前言
语音转文字(stt,speech to text)是人机交互、音视频处理、智能客服等领域的核心技术,python 凭借生态丰富、易用性强的优势,成为 stt 开发的主流语言。当下各类 python stt 库百花齐放,既有开箱即用、轻量化的本地识别库,也有对接大厂接口、高精度的云端识别工具,还涵盖了兼顾速度与准确率的开源模型类库,适配个人开发、企业级项目等不同场景。本文将聚焦 python 生态中常用、成熟、高实用性的 stt 语音识别库,从功能特性、识别精度、部署成本、适用场景等维度展开盘点,为开发者选型提供清晰参考。
1 paddlespeech
paddlespeech 是百度飞桨开源的语音交互工具集,主打中文语音识别 / 合成能力,依托飞桨框架的高性能计算优势,在中文普通话、低音质音频识别场景下表现优异,且支持私有化部署,是企业级中文 stt 场景的首选方案之一。

1.1 安装步骤
安装命令:
conda create -n paddlespeech python=3.10 conda activate paddlespeech python -m pip install paddlepaddle-gpu==3.2.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/ # 安装paddlespeech git clone https://github.com/paddlepaddle/paddlespeech.git cd paddlespeech pip install pytest-runner pip install .
注:如果这里没有n卡,这里修改成pip install paddlepaddle,具体安装选择可以看官网:paddlepaddle
我这里之所以使用源码编译的方式去安装,是因为直接使用pip安装会有很多bug。
1.2 测试代码
import paddle from paddlespeech.cli.asr import asrexecutor asr_executor = asrexecutor() text = asr_executor(audio_file="test.wav", model="conformer_aishell") print(text)
1.3 遇到的报错
error: could not find a version that satisfies the requirement opencc==1.1.6 (from paddlespeech) (from versions: 0.1, 0.2, 1.1.0.post1, 1.1.1, 1.1.7, 1.1.8, 1.1.9) error: no matching distribution found for opencc==1.1.6
直接去paddlespeech/setup.py下面修改opencc安装版本:
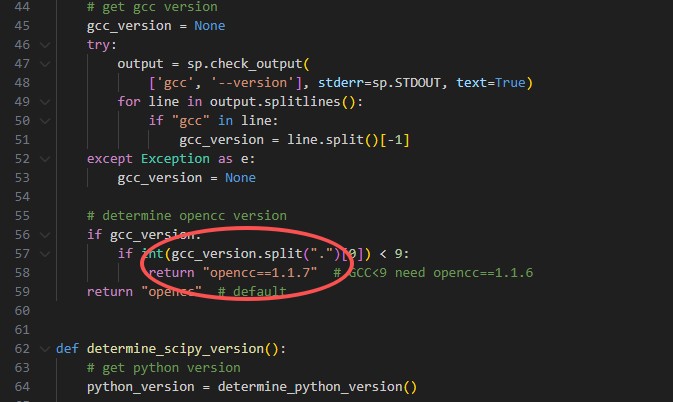
2 whisper
whisper 是 openai 开源的多语言语音识别模型,凭借海量多语言音频数据训练,支持 99 种语言识别,中文普通话识别准确率≈95%,且抗噪能力强,是个人开发、多语言场景的首选方案。

