在mysql运维中,“删除”操作看似简单,却隐藏着诸多风险——误删表导致数据永久丢失、delete全表引发主从延迟、删数据后磁盘空间不释放……这些问题往往会造成业务中断或资源浪费。本文基于实际运维场景,详细讲解删除表、清空表、部分数据删除(归档/不归档)、分区表清理四大核心场景的最佳操作方案,结合实验验证和原理分析,帮你在“安全”与“效率”之间找到平衡。
一、删除表:先“隔离”再“删除”,避免误删风险
直接执行drop table是高危操作——若存在未发现的业务依赖(如定时任务、应用sql),会瞬间导致服务报错;且误删后恢复成本极高(需从备份恢复,耗时久)。最佳实践是先重命名表“隔离”,观察无依赖后再删除。
1.1 操作步骤(以表t1为例)
步骤1:创建测试表(模拟业务表)
-- 先删除旧表(若存在),避免冲突 drop table if exists t1; -- 创建业务表t1(innodb引擎,含自增主键和时间字段) create table `t1` ( `id` int not null auto_increment, `a` varchar(20) default null, -- 业务字段1 `b` int default null, -- 业务字段2 `c` datetime not null default current_timestamp, -- 自动时间戳 primary key (`id`) ) engine=innodb charset=utf8mb4 ;
步骤2:重命名表,实现“隔离”
将目标表重命名为“备份+日期”格式(如t1_bak_20231114),切断业务直接访问:
alter table t1 rename t1_bak_20231114;
步骤3:观察依赖,确认安全
重命名后,观察1-2周(根据业务周期调整),重点监控:
- 应用日志:是否出现“table ‘martin.t1’ doesn’t exist”错误(排查隐藏依赖);
- 数据库进程:是否有定时任务或存储过程调用原表名。
若观察期内无异常,说明表无依赖,可执行删除。
步骤4:最终删除备份表
drop table t1_bak_20231114;
1.2 核心原理与注意事项
- 为什么不直接drop?
重命名本质是“逻辑隔离”,若发现误操作,可快速改回原表名(alter table t1_bak_20231114 rename t1;),恢复成本几乎为0;而drop会直接删除表结构和数据文件,无法快速恢复。 - 适用场景:非紧急删除的冗余表、历史表(如旧业务下线后的废弃表)。
二、清空表:选对工具(truncate),避免空间浪费与主从延迟
清空表(删除全表数据)时,很多人习惯用delete from 表名,但该操作存在两大问题:不释放磁盘空间、行模式binlog下产生大量日志导致主从延迟。正确选择是truncate table。
2.1 实验对比:delete vs truncate
步骤1:准备测试数据(10万行)
use martin;
-- 重建表t1
drop table if exists t1;
create table `t1` (
`id` int not null auto_increment,
`a` varchar(20) default null,
`b` int default null,
`c` datetime not null default current_timestamp,
primary key (`id`)
) engine=innodb charset=utf8mb4 ;
-- 创建存储过程,插入10万行数据
drop procedure if exists insert_t1;
delimiter ;; -- 临时修改语句结束符,避免与存储过程内;冲突
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=100000)do -- 循环插入10万行
insert into t1(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
