引言:数据结构的艺术
在python的编程世界中,数据结构犹如画家手中的调色板,而列表(list)和数组(array)则是其中最常用的两种"颜色"。它们看似相似,实则各具特色。本文将带您深入探索这两种数据结构的奥秘,助您在编程实践中做出明智选择。
第一章:python列表 - 灵活多变的瑞士军刀
1.1 列表的本质与特性
python列表是有序、可变的序列容器,它像是一个万能收纳盒,可以容纳各种类型的数据:
my_list = [42, "python", 3.14, true, [1, 2, 3]] # 整数、字符串、浮点数、布尔值、甚至另一个列表
核心特性总结表:
| 特性 | 说明 | 示例 |
|---|---|---|
| 动态大小 | 可随时增删元素 | my_list.append(10) |
| 异构存储 | 可混合存储不同类型 | [1, "a", 3.14, true] |
| 丰富操作 | 提供多种内置方法 | sort(), reverse()等 |
| 索引切片 | 支持灵活的位置访问 | my_list[1:4:2] |
1.2 列表的底层实现
python列表实际上是一个动态数组,其内存分配策略非常智能:
- 初始分配一定容量
- 当空间不足时,自动扩容(通常是当前大小的约1.125倍)
- 扩容时复制原有元素到新空间
1.3 列表的实用案例
案例:学生成绩管理系统
# 初始化学生列表
students = [
{"name": "alice", "scores": [85, 90, 88]},
{"name": "bob", "scores": [78, 82, 80]},
{"name": "charlie", "scores": [92, 95, 89]}
]
# 添加新学生
students.append({"name": "david", "scores": [80, 85, 90]})
# 计算平均分
for student in students:
avg_score = sum(student["scores"]) / len(student["scores"])
print(f"{student['name']}的平均分: {avg_score:.2f}")
第二章:python数组 - 专注数值计算的利器
2.1 数组的引入与特点
虽然python内置了列表,但在处理大规模数值数据时,我们通常需要更高效的解决方案。这时就需要array模块或numpy数组:
import array
# 创建一个整数数组
int_array = array.array('i', [1, 2, 3, 4, 5]) # 'i'表示整数类型
数组类型代码表:
| 类型码 | c类型 | python类型 | 最小字节数 |
|---|---|---|---|
| ‘b’ | signed char | int | 1 |
| ‘b’ | unsigned char | int | 1 |
| ‘i’ | signed int | int | 2 |
| ‘i’ | unsigned int | int | 2 |
| ‘f’ | float | float | 4 |
| ‘d’ | double | float | 8 |
2.2 numpy数组的威力
对于科学计算,numpy数组是更强大的选择:
import numpy as np # 创建numpy数组 np_array = np.array([1, 2, 3, 4, 5], dtype=np.float32) # 向量化运算 squared = np_array ** 2 # 对每个元素平方
numpy优势对比:
| 特性 | 普通列表 | numpy数组 |
|---|---|---|
| 存储效率 | 较低 | 高(连续内存) |
| 运算速度 | 慢(逐元素处理) | 快(向量化操作) |
| 多维支持 | 有限 | 完善 |
| 功能丰富度 | 基础 | 强大(线性代数等) |
渲染错误: mermaid 渲染失败: parsing failed: unexpected character: ->m<- at offset: 50, skipped 2 characters. unexpected character: ->m<- at offset: 70, skipped 2 characters.
