pandas 索引器 loc 和 iloc 比较及代码示例
以下是针对 pandas 中 loc 和 iloc 的深度对比分析及代码示例,结合核心差异、使用场景和底层机制展开说明:
一、核心差异解析
| 特性 | loc (标签索引) | iloc (位置索引) |
|---|---|---|
| 索引类型 | 行/列标签(字符串、日期等) | 行/列整数位置(从0开始) |
| 切片行为 | 包含结束标签(闭区间) | 不包含结束位置(左闭右开) |
| 布尔索引 | 直接支持条件表达式(更直观) | 需先生成布尔数组再操作 |
| 索引灵活性 | 支持非整数标签(如字符串索引) | 仅支持整数位置 |
二、关键场景代码示例
1. 基础索引对比
import pandas as pd
# 创建带自定义索引的dataframe
data = {"age": [25, 32, 28, 40], "city": ["北京", "上海", "广州", "深圳"]}
df = pd.dataframe(data, index=["alice", "bob", "charlie", "david"])
# loc按标签选择 → 获取bob行所有列
print(df.loc["bob"]) # 输出: age 32, city 上海
# iloc按位置选择 → 获取第1行所有列(索引0为alice)
print(df.iloc[1]) # 输出: 同上(bob行)
age 32
city 上海
name: bob, dtype: object
age 32
city 上海
name: bob, dtype: object
2. 切片行为差异
# loc切片包含结束标签 → 选择alice到charlie行 print(df.loc["alice":"charlie"]) # 输出3行数据 # iloc切片不包含结束位置 → 选择0至1行(不含索引2) print(df.iloc[0:2]) # 仅输出alice和bob行
age city
alice 25 北京
bob 32 上海
charlie 28 广州
age city
alice 25 北京
bob 32 上海
3. 布尔索引使用
# loc直接条件筛选 → 年龄>30的行 print(df.loc[df["age"] > 30]) # 输出bob和david行 # iloc需分两步 → 先生成掩码再选择 mask = df["age"] > 30 print(df.iloc[mask.values]) # 需用.values转为数组
age city
bob 32 上海
david 40 深圳
age city
bob 32 上海
david 40 深圳
4. 混合行列选择
# loc选择多列 → 所有行 + "city"列 print(df.loc[:, "city"]) # 输出城市列所有数据 # iloc选择连续列 → 所有行 + 第1列(列索引从0开始) print(df.iloc[:, 1]) # 同上(city列位置为1)
alice 北京
bob 上海
charlie 广州
david 深圳
name: city, dtype: object
alice 北京
bob 上海
charlie 广州
david 深圳
name: city, dtype: object
三、高级技巧与性能
1. 函数式索引
# loc + lambda → 筛选age为偶数的行 print(df.loc[lambda x: x["age"] % 2 == 0]) # 输出bob(32), david(40) # iloc + lambda → 筛选索引位置为奇数的行 print(df.iloc[lambda x: [i for i in range(len(x)) if i % 2 == 1]]) # 输出bob行
age city
bob 32 上海
charlie 28 广州
david 40 深圳
age city
bob 32 上海
david 40 深圳
2. 性能优化建议
- 大型数据集:优先用
iloc(整数位置计算更快) - 复杂索引:用
loc避免位置计算错误(如时间序列索引) - 混合场景:若需标签+位置混合索引,先重置索引再用
iloc
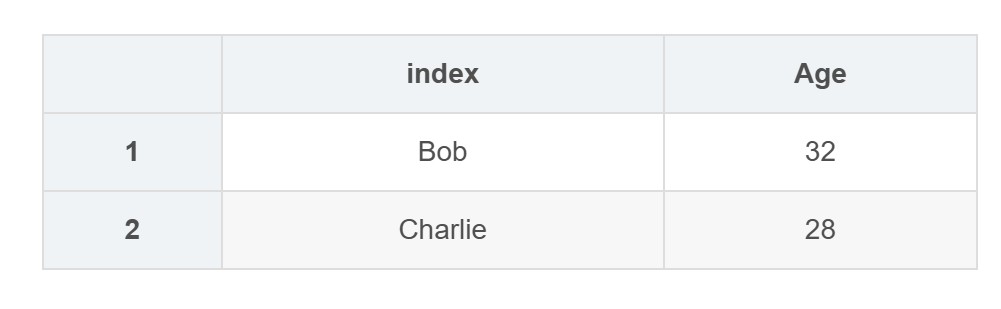
df_reset = df.reset_index() df_reset.iloc[1:3, 0:2] # 选择第1-2行,第0-1列
| index | age | |
|---|---|---|
| 1 | bob | 32 |
| 2 | charlie | 28 |
四、特殊场景处理
1. 整数索引陷阱
当行索引为整数时,loc 会优先识别为标签而非位置:
df_int_index = pd.dataframe({"value": [10, 20]}, index=[1, 2])
# loc尝试按标签访问 → 报错(无标签0)
# df_int_index.loc[0] # keyerror
# iloc按位置访问 → 正常
print(df_int_index.iloc[0]) # 输出索引1的行(value:10)
value 10
name: 1, dtype: int64
2. 负索引支持
仅 iloc 支持负数索引(从末尾计数):
print(df.iloc[-1]) # 输出最后一行(david)
age 40
city 深圳
name: david, dtype: object
五、总结:选择策略
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 已知行/列标签(如列名为"age") | loc | 直接标签访问,语义清晰 |
| 按行号/列号操作(如前三行) | iloc | 位置计算高效 |
| 时间序列数据(日期索引) | loc | 避免位置漂移(如df.loc["2023":"2025"]) |
| 大数据集遍历 | iloc | 整数位置操作速度更快 |
最佳实践:优先用 loc 保证可读性,性能敏感时切 iloc。始终通过 print(df.head()) 确认数据结构,避免索引混淆。
到此这篇关于pandas索引器 loc 和 iloc 比较及代码示例的文章就介绍到这了,更多相关pandas索引器 loc 和 iloc内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论