一、背景介绍
这段时间工作上,需要开发一个功能,可以动态选择表和字段形成一条条规则,然后规则又可以进行不通的组合,比如三条中至少满足一条并且满足另外一条这种刁钻的规则条件,具体功能描述可以看图。当时还真是为了实现这个功能考虑到头大,他难点在于既要实现规则的判断,又要满足下面条件的二次判断,好在也在同事的帮助下想出了思路,这里和大家分享下,后续类似地方都可以参考这个思路。
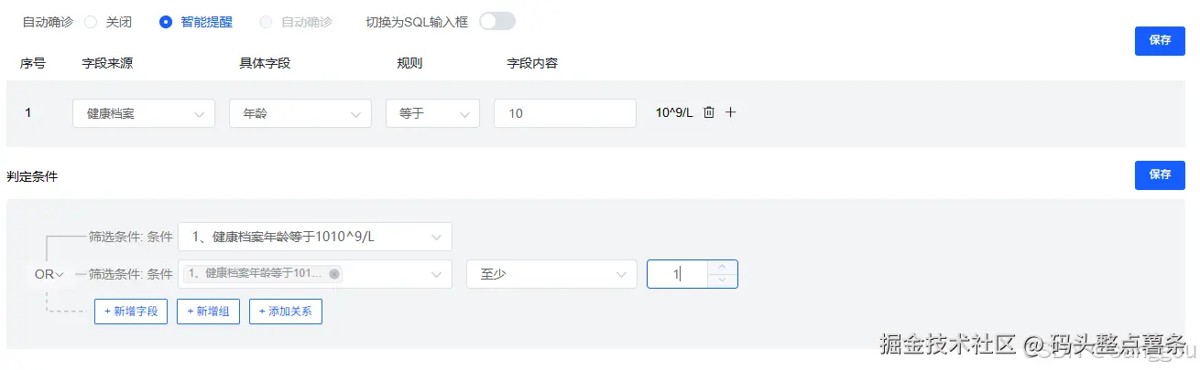
二、核心思路分析
1. 问题分析
在系统中,我们需要实现以下功能:
- 支持灵活配置各种判定规则
- 支持规则之间的逻辑组合(and/or)
- 支持规则组的概念(设置最小 / 最大满足数量)
- 支持可视化配置规则树
2. 设计思路
为了解决这些问题,我们采用了以下设计思路:
(1)数据模型设计
将规则系统分为两个核心部分:
- 规则定义:存储具体的规则内容(如血压 > 140mmhg)
- 规则配置:存储规则之间的逻辑关系(如规则 a and 规则 b)
(2)树形结构设计
使用树形结构来表示规则之间的逻辑关系,支持三种节点类型:
- rule:具体的规则节点
- operator:逻辑运算符节点(and/or)
- group:规则组节点
(3)递归处理机制
使用递归算法来处理树形结构,实现规则树的转换和解析。
三、核心代码讲解
1. 数据模型定义
(1)规则定义表(monruledefinitions)
@data
@equalsandhashcode(callsuper = false)
@accessors(chain = true)
@tablename("mon_rule_definitions")
@apimodel(value = "monruledefinitions对象", description = "判定规则定义表")
public class monruledefinitions extends model<monruledefinitions> {
@apimodelproperty(value = "主键")
@tableid(value = "id", type = idtype.assign_id)
private string id;
@apimodelproperty(value = "规则组id")
@tablefield("rule_group_id")
private string rulegroupid;
@apimodelproperty(value = "来源字典编码【字典】;table_name")
@tablefield("from_dict_code")
private string fromdictcode;
@apimodelproperty(value = "具体字段编码")
@tablefield("specific_field_code")
private string specificfieldcode;
@apimodelproperty(value = "匹配值代码【字典】;more_range")
@tablefield("match_type_code")
private string matchtypecode;
@apimodelproperty(value = "指标值")
@tablefield("item_value")
private string itemvalue;
// ... 其他字段
}
代码分析:
- 使用 mybatis-plus 的注解来映射数据库表
- 每个规则定义包含来源、字段、匹配类型、指标值等信息
- 支持多种匹配类型(如大于、小于、等于)
(2)规则配置表(monbaseruleconfig)
@data
@equalsandhashcode(callsuper = false)
@accessors(chain = true)
@tablename("mon_rule_config")
@apimodel(value = "monbaseruleconfig对象", description = "判定规则配置表")
public class monbaseruleconfig extends model<monbaseruleconfig> {
@apimodelproperty(value = "主键")
@tableid(value = "id", type = idtype.assign_id)
private string id;
@apimodelproperty(value = "规则类型 1-疾病分级 2-患者管理 3-质控")
@tablefield("rule_type")
private string ruletype;
@apimodelproperty(value = "规则组id")
@tablefield("rule_group_id")
private string rulegroupid;
@apimodelproperty(value = "父节点id,用于构建树结构")
@tablefield("parent_node_id")
private string parentnodeid;
@apimodelproperty(value = "节点类型(rule、operator、group)")