-- 执行存储过程,初始化数据
call insert_t1();
步骤2:查看数据文件大小(innodb表的.ibd文件)
innodb表的数据存储在ibd文件中,先查看初始大小:
# 进入mysql数据目录(需根据实际路径调整,此处为/data/mysql/data/martin) cd /data/mysql/data/martin # 查看t1.ibd大小(-h表示人性化显示,如kb/mb) ll -h t1.ibd
实验结果:t1.ibd约12mb(10万行数据)。
步骤3:用delete清空表,观察空间变化
-- delete全表数据 delete from t1;
再执行ll -h t1.ibd,结果:文件大小仍为12mb,无变化。

步骤4:用truncate清空表,观察空间变化
-- 先重建表并插入数据(恢复到步骤2状态) call insert_t1(); -- truncate清空表 truncate table t1;
再执行ll -h t1.ibd,结果:文件大小骤减至112kb(仅保留表结构,释放所有数据空间)。

2.2 关键差异:delete vs truncate
| 对比维度 | delete | truncate |
|---|---|---|
| 操作类型 | dml(数据操纵语言) | ddl(数据定义语言) |
| 空间释放 | 不释放(仅标记删除) | 释放(重建表结构) |
| binlog记录 | 行模式下逐行记录(日志量大) | 仅记录“ truncate操作”(日志量小) |
| 事务支持 | 可回滚(未提交前可撤销) | 不可回滚(执行即生效) |
| 自增主键重置 | 不重置(下次插入从上次id继续) | 重置(下次插入从1开始) |
2.3 注意事项
- 必须先备份:无论用哪种方式,清空表前需用
mysqldump备份数据(mysqldump -uroot -p martin t1 > t1_bak.sql),避免误清。 - truncate的限制:若表被外键引用(
foreign key),无法直接truncate(需先删除外键或清空关联表);而delete可正常执行。
三、不归档删除部分数据:避免大事务,用批量删除或工具
当需删除表中部分数据(如删除b<50000的历史数据)且无需归档时,直接执行delete from t2 where b<50000会引发大事务——锁表时间长、占用大量undo日志、主从延迟。最佳方案是批量删除(加limit) 或用专业工具pt-archiver。
3.1 方案1:循环批量删除(适合中小数据量)
核心逻辑:
每次删除1000-10000行(根据服务器性能调整),循环执行直到满足条件的数据删完,避免单次删除行数过多。
操作步骤:
步骤1:准备测试表与数据(10万行)
use martin;
drop table if exists t2;
create table `t2` (
`id` int not null auto_increment,
`a` int default null,
`b` int default null,
primary key (id), -- 主键索引
key idx_b(b) -- 为查询条件b创建索引,加速删除
) engine=innodb charset=utf8mb4 ;
-- 存储过程插入10万行数据
drop procedure if exists insert_t2;
delimiter ;;
create procedure insert_t2()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t2(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t2();
步骤2:备份数据(安全前提)
# 用mysqldump备份t2表 cd /data/backup mysqldump -uroot -p martin t2 > t2_bak.sql # 或创建备份表,复制数据(更快速) create table t2_bak_1114 like t2; -- 复制表结构 insert into t2_bak_1114 select * from t2; -- 复制数据
步骤3:循环批量删除
