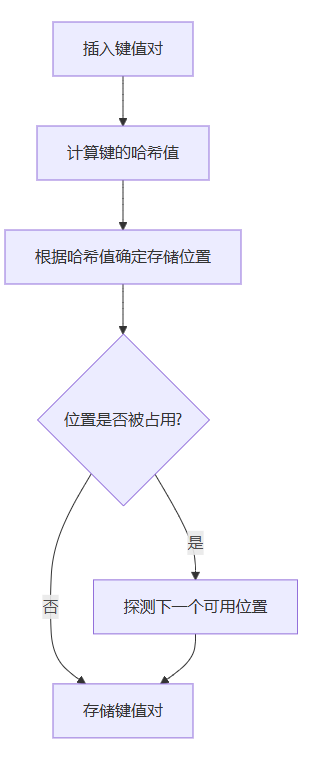
python字典使用哈希表实现,具有极高的查找效率。了解其内部机制有助于编写更高效的代码:
- 哈希冲突解决:python使用开放寻址法处理冲突
- 动态扩容:当字典填充超过2/3时自动扩容
- 内存优化:python 3.6+中字典更紧凑,内存使用更高效
五、实战案例:缓存系统实现
class lrucache:
def __init__(self, capacity: int):
self.cache = ordereddict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return -1
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=false)
这个简单的lru(最近最少使用)缓存实现展示了字典在实际应用中的强大能力,结合ordereddict可以高效实现缓存淘汰策略。
六、总结
python字典是一个功能丰富、性能卓越的数据结构,掌握它的各种方法和特性可以显著提升代码质量和效率。从简单的键值存储到复杂的缓存系统,字典都能优雅地完成任务。记住:
- 字典查找速度快(o(1)),适合快速查找场景
- 合理使用字典方法可以简化代码逻辑
- python 3.7+中字典保持插入顺序
- 了解内部实现有助于编写高性能代码
到此这篇关于从基础到高级应用解析python中的字典(dict)的文章就介绍到这了,更多相关python字典dict内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论