引言
在日常业务开发中,分页查询是高频操作,比如列表页数据展示、历史记录查询等。但当数据量达到万级以上时,普通的limit分页往往会出现性能瓶颈。本文基于实际测试场景,详细分析mysql分页查询的执行原理,并针对不同排序场景提供优化方案,附完整测试代码与执行计划对比。
一、测试环境搭建:模拟万级数据量
为了更真实地复现分页查询问题,我们先创建测试表并插入10万条测试数据,确保测试环境的一致性。
1.1 创建测试表
use martin; -- 切换到目标数据库 drop table if exists t1; -- 若表已存在则删除 create table `t1` ( `id` int not null auto_increment, -- 自增主键 `a` int default null, -- 普通字段,用于非主键排序测试 `b` int default null, -- 普通字段 `create_time` datetime not null default current_timestamp comment '记录创建时间', `update_time` datetime not null default current_timestamp on update current_timestamp comment '记录更新时间', primary key (`id`), -- 主键索引 key `idx_a` (`a`), -- 为字段a创建普通索引,用于非主键排序优化 key `idx_b` (`b`) -- 为字段b创建普通索引(备用) ) engine=innodb default charset=utf8mb4;
1.2 批量插入测试数据
通过存储过程批量插入10万条数据,避免手动插入的繁琐:
drop procedure if exists insert_t1; -- 若存储过程已存在则删除
delimiter ;; -- 修改语句结束符,避免与存储过程内的分号冲突
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=100000)do -- 插入10万条数据
insert into t1(a,b) values(i, i); -- a、b字段值与自增id一致
set i=i+1;
end while;
end;;
delimiter ; -- 恢复语句结束符为分号
call insert_t1(); -- 调用存储过程插入数据