2.3 数组应用案例
案例:信号处理
import numpy as np
import matplotlib.pyplot as plt
# 生成正弦波信号
t = np.linspace(0, 1, 1000) # 1秒内1000个点
frequency = 5 # 5hz
signal = np.sin(2 * np.pi * frequency * t)
# 添加噪声
noise = np.random.normal(0, 0.1, 1000)
noisy_signal = signal + noise
# 绘制信号
plt.plot(t, noisy_signal)
plt.title("带噪声的正弦波信号")
plt.xlabel("时间(s)")
plt.ylabel("幅度")
plt.show()
第三章:对比与选择 - 找到最适合的工具
3.1 关键差异总结
性能对比表:
| 维度 | 列表(list) | 数组(array/numpy) |
|---|---|---|
| 数据类型 | 任意python对象(异构) | 单一类型(同构) |
| 内存效率 | 较低(存储类型信息等额外数据) | 高(连续内存,紧凑存储) |
| 访问速度 | 较慢 | 较快(特别是numpy) |
| 功能方法 | 丰富的通用操作方法 | 专注于数值计算的优化方法 |
| 适用场景 | 通用数据存储和操作 | 大规模数值计算和科学计算 |
3.2 选择指南
决策流程图:
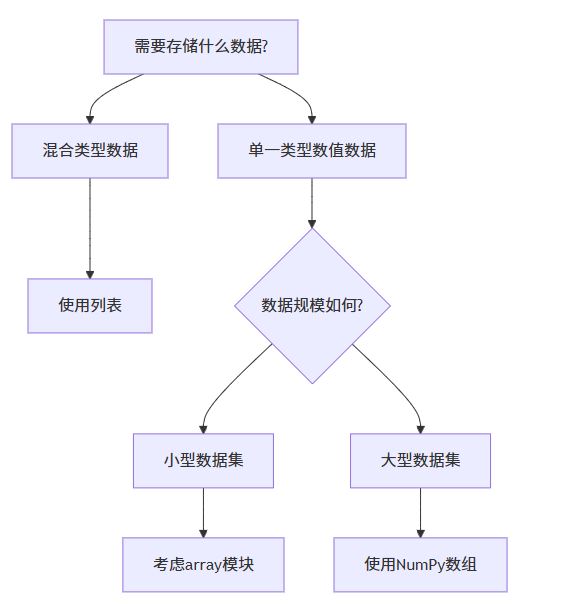
具体建议:
选择列表当:
- 需要存储不同类型的数据
- 需要频繁插入删除元素
- 数据量不大,不需要高性能计算
- 使用python内置方法足够
选择数组当:
- 处理纯数值数据
- 数据规模大(数万元素以上)
- 需要高性能数学运算
- 需要内存效率
- 使用科学计算库(如numpy、pandas)
3.3 性能实测对比
让我们通过一个简单的例子比较两者的计算效率:
import timeit
import array
import numpy as np
# 准备数据
list_data = [float(i) for i in range(1000000)]
arr_data = array.array('d', list_data)
np_data = np.array(list_data)
# 测试平方运算
def test_list():
return [x**2 for x in list_data]
def test_array():
return array.array('d', [x**2 for x in arr_data])
def test_numpy():
return np_data ** 2
# 计时
print("列表耗时:", timeit.timeit(test_list, number=10))
print("数组耗时:", timeit.timeit(test_array, number=10))
print("numpy耗时:", timeit.timeit(test_numpy, number=10))
典型结果:
- 列表:约2.5秒
- array模块:约2.3秒
- numpy:约0.05秒
第四章:进阶技巧与最佳实践
4.1 混合使用策略
在实际项目中,我们经常组合使用列表和数组:
import numpy as np
# 使用列表收集异构数据
raw_data = [
{"sensor": "a", "readings": [23.4, 24.1, 22.9]},
{"sensor": "b", "readings": [19.8, 20.2, 21.0]}
]
# 转换为numpy数组进行批量计算
all_readings = np.array([item["readings"] for item in raw_data])
mean_readings = np.mean(all_readings, axis=1)
# 将结果存回字典
for i, item in enumerate(raw_data):
item["mean"] = mean_readings[i]
4.2 内存优化技巧
对于大型数据集,内存管理至关重要:
选择合适的数据类型:
# 使用最小够用的数据类型 small_ints = np.array([1, 2, 3], dtype=np.int8) # 1字节/元素
视图而非复制:
big_array = np.random.rand(10000, 10000) subset = big_array[100:200, 100:200] # 创建视图,不复制数据
使用内存映射:
# 处理超大文件
mmap_arr = np.memmap('large_array.npy', dtype='float32', mode='r', shape=(1000000,))
4.3 并行计算加速
numpy可与多线程库结合实现加速:
import numpy as np
from multiprocessing import pool
def process_chunk(data_chunk):
return np.sum(data_chunk ** 2)
# 分块处理大数据
big_data = np.random.rand(10000000)
chunks = np.array_split(big_data, 8) # 分为8块
with pool(8) as p:
results = p.map(process_chunk, chunks)
total = sum(results)
结语:明智选择,高效编程
python的列表和数组就像工具箱中的不同工具——没有绝对的"最好",只有最适合特定任务的。理解它们的本质差异和适用场景,能让您的代码既优雅又高效。
记住这些黄金法则:
- 灵活性 vs 性能:列表灵活,数组高效
- 开发速度 vs 运行速度:原型开发用列表,生产环境考虑数组
- 通用性 vs 专业性:日常任务用列表,专业计算用数组
以上就是python列表和数组的深入解析与最佳选择指南的详细内容,更多关于python列表和数组解析的资料请关注代码网其它相关文章!






发表评论