2.1 安装命令
conda create -n whisper_env python=3.10 conda activate whisper_env pip install -u openai-whisper
2.2 测试代码
import whisper
model = whisper.load_model("turbo")
result = model.transcribe("audio.mp3")
print(result["text"])
如下图所示,load_model时,可选参数为:
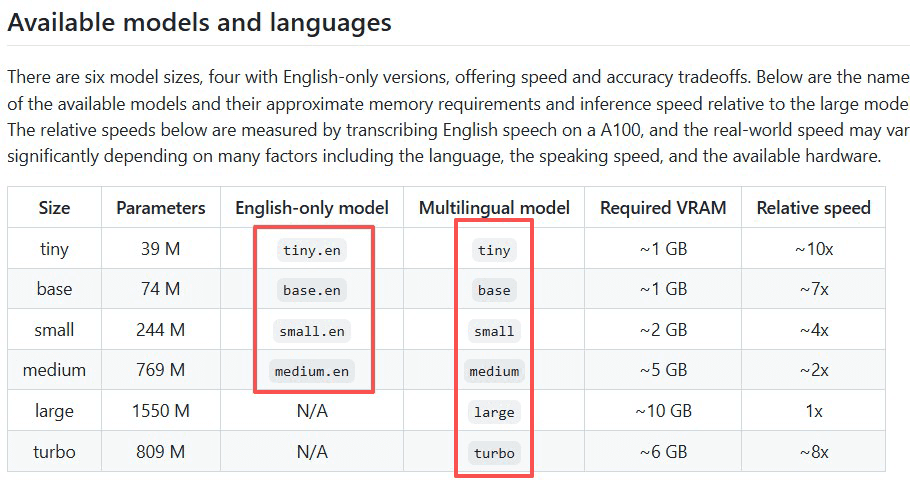
3 funasr
funasr 是阿里云通义实验室开源的语音识别框架,主打中文及方言识别,在 30 + 中文方言、低音质音频场景下表现领先,是中文专属 stt 场景的最优选择。

3.1 安装步骤
conda create -n funasr python=3.10 conda activate funasr pip3 install -u funasr pip3 install -u modelscope huggingface_hub pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
3.2 测试代码
from funasr import automodel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/sensevoicesmall"
model = automodel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"test.mp3",
cache={},
language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"
use_itn=true,
batch_size_s=60,
merge_vad=true, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)
3.3 遇到的错误
unboundlocalerror: local variable 'autotokenizer' referenced before assignment
报错原因: transformers 库版本过低或未安装,导致模型加载时无法找到 autotokenizer 类。
解决办法: 升级 transformers 库pip install -u transformers
assertionerror: funasrnano is not registered
报错原因: funasr 版本过低,未注册 funasrnano 模型类,常见于使用 fun-asr-nano 系列模型时。
解决办法: 手动导入模型类from funasr.models.fun_asr_nano.model import funasrnano
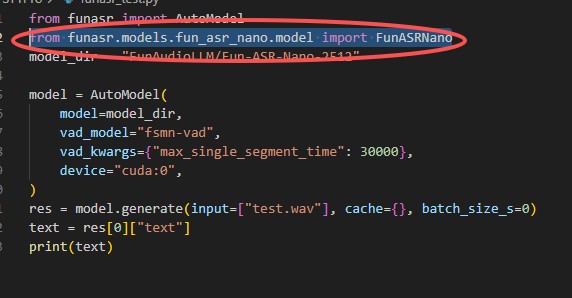
loading remote code failed: model, no module named 'model'...oserror: error no file named pytorch_model.bin, model.safetensors, tf_model.h5, model.ckpt.index or flax_model.msgpack found in directory xxx
报错原因: funaudiollm/fun-asr-nano-251 模型适配性较差,远程代码加载失败或权重文件下载不完整。
解决办法: 替换为 funasr 官方稳定支持的模型(如 iic/sensevoicesmall、paraformer-large),避免使用适配性不足的 nano 系列模型。
总结
本文盘点了 python 生态中三大主流 stt 库:paddlespeech 适配飞桨生态,适合企业级中文通用场景;whisper 主打多语言识别,易用性拉满,适配个人开发;funasr 在中文方言识别领域优势显著,适合中文专属场景。实际开发中,个人 / 多语言场景优先选 whisper,中文方言 / 企业级场景优先选 funasr,飞桨生态项目可选用 paddlespeech。开发时需注意版本适配与依赖管理,遇到问题可优先通过升级库或替换模型解决,确保识别效果与稳定性。
到此这篇关于主流python语音转文字(stt)库实战指南的文章就介绍到这了,更多相关python语音转文字(stt)库内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论