一、快速排查流程
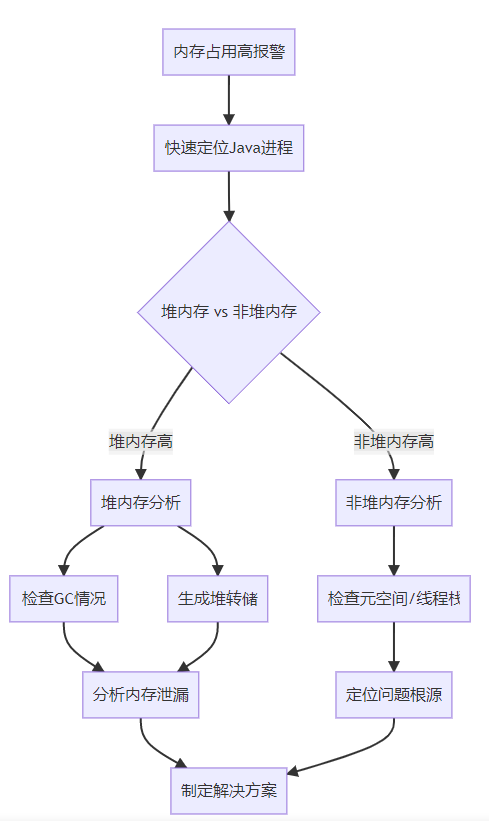
二、详细排查步骤与命令
步骤1:快速定位问题进程
# 1. 查看系统整体内存使用 free -h # 查看系统整体内存 free -h && echo "---" && top -bn1 | head -10 top -p <java_pid> # 2. 查找java进程内存排名 ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head -20 # 定位java进程内存排名 ps -eo pid,ppid,cmd,%mem,rss --sort=-rss | head -15 # 查看java进程列表 jps -mlv | grep -v jps # 或者使用更专业的工具 nmon -s1 -c10 # 3. 确认java进程基本信息 jps -mlv jcmd -l
步骤2:分析jvm内存分布
# 1. 查看堆内存详细分布 jhsdb jmap --heap --pid <pid> jhsdb jmap --heap --pid $pid 2>/dev/null || jmap -heap $pid # 2. 实时监控gc和内存使用 jstat -gcutil <pid> 1000 10 jstat -gccapacity <pid> 1000 5 # 3. 查看内存各区域使用详情 jcmd <pid> vm.native_memory summary scale=mb jcmd $pid vm.native_memory summary scale=mb # 检查大对象分布 jmap -histo:live $pid | sort -k3 -nr | head -30 > large_objects.txt
关键指标解读:
ou(old utilization):老年代使用率 >80% 需关注mu(metaspace utilization):元空间使用率ccs(compressed class space):压缩类空间
步骤3:生成和分析堆转储
# 1. 生成堆转储文件(生产环境谨慎使用) jmap -dump:live,format=b,file=heap_dump.hprof <pid> # 2. 如果jmap不可用,使用jcmd(推荐) jcmd <pid> gc.heap_dump filename=heap_dump.hprof jcmd $pid gc.heap_dump filename=heap_$(date +%y%m%d_%h%m%s).hprof # 3. 仅统计对象数量(不影响服务) jmap -histo:live <pid> | head -50 > object_histo.txt # 仅生成直方图(生产环境安全) jmap -histo $pid > object_histogram.tx
步骤4:分析堆转储文件
使用eclipse mat分析
# 下载mat:https://www.eclipse.org/mat/ # 分析步骤: 1. file → open heap dump 2. 查看leak suspects report 3. 分析dominator tree 4. 查看重复字符串/集合大小
使用命令行快速分析
# 分析大对象 jhat heap_dump.hprof # 访问 http://localhost:7000 查看分析结果 # 或者使用jhiccup java -jar jhiccup.jar -p <pid>
步骤5:检查非堆内存
# 1. 检查元空间使用 jstat -gcmetacapacity <pid> # 2. 检查线程数量 ps -elf | grep <pid> | wc -l jstack <pid> | grep "java.lang.thread.state" | wc -l jstack $pid | grep "java.lang.thread.state" | sort | uniq -c > thread_states.txt # 3. 检查直接内存 jcmd <pid> vm.native_memory detail | grep -a10 "internal" # 类加载统计 jcmd $pid vm.classloader_stats 2>/dev/null # 4. 检查代码缓存 jstat -gccapacity <pid> | grep -i code
三、具体场景排查命令
场景1:堆内存泄漏排查
# 1. 实时监控对象创建 jstat -gcutil <pid> 1s # 2. 跟踪gc日志(如果已开启) tail -f /path/to/gc.log # 实时查看gc情况 tail -f /path/to/gc.log | grep -e "full gc|gc.*pause" # 使用分析工具(需要下载gcviewer) java -jar gcviewer.jar /path/to/gc.log # 3. 检查大对象 jmap -histo <pid> | sort -k3 -nr | head -20 # 4. 检查finalizer队列 jcmd <pid> gc.finalizer_info
场景2:元空间溢出排查
# 1. 监控元空间增长 while true; do jstat -gcmetacapacity <pid>; sleep 2; done # 2. 检查类加载器 jcmd <pid> vm.classloader_stats # 3. 检查加载的类数量 jmap -clstats <pid> # 4. 查找重复类 java -jar jarpath/classloader-analyzer.jar --pid <pid>
场景3:线程内存泄漏排查
# 1. 生成线程转储 jstack <pid> > thread_dump.txt # 2. 统计线程状态 grep "java.lang.thread.state" thread_dump.txt | sort | uniq -c # 3. 检查线程栈大小 jinfo <pid> | grep -i stack # 4. 分析线程创建轨迹(如果有arthas) thread -n 10
场景4:直接内存泄漏排查