@tablefield("node_type")
private string nodetype;
@apimodelproperty(value = "逻辑运算符(and、or);more_range")
@tablefield("operator")
private string operator;
@apimodelproperty(value = "如果节点是规则,则关联规则id")
@tablefield("rule_id")
private string ruleid;
@apimodelproperty(value = "对于group类型,最少满足的规则数量;item_result_unit_code")
@tablefield("min_count")
private string mincount;
@apimodelproperty(value = "对于group类型,最多满足的规则数量")
@tablefield("max_count")
private string maxcount;
// ... 其他字段
}
代码分析:
- 支持三种节点类型:rule、operator、group
- 使用 parentnodeid 来构建树形结构
- group 类型支持设置最小 / 最大满足数量
2. 规则节点工具类(rulenodeutil)
(1)递归转换规则节点
public static void convertandcollectnodes(rulenodedto currentnode, string rulegroupid,
string parentnodeid, list<monbaseruleconfig> allnodes) {
if ("rule".equals(currentnode.getnodetype())&¤tnode.getruleid() == null) {
throw new baseexception(998,"规则节点缺少规则id");
}
// 转换当前dto为数据库实体
monbaseruleconfig dbnode = new monbaseruleconfig();
beanutil.copyproperties(currentnode, dbnode);
dbnode.setrulegroupid(rulegroupid);
// 特殊处理group类型
if ("group".equals(currentnode.getnodetype())) {
dbnode.setruleid(string.join(",",(list<string>) currentnode.getruleid()));
if ("min".equals(currentnode.getcounttype())){
dbnode.setmincount(currentnode.getcount());
dbnode.setmaxcount("");
}else {
dbnode.setmaxcount(currentnode.getcount());
dbnode.setmincount("");
}
}
allnodes.add(dbnode);
// 递归处理子节点
if (!collectionutils.isempty(currentnode.getchildren())) {
for (rulenodedto child : currentnode.getchildren()) {
convertandcollectnodes(child, rulegroupid, currentnode.getid(), allnodes);
}
}
}
代码分析:
- 递归处理规则树,将前端传递的 dto 转换为数据库实体
- 特殊处理 group 类型,支持设置最小 / 最大满足数量
- 验证规则节点是否缺少规则 id
(2)构建规则树
public static rulenodedto buildnode(monbaseruleconfig currentnode, map<string, list<monbaseruleconfig>> parentmap) {
// 转换为dto
rulenodedto nodedto = beanutil.copyproperties(currentnode,rulenodedto.class);
// 获取当前节点的子节点列表
list<monbaseruleconfig> children = parentmap.getordefault(currentnode.getid(), new arraylist<>());
// 递归构建子节点
list<rulenodedto> childdtos = children.stream()
.map(child -> buildnode(child, parentmap))
.collect(collectors.tolist());
// group节点特殊处理
if ("group".equals(currentnode.getnodetype())) {
if (!childdtos.isempty()) {
