一、回答重点
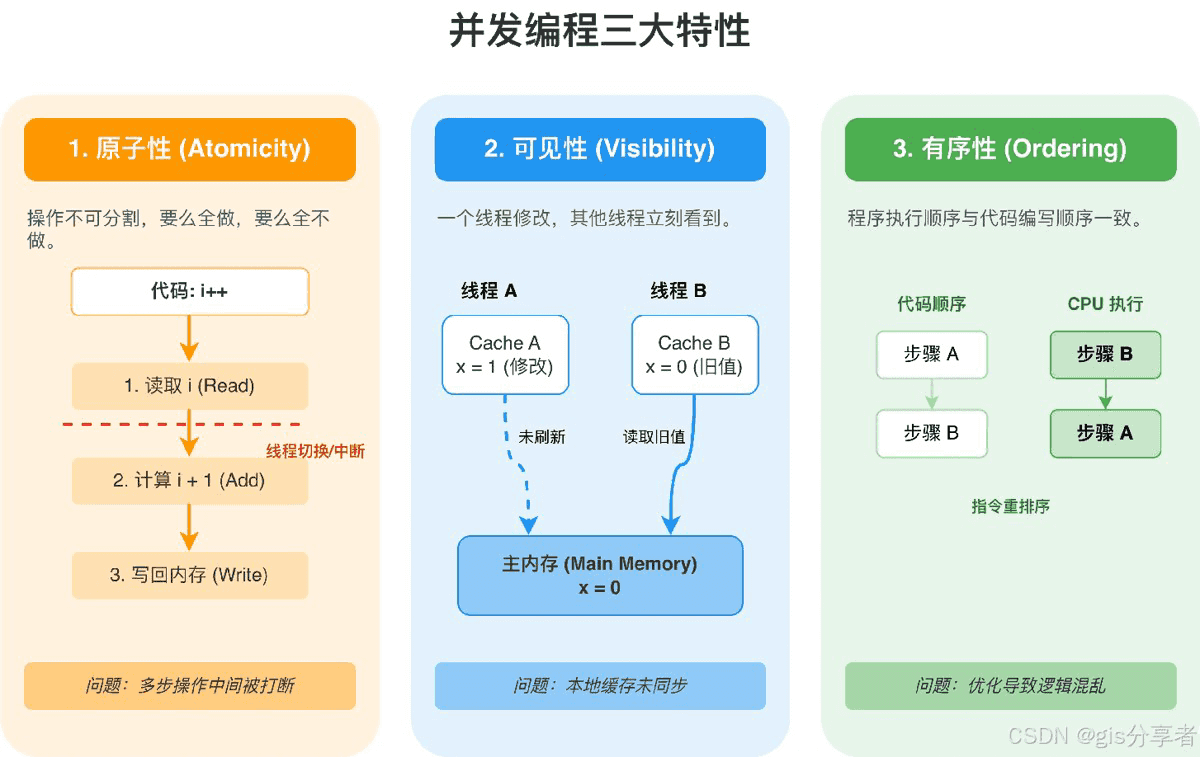
原子性、可见性、有序性是 java 并发编程的三大核心特性,任何并发 bug 基本都能归到这三类里面。

1 原子性
原子性指一个操作要么全部执行完,要么压根没执行,中间不会被其他线程打断。比如 i++ 这个操作看着像一行代码,实际上是读取、加 1、写回三个步骤,多线程环境下就可能出问题。
2 可见性
可见性指一个线程修改了共享变量,其他线程能立刻看到最新值。cpu 有自己的高速缓存,线程修改的值可能还躺在缓存里没刷回主内存,别的线程就读到了旧值。
3 有序性
有序性指程序执行顺序和代码写的顺序一致。编译器和 cpu 为了性能会对指令做重排序,单线程下没问题,多线程就可能出现诡异的 bug。
下面用一个经典的例子演示这三个问题是怎么搞出 bug 的:
public class singleton {
private static singleton instance;
public static singleton getinstance() {
if (instance == null) { // 第一次检查
synchronized (singleton.class) {
if (instance == null) { // 第二次检查
instance = new singleton(); // 问题就出在这
}
}
}
return instance;
}
}
这段双重检查锁定看起来没毛病,但 instance = new singleton() 这行代码实际上分三步:分配内存空间、初始化对象、把引用指向内存地址。cpu 可能把第 2 步和第 3 步重排序,导致另一个线程拿到一个还没初始化完的对象,直接空指针。解决办法就是给 instance 加上 volatile。
二、扩展知识
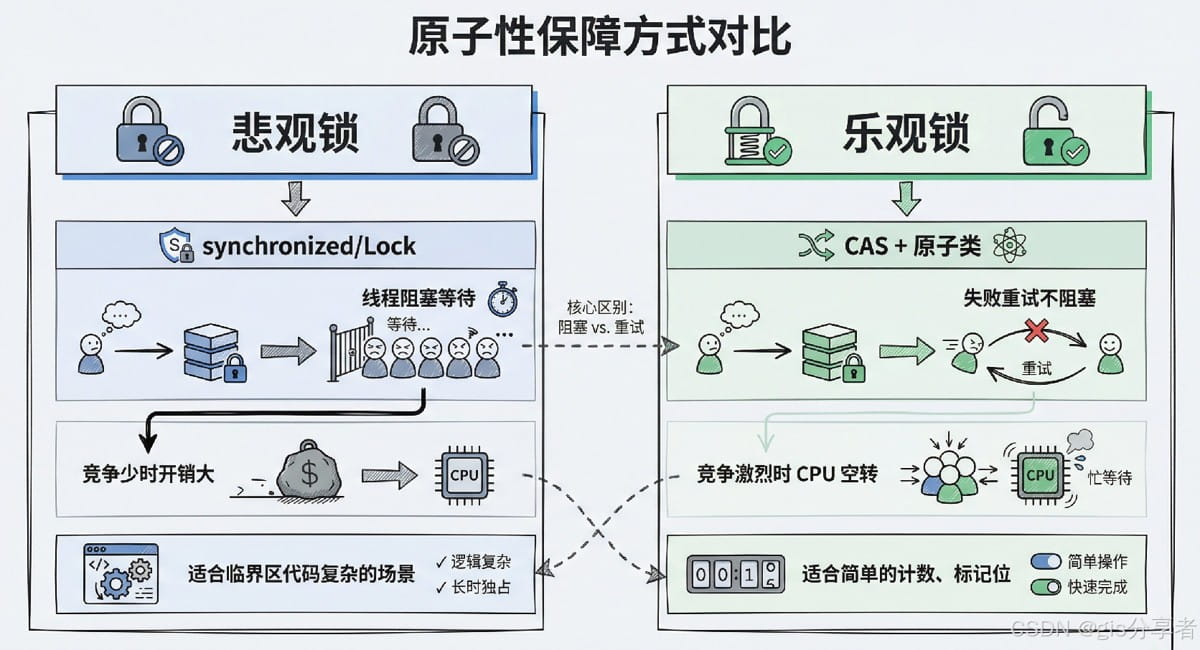
1. 原子性的保障手段
java 里保证原子性主要靠两种方式:锁和 cas。
synchronized 和 lock 是最直接的手段,进入临界区的线程独占资源,其他线程只能干等着。但锁的开销不小,线程切换、阻塞唤醒都是重量级操作。
cas 是一种乐观锁思路,底层依赖 cpu 的 cmpxchg 指令。比如 atomicinteger 的 incrementandget,它会不断尝试"比较当前值是否等于预期值,等于就更新",失败就重试。cas 避免了线程阻塞,但在竞争激烈时会疯狂自旋,cpu 空转。