二、基础分页查询:问题与执行计划分析
最常见的分页查询方式是使用limit offset, size,但当offset(偏移量)较大时,性能会显著下降。我们以“查询第10001-10010条数据”为例,分析其执行逻辑。
2.1 普通limit分页sql
-- 查询a、b字段,跳过前10000条,取10条 select a,b from t1 limit 10000,10;
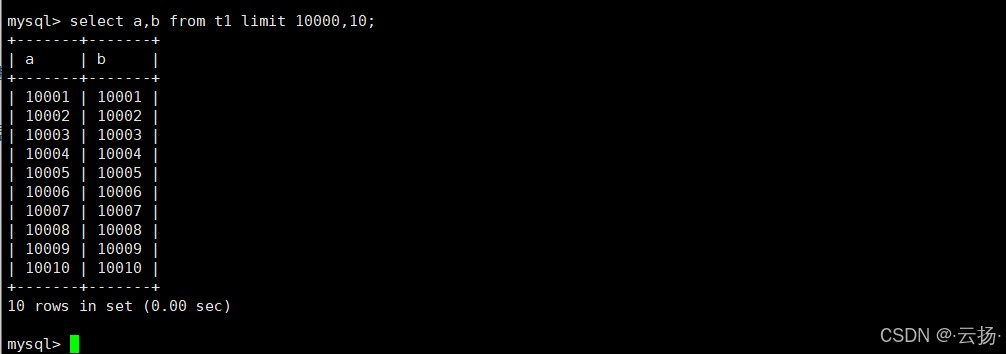
2.2 执行计划分析

通过explain查看sql执行计划,关键信息如下(对应测试截图结果):
- type:可能为
all(全表扫描)或range(范围扫描),取决于是否使用索引; - key:若未命中索引,
key字段为空,意味着需要扫描全表数据; - rows:扫描行数接近10010行(需跳过前10000行,再取10行),数据量越大,扫描行数越多,性能越差。
核心问题:limit 10000,10会先扫描前10010条数据,再丢弃前10000条,仅返回最后10条,大量数据的“无效扫描”导致性能损耗。
三、优化方案一:基于自增连续主键的分页查询
若分页查询基于自增且连续的主键排序(如按id升序),可通过“主键范围查询”替代limit offset,彻底避免无效数据扫描。
3.1 优化后的sql
-- 直接查询id在10001-10010之间的数据,无需跳过前10000条 select a,b from t1 where id > 10000 and id <= 10010;
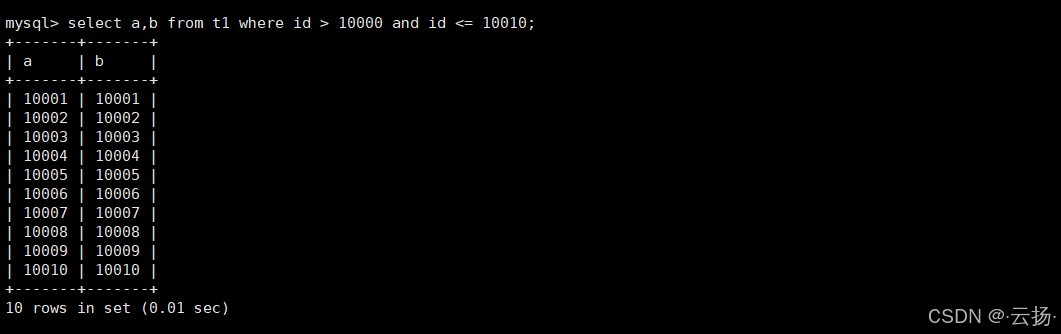
3.2 执行计划对比

再次使用explain分析优化后的sql,执行计划发生显著变化:
- type:变为
range(范围扫描),仅扫描主键索引中id在10001-10010之间的记录; - key:命中主键索引(
primary),无需扫描全表; - rows:扫描行数仅为10行,与需要返回的数据量完全一致,性能大幅提升。
3.3 关键注意事项
此方案的前提是主键必须连续。若主键不连续(如删除过数据),会导致查询结果与普通limit分页不一致,示例如下:
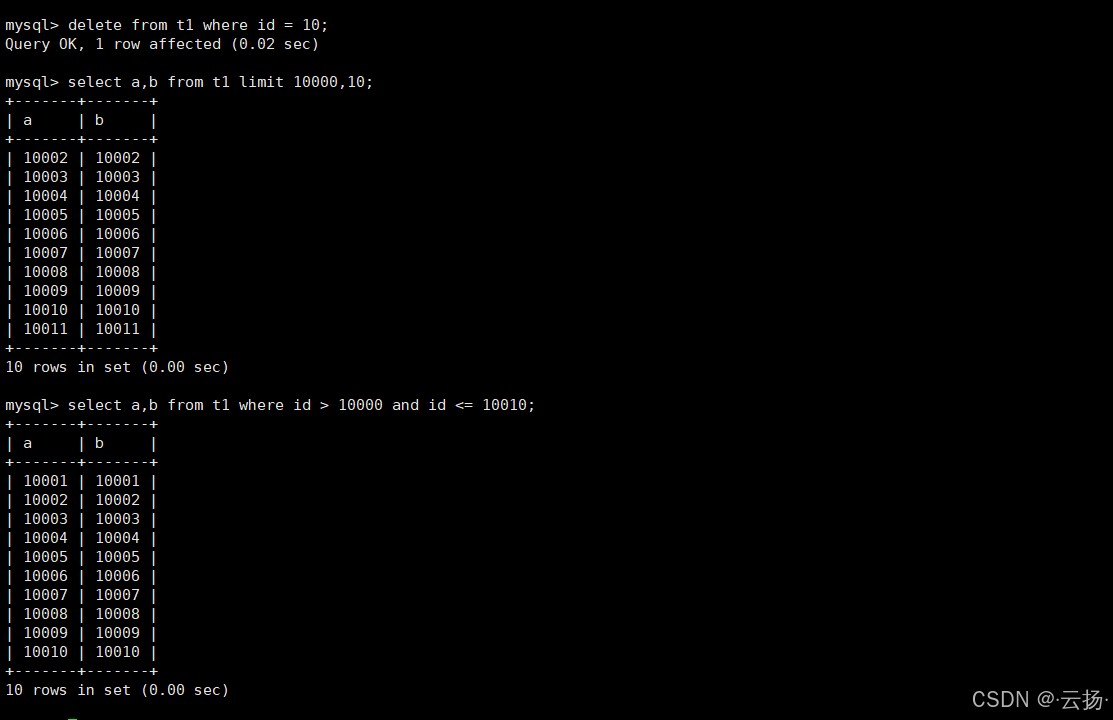
先删除一条数据,破坏主键连续性:
delete from t1 where id=10; -- 删除id=10的记录
对比两种查询结果:
- 普通