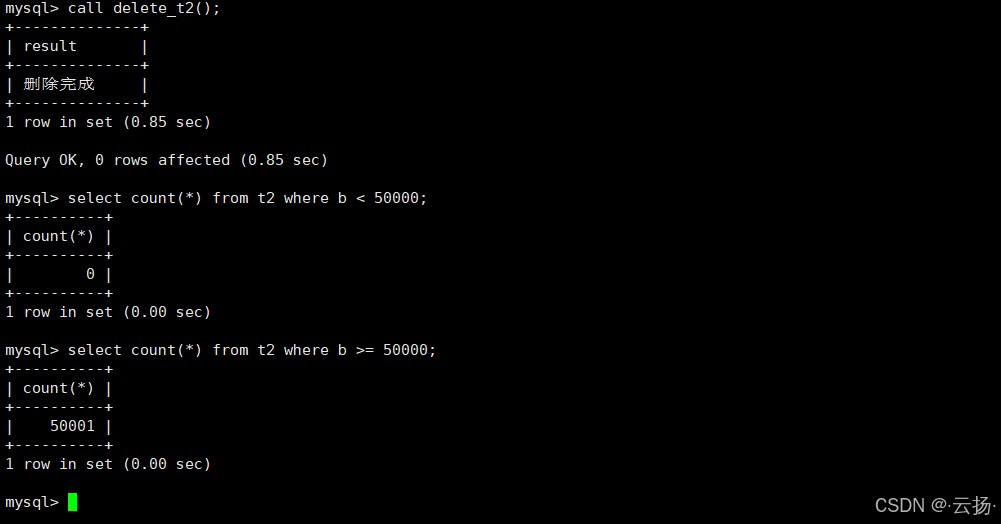
delimiter //
create procedure delete_t2()
begin
repeat
delete from t2 where b < 50000 limit 1000;
until row_count() = 0 end repeat;
select '删除完成' as result;
end //
delimiter ;
验证结果:
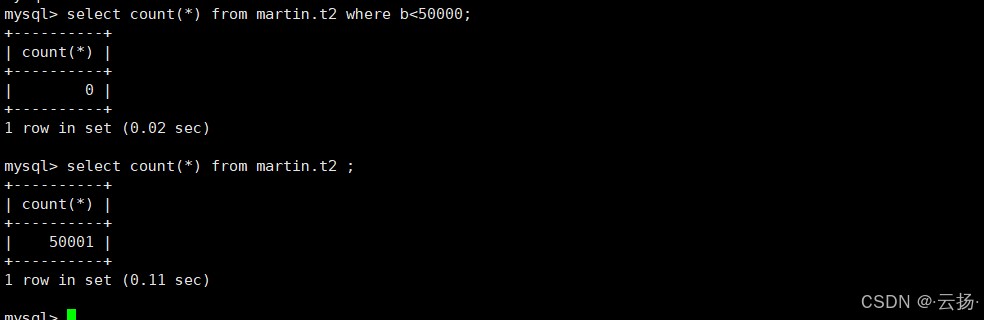
-- 确认删除效果(应返回0) select count(*) from t2 where b < 50000; -- 剩余数据量(应返回50000) select count(*) from t2 where b >= 50000;
3.2 方案2:用pt-archiver工具(适合大数据量)
pt-archiver是percona toolkit中的工具,专为批量归档/删除mysql数据设计,支持按条件批量处理、统计进度,且能避免大事务。
步骤1:安装percona toolkit(以centos为例)
# 安装依赖 yum install -y perl-dbi perl-dbd-mysql perl-time-hires perl-io-socket-ssl # 下载并安装percona toolkit wget https://downloads.percona.com/downloads/percona-toolkit/3.5.1/binary/redhat/8/x86_64/percona-toolkit-3.5.1-1.el8.x86_64.rpm rpm -ivh percona-toolkit-3.5.1-1.el8.x86_64.rpm # 验证安装(查看版本) pt-archiver --version
步骤2:创建工具专用用户(授予权限)
-- 创建dba用户,允许192.168网段访问 create user 'dba'@'192.168.%' identified with mysql_native_password by 'id81gdac_a'; -- 授予全库权限(生产环境可缩小权限范围,仅授予martin库权限) grant all on *.* to 'dba'@'192.168.%';
步骤3:执行删除(不归档,仅删除)
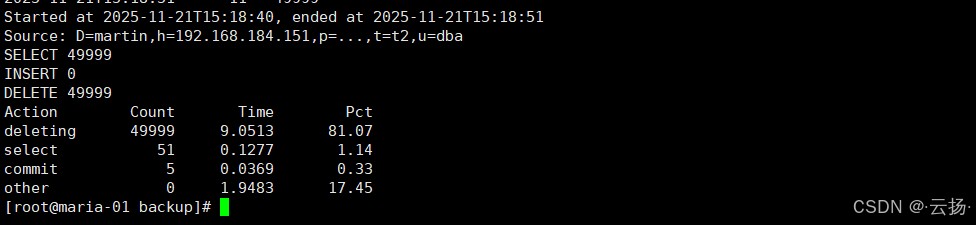
pt-archiver \ --source h=192.168.184.151,u=dba,p='id81gdac_a',d=martin,t=t2 \ # 源表信息 --where "b<50000" \ # 删除条件 --progress 10000 \ # 每处理10000行显示进度 --limit=1000 \ # 每次处理1000行 --txn-size 10000 \ # 每10000行提交一次事务 --no-safe-auto-increment \ # 不修改自增主键(避免影响后续插入) --statistics \ # 输出统计信息(如处理时间、行数) --purge # 仅删除,不归档(核心参数)
统计结果示例:
四、归档删除部分数据:先迁移再删除,兼顾数据保留与空间回收
若需删除的部分数据需长期保留(如归档历史日志),需先将数据迁移到“归档库”,再删除源表数据。同时,需注意:delete删除后表会产生“空洞”(未释放的空间),需重建表回收空间。
4.1 操作步骤(用pt-archiver实现归档+删除)
步骤1:准备归档环境
- 源库:192.168.184.151(martin库,t2表,需删除b<50000的数据);
- 归档库:192.168.184.152(新建archiver_db库,t2_archiver表,用于存储归档数据)。
步骤2:在归档库创建表结构
