识别结果效果
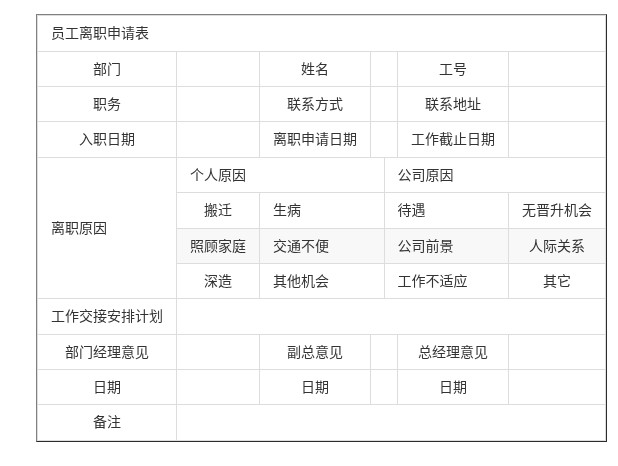
案例参考图片
一、安装系统级依赖
windows 系统
在 windows 系统下,从 python 官方网站 下载 python 3.10 版本安装包,安装时勾选 “add python to path” 选项。
linux 系统
在 linux 系统下,安装 python 3.10 及常用开发组件:
sudo apt update sudo apt install -y \ python3.10 \ python3.10-venv \ python3.10-dev \ python3.10-distutils \ python3-pip
这些组件分别用于:
python3.10:python 解释器venv:虚拟环境支持dev / distutils:编译与打包依赖pip:python 包管理工具
二、创建并激活虚拟环境
1. 创建虚拟环境
python -m venv paddle_py10
2. 激活虚拟环境
windows 系统
paddle_py10\\scripts\\activate
linux 系统
source paddle_py10/bin/activate
激活成功后,终端前会显示:
(paddle_py10)
三、安装 paddlepaddle(cpu 版本)
在虚拟环境中安装 paddlepaddle cpu 版(适用于 windows 和 linux):
python -m pip install paddlepaddle -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
说明:
- 使用官方国内镜像,下载速度更快
- 该版本适合 无 gpu / cpu 推理环境
- 自动检测操作系统并安装相应版本
四、安装 pdf 相关依赖
1. 安装 pymupdf(pdf 解析)
pip install pymupdf
主要用于:
- pdf 页面解析
- 文本 / 图片提取
- pdf 转图片(ocr 前处理)
2. 安装 paddlex(含 ocr 模块)
pip install "paddlex[ocr]"
功能包括:
- ocr 模型封装
- 文本检测 / 识别
- 表格与版面分析
3. 安装 reportlab(pdf 生成)
pip install reportlab
完整代码
from paddleocr import paddleocrvl
from pil import image
import numpy as np
pipeline = paddleocrvl(
device="cpu"
)
img = image.open(
"v2-f644e32ef8fb2b15b6dd7218eff5f844_r.jpg"
).convert("rgb")
# resize
max_side = 1024
w, h = img.size
scale = min(max_side / w, max_side / h, 1.0)
img = img.resize((int(w * scale), int(h * scale)))
# 重要一步:pil → numpy (防止cpu超过内存)
img_np = np.array(img)
output = pipeline.predict(img_np)
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
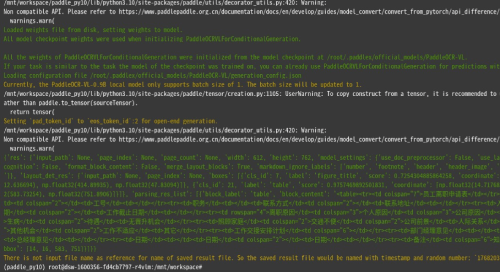
输出目录示例(windows)
(paddle_py10) c:\workspace\output> dir
1768203146_1313.md
1768203146_1313_res.json
输出目录示例(linux)
(paddle_py10) user@machine:/home/user/workspace/output$ tree
├── 1768203146_1313.md
└── 1768203146_1313_res.json
0 directories, 4 files
转pdf和word请参考相关文章参考:
到此这篇关于windows和linux下使用python搭建一个图片ocr工具的文章就介绍到这了,更多相关python图片ocr内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论