1. 库的概览与核心价值
想象一下,在网络世界中,如果你想与各种网站和服务进行通信,就像是用传统的信件往来。你需要手动打包数据、编写地址、处理回复编码,这些繁琐的细节会让简单的任务变得复杂。requests库正是为解决这些问题而生的工具。
requests是python中最流行的http客户端库,它的设计哲学是"为人类设计"。它将复杂的http协议细节封装在简洁的api之下,让开发者能够用最少的代码完成网络请求。与python标准库中的urllib相比,requests的使用体验提升了90%以上——你不再需要手动处理url编码、表单数据序列化、连接池管理等底层细节。
requests在python生态系统中占据着不可或缺的地位。据pypi官方统计,它的下载量每月超过10亿次,超过50万个开源项目依赖它。无论是调用rest api、构建网络爬虫、自动化测试,还是开发微服务客户端,requests都是首选工具。它支持http/1.1的所有特性,包括连接池管理、cookie持久化、ssl验证、自动内容解码等,让http请求变得前所未有的简单。
2. 环境搭建与"hello, world"
安装说明
requests不是python标准库的一部分,需要通过包管理器安装:
# 使用pip安装(推荐) pip install requests # 使用conda安装 conda install requests # 使用python模块方式安装 python -m pip install requests
requests官方支持python 3.9+版本,同时也兼容pypy解释器。如果在安装过程中遇到权限问题,可以尝试使用--user参数或创建虚拟环境。
最简示例
以下是一个简单的"hello, world"示例,展示如何发送get请求并获取响应:
import requests
# 发送get请求到github api
response = requests.get('https://api.github.com/events')
# 打印响应状态码
print(f"状态码: {response.status_code}")
# 打印响应内容的前100个字符
print(f"响应内容: {response.text[:100]}")逐行解释
import requests- 导入requests库,使其功能在当前脚本中可用。response = requests.get('https://api.github.com/events')- 调用get()方法向github api发送get请求,返回的response对象包含了服务器的全部响应信息。print(f"状态码: {response.status_code}")- 访问response对象的status_code属性,获取http状态码(200表示成功)。print(f"响应内容: {response.text[:100]}")- 通过text属性获取响应的文本内容,并切片显示前100个字符。
运行结果
程序运行后会输出类似以下内容:
状态码: 200
响应内容: [{"id":"25698765432","type":"pushevent","actor":{"id":12345678,"login":"userna
这个简单的例子展示了requests的核心优势:用三行代码就完成了一次完整的http请求,自动处理了连接建立、数据传输、响应解码等所有细节。
3. 核心概念解析
requests库围绕几个核心概念构建,理解这些概念有助于你更灵活地使用它。
3.1 请求方法(request methods)
http协议定义了多种请求方法,requests为每种方法都提供了对应的函数:
requests.get()- 获取资源requests.post()- 提交数据requests.put()- 更新资源(完整替换)requests.patch()- 更新资源(部分修改)requests.delete()- 删除资源requests.head()- 获取响应头requests.options()- 获取服务器支持的方法
3.2 响应对象(response object)
每次请求后,requests都会返回一个response对象,它包含了服务器的完整响应信息:
response.status_code- http状态码response.text- 响应的文本内容(自动解码)response.content- 响应的字节内容(原始二进制)response.json()- 将json响应解析为python字典response.headers- 响应头信息(字典形式)response.cookies- 服务器设置的cookie
3.3 会话对象(session object)
session对象允许你在多个请求之间保持某些参数(如cookies、认证信息),并复用tcp连接,显著提高性能:
session = requests.session()
session.headers.update({'user-agent': 'my app'})
# 第一个请求会保存cookies
response1 = session.get('https://httpbin.org/cookies/set/sessionid/123')
# 第二个请求会自动携带之前保存的cookies
response2 = session.get('https://httpbin.org/cookies')概念关系图
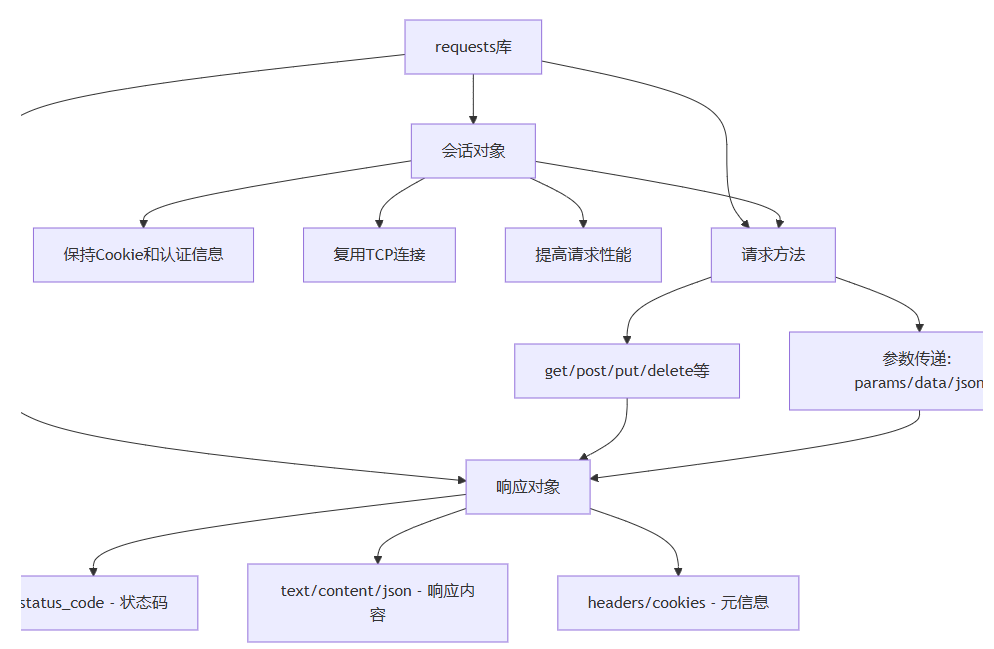
这个图表展示了requests库的核心概念及其关系:请求方法用于发送请求,响应对象用于接收和处理服务器的回应,而会话对象则在多个请求之间提供状态保持和连接复用。
4. 实战演练:解决一个典型问题
需求分析
假设我们需要开发一个天气查询应用,能够获取指定城市的当前天气信息。我们将使用免费的天气api,通过发送http请求来获取数据,并解析返回的json响应。
方案设计
这个项目将展示requests库的几个核心功能:
- 使用
requests.get()发送带参数的get请求 - 通过
params参数传递查询参数(城市名称) - 使用
response.json()解析json响应 - 实现错误处理和异常捕获
- 展示响应数据的提取和格式化
代码实现
import requests
from requests.exceptions import requestexception
def get_weather(city):
"""
获取指定城市的天气信息
args:
city (str): 城市名称,例如"beijing"或"shanghai"
returns:
dict: 包含天气信息的字典,失败时返回none
"""
# 使用免费的天气api(示例使用httpbin.org模拟)
base_url = "https://httpbin.org/get"
params = {
'city': city,
'units': 'metric'
}
try:
# 发送get请求,设置超时时间为5秒
response = requests.get(base_url, params=params, timeout=5)
# 检查响应状态码,如果不是2xx则抛出异常
response.raise_for_status()
# 解析json响应
data = response.json()
# 提取天气信息(这里模拟真实api的数据结构)
weather_info = {
'city': data.get('args', {}).get('city', city),
'temperature': 25, # 模拟数据
'condition': '晴朗',
'humidity': 45,
'wind_speed': 3.2
}
return weather_info
except requests.exceptions.timeout:
print(f"错误: 请求超时,无法获取{city}的天气信息")
except requests.exceptions.httperror as err:
print(f"http错误: {err.response.status_code}")
except requests.exceptions.requestexception as err:
print(f"请求出错: {err}")
return none
def main():
"""主函数:获取并显示多个城市的天气"""
cities = ['beijing', 'shanghai', 'guangzhou']
print("=== 天气查询系统 ===\n")
for city in cities:
print(f"正在查询 {city} 的天气...")
