下面是一个完整的python gui程序,用于查看pdf文件的元数据(包括作者信息),使用tkinter作为gui框架。这个程序可以提取pdf的作者、标题、创建日期等信息。
完整代码
(有需要运行版软件的留言邮箱):
import os
import pypdf2
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
from tkinter.scrolledtext import scrolledtext
class pdfmetadataviewer:
def __init__(self, root):
self.root = root
self.root.title("pdf元数据查看器")
self.root.geometry("700x500")
self.root.configure(bg="#f5f5f5")
# 创建主框架
main_frame = ttk.frame(root, padding="20")
main_frame.pack(fill=tk.both, expand=true)
# 标题
title_label = ttk.label(main_frame, text="pdf元数据查看器", font=("arial", 16, "bold"))
title_label.pack(pady=(0, 15))
# 说明文字
info_label = ttk.label(main_frame,
text="选择pdf文件以查看其元数据信息(作者、标题、创建日期等)",
foreground="gray",
font=("arial", 10))
info_label.pack(anchor="w")
# 选择文件按钮
self.btn_browse = ttk.button(main_frame, text="选择pdf文件", command=self.browse_file, width=20)
self.btn_browse.pack(pady=10)
# 显示区域
self.text_area = scrolledtext(main_frame, wrap=tk.word, font=("arial", 10), state=tk.disabled)
self.text_area.pack(fill=tk.both, expand=true, pady=5)
# 操作按钮
btn_frame = ttk.frame(main_frame)
btn_frame.pack(pady=5)
self.btn_save = ttk.button(btn_frame, text="保存为文本文件", command=self.save_to_file, width=20)
self.btn_save.pack(side=tk.left, padx=5)
self.btn_clear = ttk.button(btn_frame, text="清除显示", command=self.clear_display, width=20)
self.btn_clear.pack(side=tk.left, padx=5)
# 状态栏
self.status_var = tk.stringvar()
self.status_var.set("就绪 - 请选择pdf文件")
self.status_bar = ttk.label(root, textvariable=self.status_var, relief=tk.sunken, anchor=tk.w)
self.status_bar.pack(side=tk.bottom, fill=tk.x)
# 信息提示
info_note = ttk.label(main_frame,
text="注意:pdf文件中不包含计算机mac地址信息,这些信息仅来自pdf的元数据",
foreground="red",
font=("arial", 9))
info_note.pack(pady=(10, 0), anchor="w")
def browse_file(self):
"""打开文件选择对话框"""
file_path = filedialog.askopenfilename(
title="选择pdf文件",
filetypes=[("pdf文件", "*.pdf"), ("所有文件", "*.*")]
)
if file_path:
self.display_metadata(file_path)
def display_metadata(self, file_path):
"""显示pdf元数据"""
try:
self.text_area.config(state=tk.normal)
self.text_area.delete(1.0, tk.end)
# 提取元数据
metadata = self.get_pdf_metadata(file_path)
if '错误' in metadata:
self.text_area.insert(tk.end, f"错误: {metadata['错误']}")
else:
# 显示元数据
self.text_area.insert(tk.end, f"pdf文件: {os.path.basename(file_path)}\n")
self.text_area.insert(tk.end, f"文件路径: {file_path}\n")
self.text_area.insert(tk.end, f"{'-'*50}\n")
self.text_area.insert(tk.end, "元数据信息:\n")
self.text_area.insert(tk.end, f"作者: {metadata.get('作者', '未指定')}\n")
self.text_area.insert(tk.end, f"标题: {metadata.get('标题', '未指定')}\n")
self.text_area.insert(tk.end, f"创建日期: {metadata.get('创建日期', '未指定')}\n")
self.text_area.insert(tk.end, f"修改日期: {metadata.get('修改日期', '未指定')}\n")