// atomicinteger 的自增底层就是 cas atomicinteger count = new atomicinteger(0); count.incrementandget(); // 内部循环 cas 直到成功
jdk 8 引入了 longadder,思路是把一个变量拆成多个 cell,不同线程操作不同的 cell,最后汇总。高并发场景下比 atomiclong 快很多,elasticsearch 的计数器就用的这种方案。
2. 可见性的底层原理
可见性问题的根源在于 cpu 缓存。现代 cpu 都有 l1、l2、l3 多级缓存,每个核心有自己的 l1/l2,线程读写变量时优先操作缓存。如果线程 a 在 cpu0 上改了变量,值还在 l1 缓存里,线程 b 在 cpu1 上读的还是旧值。
volatile 的作用就是强制刷新缓存。写 volatile 变量时,jvm 会插入 storestore 屏障和 storeload 屏障,把缓存里的数据刷回主内存;读 volatile 变量时,会插入 loadload 屏障和 loadstore 屏障,强制从主内存读取。
synchronized 也能保证可见性。线程退出 synchronized 块时,会把所有修改刷回主内存;进入 synchronized 块时,会清空本地缓存,强制从主内存重新加载。所以 synchronized 块里的代码不需要额外加 volatile。
final 字段也有可见性保证。jvm 保证对象构造完成后,final 字段的值对其他线程可见,不需要额外同步。这就是为什么 string 的 value 数组是 final 的。
3. 有序性与指令重排
编译器和 cpu 都会做指令重排序,目的是充分利用 cpu 流水线,提高执行效率。
编译器重排是在生成字节码或机器码时调整指令顺序。比如两条不相关的赋值语句,编译器可能调换顺序来优化寄存器使用。
cpu 重排更常见,现代 cpu 都是乱序执行。cpu 会把没有数据依赖的指令并行执行,执行完再按原始顺序提交结果。单线程下完全没问题,因为 cpu 保证了 as-if-serial 语义,执行结果和顺序执行一样。
但多线程环境下,a 线程的两条指令对 a 来说没依赖,对 b 线程可能就有依赖。经典的例子是上面的双重检查锁定,对象初始化和引用赋值对构造线程没依赖,但其他线程可能在初始化完成前就拿到了引用。