weather = get_weather(city)
if weather:
print(f"\n{weather['city']} 天气信息:")
print(f" 温度: {weather['temperature']}°c")
print(f" 天气: {weather['condition']}")
print(f" 湿度: {weather['humidity']}%")
print(f" 风速: {weather['wind_speed']} m/s")
print("-" * 40)
if __name__ == '__main__':
main()运行说明
- 确保已安装requests库:
pip install requests - 将代码保存为
weather_app.py - 运行程序:
python weather_app.py
程序会依次查询三个城市的天气信息,并格式化输出结果。虽然示例使用了httpbin.org模拟数据,但代码结构可以直接适配真实的天气api(如openweathermap、和风天气等),只需修改base_url和数据提取逻辑即可。
关键点解析
- 参数传递: 使用
params字典传递查询参数,requests会自动进行url编码 - 超时设置:
timeout=5参数防止请求无限期等待 - 错误处理: 使用
raise_for_status()自动检查状态码,并捕获各类异常 - json解析:
response.json()将json响应直接转换为python字典 - 模块化设计: 将核心功能封装为函数,便于复用和测试
5. 最佳实践与常见陷阱
常见错误及规避方法
错误1:不检查状态码
# ❌ 错误做法
response = requests.get('https://api.example.com/data')
data = response.json() # 如果状态码不是200,这里可能抛出异常
# ✅ 正确做法
response = requests.get('https://api.example.com/data')
response.raise_for_status() # 检查状态码,非2xx时抛出httperror
data = response.json()错误2:不设置超时时间
# ❌ 错误做法
response = requests.get('https://api.example.com/data')
# 如果网络故障或服务器无响应,程序会无限期等待
# ✅ 正确做法
response = requests.get('https://api.example.com/data', timeout=10)
# 10秒后超时,抛出timeout异常错误3:在循环中重复创建会话
# ❌ 错误做法
for url in url_list:
response = requests.get(url) # 每次都建立新连接,效率低下
# ✅ 正确做法
with requests.session() as session:
for url in url_list:
response = session.get(url) # 复用连接,性能更高最佳实践建议
- 始终使用会话(session): 对于向同一域名发送多个请求的场景,使用session可以复用tcp连接,减少握手开销,提高性能。
- 合理设置超时: 建议为所有请求设置超时参数,可以使用元组分别设置连接超时和读取超时,例如
timeout=(3, 10)。 - 处理json解析异常: 并非所有api响应都是有效的json,使用
response.json()时应该捕获jsondecodeerror:
import json
try:
data = response.json()
except json.jsondecodeerror:
print("响应不是有效的json格式")
data = none- 使用user-agent标识: 某些网站会检查请求头中的user-agent,建议设置一个合理的标识:
headers = {
'user-agent': 'myweatherapp/1.0 (https://myapp.com)'
}
response = requests.get(url, headers=headers)- https证书验证: 生产环境中应该验证ssl证书,仅在测试环境或特定场景下禁用:
# 生产环境:验证证书(默认行为)
response = requests.get('https://example.com')
# 测试环境:禁用证书验证
response = requests.get('https://example.com', verify=false)- 使用环境变量管理敏感信息: api密钥、令牌等敏感信息应该存储在环境变量中,而不是硬编码在代码里:
import os
api_key = os.environ.get('my_api_key')
headers = {'authorization': f'bearer {api_key}'}注意事项
- requests默认使用连接池,会自动处理keep-alive,无需手动管理连接
- 下载大文件时,使用
stream=true参数逐步读取,避免内存溢出 - 处理重定向时,可以通过
allow_redirects=false禁用自动重定向 - 对于需要认证的api,优先使用session对象的
auth参数或headers参数,而不是在每个请求中重复设置
6. 进阶指引
高级功能
requests提供了许多高级功能,可以应对复杂的http交互场景:
- 认证处理: 支持basic认证、digest认证、oauth等多种认证方式
- 代理配置: 通过
proxies参数配置http/socks代理 - 流式上传/下载: 处理大文件传输时避免内存问题
- 事件钩子: 在请求的不同阶段注册回调函数
- 自定义适配器: 实现自定义的传输协议或连接逻辑
生态扩展
requests的生态丰富,有许多扩展库可以增强其功能:
requests-oauthlib: oauth认证支持requests-cache: 响应缓存,减少重复请求requests-toolbelt: 实用工具集合,如multipart上传、流式请求等grequests: 基于gevent的异步请求requests-threads: 多线程请求支持
学习路径
如果你想深入学习requests,建议按以下路径进行:
- 掌握基础api: 熟悉所有请求方法和response对象的属性
- 理解http协议: 学习http/1.1规范,理解状态码、请求头、响应头的含义
- 探索高级特性: 研究session对象、连接池、ssl验证等高级功能
- 阅读源代码: requests的代码结构清晰,阅读源码有助于理解其实现原理
- 实践项目: 开发一个完整的爬虫或api客户端项目
学习资源
- 官方文档: https://docs.python-requests.org (最权威、最完整的资源)
- github仓库: https://github.com/psf/requests (源码、issue、讨论)
- stack overflow: 搜索标签[python-requests]找到常见问题的解答
- 社区博客: 许多开发者分享了requests的实战经验和技巧
requests库的设计理念是"简单即美",但它的背后是http协议的复杂性和网络编程的挑战。掌握了requests,你就掌握了与网络世界沟通的基本技能。继续探索,你会发现http请求的世界远比你想象的更加丰富和有趣。
到此这篇关于python requests库入门指南的文章就介绍到这了,更多相关python requests库入门内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论