-- 登录归档库(192.168.184.152) mysql -uroot -p -- 创建归档数据库 create database archiver_db; use archiver_db; -- 创建与源表结构一致的归档表 create table `t2_archiver` ( `id` int not null auto_increment, `a` int default null, `b` int default null, primary key (id), key idx_b(b) ) engine=innodb charset=utf8mb4 ; -- 授予dba用户归档库权限 create user 'dba'@'192.168.%' identified with mysql_native_password by 'id81gdac_a'; grant all on *.* to 'dba'@'192.168.%';
步骤3:归档+删除(pt-archiver)
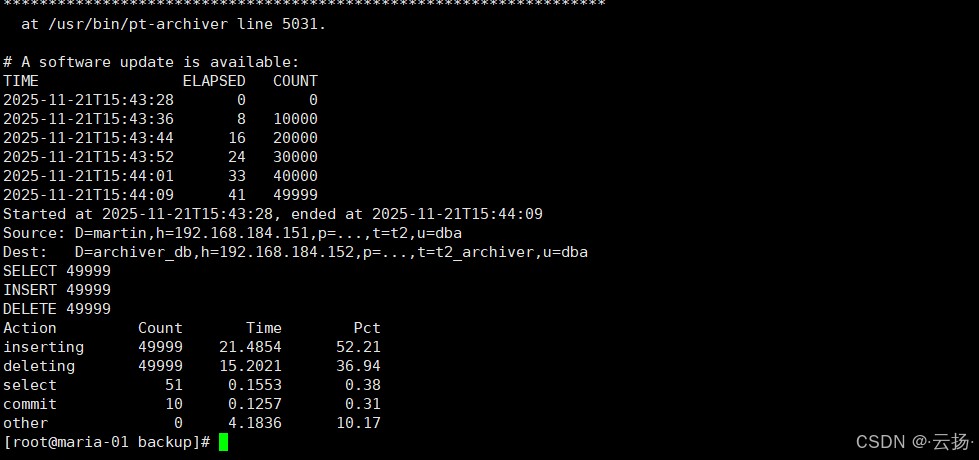
# 关闭归档库的防火墙(避免连接失败) iptables -f # 仅测试环境,生产环境需配置白名单 # 执行归档+删除 pt-archiver \ --source h=192.168.184.151,u=dba,p='id81gdac_a',d=martin,t=t2 \ # 源表 --dest h=192.168.184.152,u=dba,p='id81gdac_a',d=archiver_db,t=t2_archiver \ # 归档表 --where "b<50000" \ # 归档条件 --progress 10000 \ # 进度显示 --limit=1000 \ # 每次处理1000行 --txn-size 10000 \ # 事务大小 --no-safe-auto-increment \ --statistics \ --purge # 归档后删除源表数据
步骤4:验证归档与删除结果
源库验证:
select count(*) from martin.t2 where b<50000; -- 应返回0 select count(*) from martin.t2; -- 应返回50001
归档库验证:
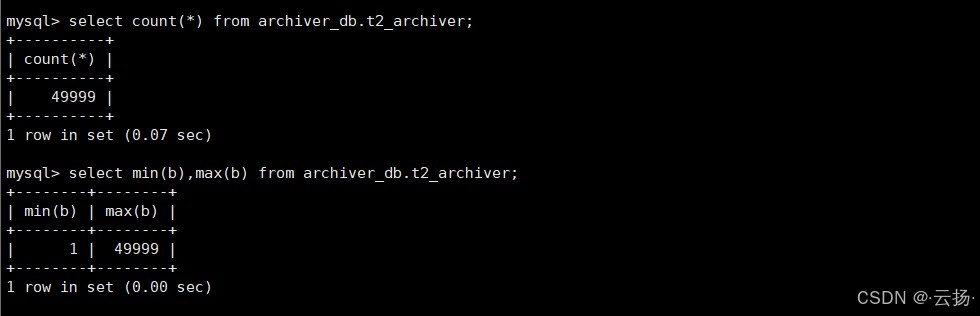
select count(*) from archiver_db.t2_archiver; -- 应返回49999 select min(b),max(b) from archiver_db.t2_archiver; -- 应返回1和49999
4.2 回收delete产生的“空洞”空间
delete删除数据后,innodb会将数据标记为“删除”,但磁盘空间不释放(形成“空洞”),需通过重建表回收空间:
-- 方法1:alter table重建表(推荐,innodb会整理空间) alter table martin.t2 engine=innodb; -- 方法2:optimize table(效果同上,仅支持innodb和myisam) optimize table martin.t2; -- 验证空间变化 ll -h /data/mysql/data/martin/t2.ibd # 空间应明显减少

五、分区表删除:按分区清理,效率翻倍
对于按时间/范围分区的表(如日志表、订单历史表),删除某一时间段的数据时,直接删除分区比delete更高效——drop分区是ddl操作,直接删除分区对应的物理文件,无需逐行处理,速度极快。
5.1 操作步骤(以按年份分区的日志表为例)
步骤1:创建range分区表
use martin;
drop table if exists t3_log ;
-- 创建按年份分区的日志表(2016、2017、2018三个分区)
create table t3_log (
id int,
log_info varchar (100), -- 日志内容
date datetime -- 分区键(按年份分区)
) engine = innodb