self.text_area.insert(tk.end, f"主题: {metadata.get('主题', '未指定')}\n")
self.text_area.insert(tk.end, f"关键词: {metadata.get('关键词', '未指定')}\n")
self.text_area.insert(tk.end, f"产品: {metadata.get('产品', '未指定')}\n")
self.text_area.config(state=tk.disabled)
self.status_var.set(f"已加载: {os.path.basename(file_path)}")
except exception as e:
self.text_area.config(state=tk.normal)
self.text_area.delete(1.0, tk.end)
self.text_area.insert(tk.end, f"错误: {str(e)}")
self.text_area.config(state=tk.disabled)
self.status_var.set("错误: 无法加载文件")
def get_pdf_metadata(self, file_path):
"""获取pdf元数据"""
try:
with open(file_path, 'rb') as file:
pdf_reader = pypdf2.pdfreader(file)
if pdf_reader.metadata:
return {
'作者': pdf_reader.metadata.get('/author', '未指定'),
'标题': pdf_reader.metadata.get('/title', '未指定'),
'创建日期': pdf_reader.metadata.get('/creationdate', '未指定'),
'修改日期': pdf_reader.metadata.get('/moddate', '未指定'),
'主题': pdf_reader.metadata.get('/subject', '未指定'),
'关键词': pdf_reader.metadata.get('/keywords', '未指定'),
'产品': pdf_reader.metadata.get('/producer', '未指定')
}
else:
return {'错误': 'pdf文件不包含元数据'}
except exception as e:
return {'错误': str(e)}
def save_to_file(self):
"""保存元数据到文本文件"""
if self.text_area.cget("state") == tk.disabled:
# 获取当前显示的文本
text = self.text_area.get(1.0, tk.end)
# 移除末尾的换行符
text = text.strip()
if not text or "错误" in text or "未指定" in text:
messagebox.showinfo("提示", "没有可保存的元数据")
return
# 选择保存位置
save_path = filedialog.asksaveasfilename(
defaultextension=".txt",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")],
initialfile="pdf_metadata.txt"
)
if save_path:
try:
with open(save_path, 'w', encoding='utf-8') as f:
f.write(text)
messagebox.showinfo("成功", f"元数据已保存到: {save_path}")
self.status_var.set(f"已保存到: {os.path.basename(save_path)}")
except exception as e:
messagebox.showerror("错误", f"无法保存文件: {str(e)}")
else:
messagebox.showinfo("提示", "请先加载一个pdf文件")
def clear_display(self):
"""清除显示区域"""
self.text_area.config(state=tk.normal)
self.text_area.delete(1.0, tk.end)
self.text_area.config(state=tk.disabled)
self.status_var.set("已清除显示内容")
if __name__ == "__main__":
try:
# 检查是否安装了pypdf2
import pypdf2
except importerror:
# 如果没有安装pypdf2,提示用户安装
messagebox.showerror("缺少库", "需要安装pypdf2库。请运行: pip install pypdf2")
exit(1)
root = tk.tk()
app = pdfmetadataviewer(root)
root.mainloop()
使用说明
1.安装依赖:
pip install pypdf2
2.运行程序:
- 点击"选择pdf文件"按钮
- 从文件浏览器中选择一个pdf文件
- 程序将显示pdf的元数据信息
功能说明
- 元数据提取:从pdf中提取作者、标题、创建日期、修改日期等信息
- 用户友好界面:使用tkinter创建的gui,简单直观
- 错误处理:处理常见错误(如文件不存在、pdf格式错误等)
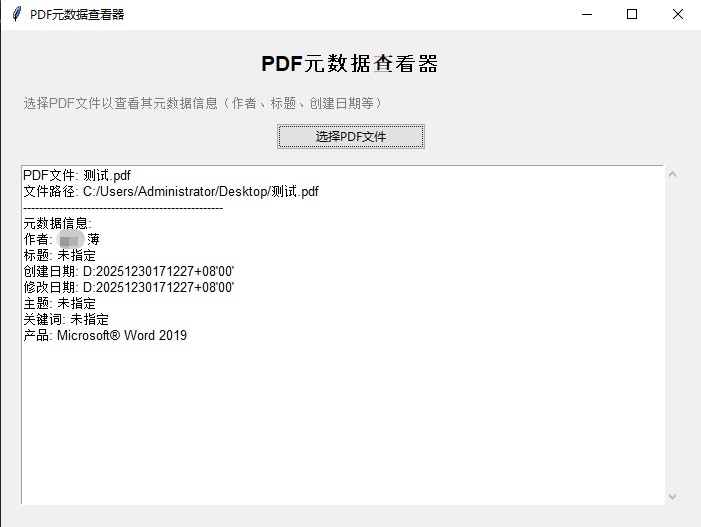
界面展示
到此这篇关于基于python开发一个pdf文件元数据查看器的文章就介绍到这了,更多相关python pdf文件元数据查看内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论