引言
在开发涉及多语言处理的应用时,经常需要对输入的文本进行语言或字符类型的判断。特别是在中文环境下,准确地识别中文字符对于文本处理、数据验证等操作至关重要。本文将介绍如何在java中实现对中文字符的精确判断。
1. 中文字符的unicode范围
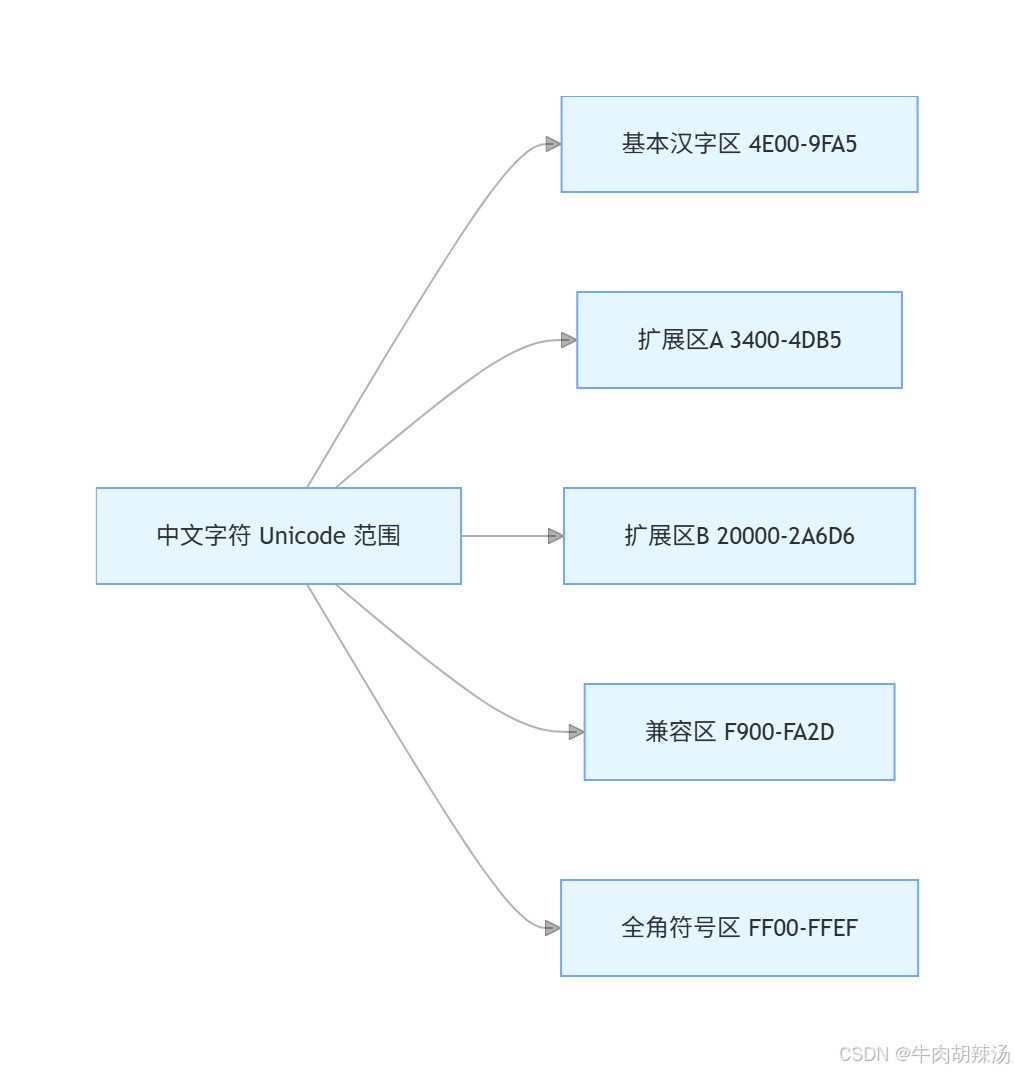
中文字符主要分布在以下几个unicode范围内:
- 基本汉字区(cjk unified ideographs):
4e00 - 9fa5 - 全角ascii、全角中英文标点、半宽片假名、半宽平假名、半宽韩文字母:
ff00 - ffef - 兼容区(cjk compatibility ideographs):
f900 - fa2d - 扩展区a(cjk unified ideographs extension a):
3400 - 4db5 - 扩展区b(cjk unified ideographs extension b):
20000 - 2a6d6
了解这些范围后,我们可以通过检查字符的unicode值来判断一个字符是否属于中文字符。
2. 实现中文字符判断的方法
2.1 单个字符判断
首先,我们可以编写一个方法来判断单个字符是否是中文字符:
public static boolean ischinesechar(char c) {
return (c >= '\u4e00' && c <= '\u9fa5') || // 基本汉字区
(c >= '\u3400' && c <= '\u4db5') || // 扩展区a
(c >= '\u20000' && c <= '\u2a6d6') || // 扩展区b
(c >= '\uf900' && c <= '\ufa2d') || // 兼容区
(c >= '\uff00' && c <= '\uffef'); // 全角ascii、全角中英文标点、半宽片假名、半宽平假名、半宽韩文字母
}2.2 字符串判断
接下来,我们可以扩展这个方法,使其能够判断整个字符串是否包含中文字符:
public static boolean containschinese(string str) {
if (str == null || str.isempty()) {
return false;
}
for (char c : str.tochararray()) {
if (ischinesechar(c)) {
return true;
}
}
return false;
}2.3 判断字符串是否完全由中文字符组成
有时候,我们需要判断一个字符串是否完全由中文字符组成,可以这样实现:
public static boolean isallchinese(string str) {
if (str == null || str.isempty()) {
return false;
}
for (char c : str.tochararray()) {
if (!ischinesechar(c)) {
return false;
}
}
return true;
}3. 测试代码
为了验证上述方法的正确性,我们可以编写一些测试代码:
public class chinesecharactertest {
public static void main(string[] args) {
system.out.println(ischinesechar('汉')); // true
system.out.println(ischinesechar('a')); // false
system.out.println(containschinese("hello, 世界")); // true
system.out.println(containschinese("hello, world")); // false
system.out.println(isallchinese("你好,世界")); // true
system.out.println(isallchinese("hello, 世界")); // false
}
}在java中,判断一个字符串是否包含中文字符可以通过正则表达式来实现。中文字符通常位于unicode编码的u+4e00到u+9fff范围内,还包括一些扩展区间的字符。以下是一个示例代码,展示了如何使用正则表达式来判断一个字符串是否包含中文字符:
public class chinesecharacterchecker {
public static void main(string[] args) {
string text1 = "hello, 世界!";
string text2 = "hello, world!";
system.out.println("text1 contains chinese characters: " + containschinesecharacters(text1));
system.out.println("text2 contains chinese characters: " + containschinesecharacters(text2));
}
/**
* 判断字符串是否包含中文字符
* @param text 待检查的字符串
* @return 如果字符串包含中文字符,则返回true;否则返回false
*/
public static boolean containschinesecharacters(string text) {
// 中文字符的正则表达式
string chineseregex = "[\\u4e00-\\u9fff]+";
return text.matches(".*" + chineseregex + ".*");
}
}代码解释
- 正则表达式:
-
[\u4e00-\u9fff]:匹配任何中文字符。 -
+:表示匹配一个或多个中文字符。 -
.*:表示匹配任意数量的任意字符。
- 方法
containschinesecharacters:
- 使用
matches 方法来检查字符串是否包含中文字符。matches 方法会检查整个字符串是否匹配给定的正则表达式。 -
.* 在正则表达式的前后是为了确保即使中文字符出现在字符串的任何位置,也能被正确匹配。