partition by range (year(date))( -- range分区,按year(date)的值分区
partition p2016 values less than (2017), -- 2016年数据(<2017)
partition p2017 values less than (2018), -- 2017年数据(<2018)
partition p2018 values less than (2019) -- 2018年数据(<2019)
);
步骤2:插入测试数据
insert into t3_log values (1,'aaa','2016-01-01'), -- 进入p2016分区 (2,'bbb','2016-06-01'), -- 进入p2016分区 (3,'ccc','2017-01-01'), -- 进入p2017分区 (4,'ddd','2018-01-01'); -- 进入p2018分区
步骤3:查看分区数据分布
select table_schema, -- 数据库名 table_name, -- 表名 partition_name,-- 分区名 table_rows -- 分区行数 from information_schema.partitions where table_schema='martin' and table_name='t3_log';
结果:p2016(2行)、p2017(1行)、p2018(1行)。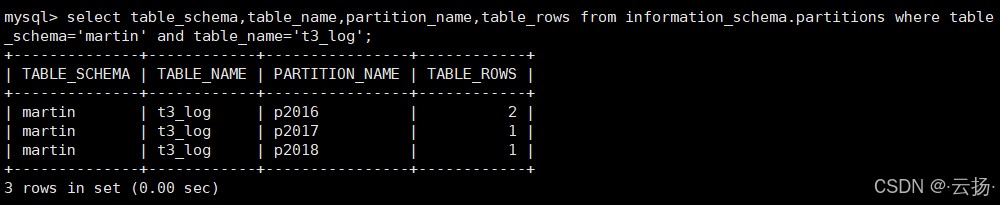
步骤4:删除2016年数据(直接drop分区)
-- 删除p2016分区(即删除2016年所有数据) alter table t3_log drop partition p2016;
步骤5:验证删除结果
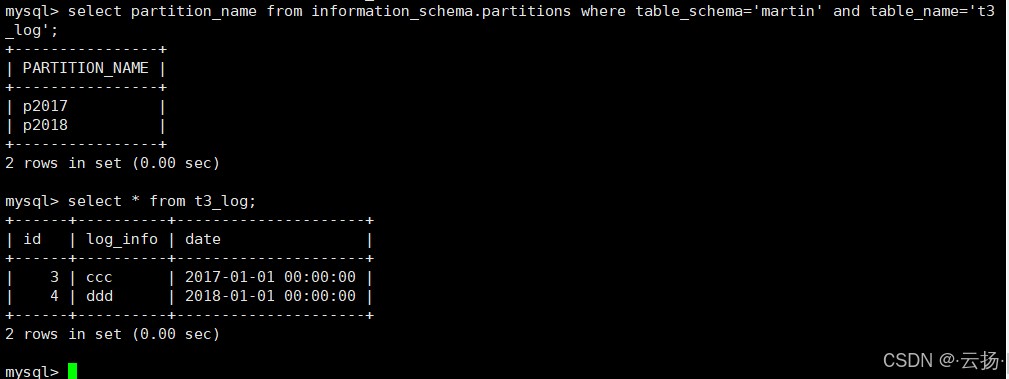
-- 查看分区列表(p2016已消失) select partition_name from information_schema.partitions where table_schema='martin' and table_name='t3_log'; -- 查询全表数据(2016年数据已删除) select * from t3_log; -- 仅返回2017、2018年数据
5.2 核心优势与适用场景
- 效率高:drop分区耗时毫秒级,适合tb级大表;
- 无空洞:删除分区直接释放文件,无需后续空间回收;
- 适用场景:按时间/范围分区的表(如日志表、账单表、订单历史表)。
六、总结:mysql删除操作的核心原则与场景选型
| 操作场景 | 推荐方案 | 核心注意事项 |
|---|---|---|
| 删除冗余表 | 重命名→观察→drop | 观察期1-2周,排查隐藏依赖 |
| 清空全表数据 | truncate table | 先备份,外键表需先处理关联关系 |
| 不归档删除部分数据(小) | 循环delete + limit | 每次删1000-10000行,加索引加速条件查询 |
| 不归档删除部分数据(大) | pt-archiver --purge | 低峰期执行,避免影响业务 |
| 归档删除部分数据 | pt-archiver --dest + 重建表 | 归档库与源库结构一致,删除后回收空洞空间 |
| 分区表删除历史数据 | alter table drop partition | 分区键选择合理(如时间),避免跨分区删除 |
核心原则:
- 安全优先:任何删除操作前必须备份,高危操作(如drop表)需先隔离观察;
- 效率第二:根据数据量和场景选对工具,避免大事务和主从延迟;
- 空间回收:delete后需通过重建表回收空洞,truncate/drop分区无需额外操作。
掌握这些方法,可有效避免mysql删除操作中的常见风险,同时兼顾效率与资源合理利用,让运维工作更稳定、高效。
以上就是mysql表数据删除与清理的最佳实践的详细内容,更多关于mysql表数据删除与清理的资料请关注代码网其它相关文章!






发表评论