jmm 定义了 happens-before 规则来约束重排序。只要操作 a happens-before 操作 b,那 a 的结果对 b 一定可见,a 的执行顺序也一定在 b 之前。
4. 三大特性的实现方式对比
优缺点对比
| 特性 | volatile | synchronized | lock | atomic |
|---|---|---|---|---|
| 原子性 | 不保证 | 保证 | 保证 | 保证 |
| 可见性 | 保证 | 保证 | 保证 | 保证 |
| 有序性 | 禁止重排序 | 临界区内有序 | 临界区内有序 | 单个操作有序 |
| 性能 | 最轻 | 中等 | 可控 | 较轻 |
| 适用场景 | 状态标记 | 临界区保护 | 需要精细控制 | 计数器 |
三、面试官追问
提问:volatile 能保证原子性吗?为什么 volatile int count 的 count++ 不是线程安全的??
回答:volatile 只保证可见性和禁止重排序,不保证原子性。count++ 实际上是读取、加 1、写回三个步骤,多个线程可能同时读到同一个值,各自加 1 后写回,结果就少加了。想要原子自增得用 atomicinteger 或者 synchronized。
提问:synchronized 和 volatile 在底层实现上有什么区别?
回答:volatile 是通过内存屏障实现的,写操作插入 storestore 和 storeload 屏障,读操作插入 loadload 和 loadstore 屏障,纯粹靠 cpu 指令保证,不涉及锁。synchronized 底层是 monitor 机制,jvm 会在对象头里记录锁状态,涉及到偏向锁、轻量级锁、重量级锁的升级过程,重量级锁要靠操作系统的互斥量,有线程切换开销。
提问:为什么双重检查锁定的单例需要加 volatile,不加会出什么问题?
回答:new 对象分三步:分配内存、初始化、引用赋值。不加 volatile 的话,cpu 可能把初始化和引用赋值重排序,另一个线程可能在第一次 null 检查时拿到一个非 null 但还没初始化完的引用,直接用就空指针或者数据错乱。volatile 禁止了这种重排序。
总结
到此这篇关于java中的原子性、可见性和有序性的文章就介绍到这了,更多相关java原子性、可见性和有序性内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论