运行结果
运行上述代码,输出将会是:
text1 contains chinese characters: true text2 contains chinese characters: false
扩展
如果你需要更精确地判断中文字符,包括一些扩展区间的字符(如繁体字、古汉字等),可以使用更复杂的正则表达式:
public static boolean containschinesecharacters(string text) {
// 包括更多中文字符范围的正则表达式
string chineseregex = "[\\u4e00-\\u9fff\\u3400-\\u4dbf\\u20000-\\u2a6df\\u2a700-\\u2b73f\\u2b740-\\u2b81f\\u2b820-\\u2ceaf\\uf900-\\ufaff\\u2f800-\\u2fa1f]+";
return text.matches(".*" + chineseregex + ".*");
}中文字符属于unicode编码的一部分,通常位于特定的unicode区间内。以下是一些常用的方法来判断一个字符串是否包含中文字符:
1. 使用正则表达式
正则表达式是一种非常灵活的方式来匹配字符串中的特定模式。对于中文字符,可以使用如下正则表达式:
public class chinesecharacterchecker {
public static boolean containschinese(string str) {
if (str == null || str.isempty()) {
return false;
}
// 中文字符的unicode范围是:\u4e00-\u9fa5
string pattern = "[\\u4e00-\\u9fa5]";
return str.matches(".*" + pattern + ".*");
}
public static void main(string[] args) {
string teststr = "这是一个测试字符串 test string";
system.out.println("包含中文字符: " + containschinese(teststr));
}
}2. 使用character类的方法
java的character类提供了一些方法来检查字符的类型,包括是否是汉字。可以通过遍历字符串中的每个字符来检查它是否是中文字符:
public class chinesecharacterchecker {
public static boolean containschinese(string str) {
if (str == null || str.isempty()) {
return false;
}
for (char c : str.tochararray()) {
if (ischinese(c)) {
return true;
}
}
return false;
}
private static boolean ischinese(char c) {
character.unicodeblock ub = character.unicodeblock.of(c);
return ub == character.unicodeblock.cjk_unified_ideographs
|| ub == character.unicodeblock.cjk_compatibility_ideographs
|| ub == character.unicodeblock.cjk_unified_ideographs_extension_a
|| ub == character.unicodeblock.cjk_unified_ideographs_extension_b
|| ub == character.unicodeblock.cjk_symbols_and_punctuation
|| ub == character.unicodeblock.halfwidth_and_fullwidth_forms
|| ub == character.unicodeblock.general_punctuation;
}
public static void main(string[] args) {
string teststr = "这是一个测试字符串 test string";
system.out.println("包含中文字符: " + containschinese(teststr));
}
}3. 使用charmatcher(guava库)
如果你的项目中已经引入了google guava库,可以使用charmatcher来简化中文字符的检测:
import com.google.common.base.charmatcher;
public class chinesecharacterchecker {
public static boolean containschinese(string str) {
if (str == null || str.isempty()) {
return false;
}
charmatcher chinesematcher = charmatcher.inrange('\u4e00', '\u9fa5');
return chinesematcher.anymatch(str);
}
public static void main(string[] args) {
string teststr = "这是一个测试字符串 test string";
system.out.println("包含中文字符: " + containschinese(teststr));
}
}总结
以上三种方法都可以有效地检测字符串中是否包含中文字符。选择哪种方法取决于你的具体需求和项目环境。正则表达式简单直接,适合快速实现;character类的方法更为精确,能够覆盖更广泛的中文字符集;而使用guava库的方法则更加简洁,适合已经在使用guava的项目。
以上就是java中实现对中文字符的精确判断的方法的详细内容,更多关于java判断中文字符的资料请关注代码网其它相关文章!






发表评论