# 1. 检查nio直接内存 jcmd <pid> vm.native_memory summary | grep -a5 "native memory tracking" # 2. 监控堆外内存使用 pmap -x <pid> | sort -k3 -nr | head -10 # 3. 如果怀疑netty等框架的内存泄漏 # 添加jvm参数:-xx:maxdirectmemorysize=512m
四、使用arthas进行在线诊断
# 安装并启动arthas
curl -o https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
# 内存诊断命令
dashboard # 整体监控面板
memory # 内存详情
heapdump --live /tmp/heap.hprof # 在线堆转储
# 类加载监控
classloader -t # 类加载器树
sc -d <classname> # 查看类详情
# 方法级监控
monitor -c 5 com.example.service methodname # 方法执行统计
watch com.example.service methodname "{params,returnobj}" -x 3 # 观察方法参数
五、容器环境特殊排查
# 1. 进入容器 docker exec -it <container_id> /bin/bash # 2. 检查容器内存限制 cat /sys/fs/cgroup/memory/memory.limit_in_bytes cat /sys/fs/cgroup/memory/memory.usage_in_bytes # 3. 调整jvm内存参数(如果设置不合理) # 在启动参数中添加: -xx:+usecontainersupport -xx:maxrampercentage=75.0 # 4. 检查oom killer日志 dmesg | grep -i "killed process" grep -i "oom" /var/log/messages
六、自动化监控脚本
内存监控脚本
#!/bin/bash
pid=$1
log_file="memory_monitor_${pid}.log"
while true; do
timestamp=$(date '+%y-%m-%d %h:%m:%s')
# 收集内存指标
heap_info=$(jstat -gcutil $pid 2>/dev/null | tail -1)
thread_count=$(ps -elf | grep $pid | wc -l)
echo "$timestamp | $heap_info | threads: $thread_count" >> $log_file
sleep 30
done
快速排查一键脚本
#!/bin/bash pid=$1 echo "=== 内存问题快速排查 ===" echo "1. 进程信息:" jps -mlv | grep $pid echo -e "\n2. 内存分布:" jstat -gcutil $pid echo -e "\n3. 对象统计:" jmap -histo $pid | head -30 echo -e "\n4. 线程统计:" jstack $pid | grep "java.lang.thread.state" | sort | uniq -c
七、常见问题模式与解决方案
模式1:缓存无限增长
症状: old区持续增长,full gc后很快又满
解决:
- 检查缓存失效策略
- 添加缓存大小限制
- 使用weakreference/softreference
模式2:资源未关闭
症状: 直接内存或文件描述符泄漏
解决:
- 使用try-with-resources
- 检查数据库连接池配置
- 监控文件描述符数量
模式3:类加载器泄漏
症状: 元空间持续增长,频繁full gc
解决:
- 检查热部署/动态类生成
- 分析类加载器引用链
- 重启应用服务
模式4:大对象分配
症状: 年轻代gc频繁,对象直接进入老年代
解决:
- 调整-xx:pretenuresizethreshold
- 优化大对象使用模式
- 增加年轻代大小
根据症状快速定位问题
| 症状 | 可能原因 | 排查命令 |
|---|---|---|
| old区持续增长 | 内存泄漏、缓存问题 | jmap -histo:live, mat分析 |
| 频繁full gc | 内存不足、元空间满 | jstat -gcutil, 检查metaspace |
| young gc频繁 | 新生代过小、短命对象多 | 调整-xx:newsize, 检查代码 |
| 元空间增长 | 类加载器泄漏、动态类生成 | jcmd vm.classloader_stats |
| 线程数暴涨 | 线程池配置问题、阻塞 | jstack, 线程dump分析 |
| 堆外内存高 | nio directbuffer、jni | jcmd vm.native_memory |
八、预防措施
# 1. 添加必要的jvm参数 -xx:+heapdumponoutofmemoryerror -xx:heapdumppath=/path/to/dumps -xx:errorfile=/path/to/hs_err_pid%p.log -xlog:gc*,gc+age=debug:file=/path/to/gc.log # 2. 设置合理的内存限制 -xx:maxmetaspacesize=512m -xx:reservedcodecachesize=256m -xss256k # 3. 监控告警配置 # 关键指标:堆使用率 >80%,full gc频率,元空间增长
总结
到此这篇关于java线上问题排查之内存占用大解决步骤的文章就介绍到这了,更多相关java内存占用大内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论