list<object> ruleids = childdtos.stream().map(rulenodedto::getruleid).collect(collectors.tolist());
rulenodedto rulenodedto = childdtos.get(0);
rulenodedto.setruleid(ruleids);
nodedto.setchildren(collections.singletonlist(rulenodedto));
}else {
nodedto.setchildren(childdtos);
}
} else {
// 非group节点保留完整嵌套结构
nodedto.setchildren(childdtos);
}
return nodedto;
}
代码分析:
- 递归构建规则树,将数据库实体转换为前端需要的 dto
- 特殊处理 group 类型,合并子节点的规则 id
- 保留完整的嵌套结构,方便前端展示
3. 规则配置服务实现(monbaseruleconfigserviceimpl)
(1)保存规则节点
public integer savenode(list<rulenodedto> judgegroup, string rulegroupid, list<monruledefinitions> ruledefinitions) {
if (collectionutils.isempty(judgegroup)) {
return 0;
}
// 收集所有转换后的数据库实体
list<monbaseruleconfig> allnodes = new arraylist<>();
// 处理顶级节点(递归处理所有子节点)
for (rulenodedto rootnode : judgegroup) {
rulenodeutil.convertandcollectnodes(rootnode, rulegroupid, null, allnodes);
}
// 批量插入数据库
if (!collectionutils.isempty(allnodes)) {
// 删除旧的规则配置
list<monbaseruleconfig> list = this.lambdaquery()
.eq(monbaseruleconfig::getrulegroupid, rulegroupid)
.list();
list.removeif(judge ->allnodes.stream()
.map(monbaseruleconfig::getid).collect(collectors.tolist()).contains(judge.getid()));
list<string> monconfigdel = list.stream().map(monbaseruleconfig::getid).collect(collectors.tolist());
this.removebyids(monconfigdel);
// 保存新的规则配置
this.saveorupdatebatch(allnodes);
}
return allnodes.size();
}
代码分析:
- 批量保存规则节点,支持新增和更新
- 先删除旧的规则配置,再保存新的规则配置
- 支持规则组的概念,方便管理多个规则
四、使用场景
1. 疾病分级判定
高血压分级 = (收缩压 > 140mmhg or 舒张压 > 90mmhg) and 年龄 > 65岁
2. 患者管理规则
高危患者 = (糖尿病 and 血压 > 130/80mmhg) or (冠心病 and 血脂异常)
3. 医疗质量控制
质控合格 = (病历书写完整率 > 95%) and (随访及时率 > 90%) and (患者满意度 > 85%)
五、总结
通过以上分析,我们可以看到这套规则引擎实现方案具有以下特点:
- 灵活性:支持任意复杂的规则组合
- 可扩展性:方便添加新的规则类型和逻辑
- 可视化:支持前端可视化配置规则树
- 复用性:规则可以被多个规则组复用
在实际应用中,我们可以根据具体业务需求,灵活配置各种判定规则,提高系统的灵活性和可维护性。
六、优化建议
- 性能优化:递归处理在规则树层级较深时可能存在性能问题,可以考虑使用迭代方式替代递归
- 事务管理:在批量保存规则节点时,建议添加事务管理,确保数据一致性
- 缓存机制:对于频繁使用的规则配置,可以添加缓存机制,减少数据库查询
- 规则验证:在保存规则前添加更严格的验证逻辑,确保规则配置的合法性
// 优化建议:添加事务管理
@transactional(rollbackfor = exception.class)
public integer savenode(list<rulenodedto> judgegroup, string rulegroupid, list<monruledefinitions> ruledefinitions) {
// ... 原有代码
}
通过以上优化,可以进一步提高规则引擎的性能和可靠性。
到此这篇关于基于java实现的简易规则引擎的文章就介绍到这了,更多相关java 规则引擎内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论