limit:select a,b from t1 limit 10000,10会跳过前10000条(包含被删除的id=10,实际扫描10001条有效数据),返回第10001-10010条有效数据; - 主键范围查询:
select a,b from t1 where id >10000 and id <=10010会跳过id=10的空缺,直接返回id=10001-10010的10条数据,与预期结果不一致。
适用场景:主键自增且无删除操作的表(如日志表、流水表)。
四、优化方案二:基于非主键字段排序的分页查询
若分页查询需要按非主键字段排序(如按a字段升序),直接使用order by + limit会触发filesort(文件排序),性能极差。我们通过“子查询查主键 + 关联查详情”的方式优化。
4.1 普通非主键排序分页的问题
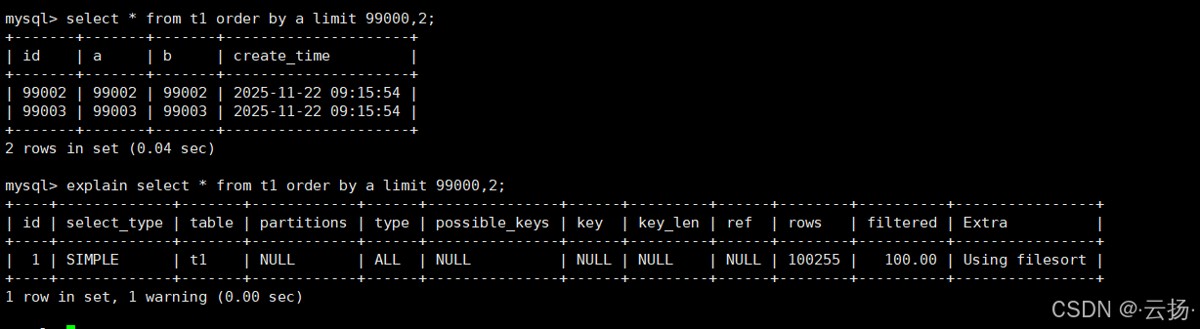
以“按a字段排序,查询第99001-99002条数据”为例,普通sql如下:
select * from t1 order by a limit 99000,2;
- 执行计划问题:
order by a会触发filesort(即使a字段有索引idx_a,若查询字段包含非索引字段,仍需回表,可能导致filesort); - 性能损耗:需扫描大量数据并排序,数据量越大,排序耗时越长。
4.2 优化后的sql
核心思路:先通过子查询仅查询“排序后的主键id”(利用索引避免filesort),再通过主键关联查询完整数据:
-- 子查询:按a排序,取第99001-99002条的id(仅扫描索引,无filesort) -- 主查询:通过id关联表t1,查询完整数据(主键关联性能极高) select f.* from t1 f inner join (select id from t1 order by a limit 99000,2) g on f.id = g.id;
4.3 执行计划优化点
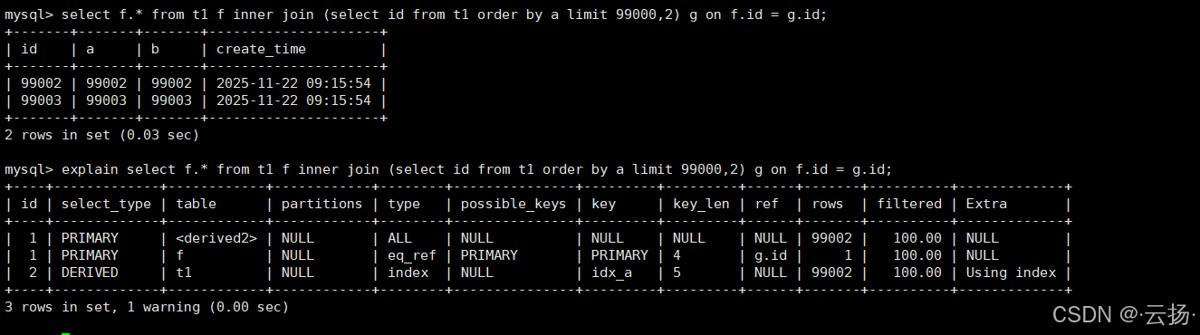
- 子查询:
select id from t1 order by a limit 99000,2命中索引idx_a,type为index,无filesort,仅扫描99002条索引记录(远少于全表扫描); - 主查询:通过主键
id关联,type为eq_ref(主键等值匹配,性能最优),rows仅为2行,无额外性能损耗。
适用场景:所有需要按非主键字段排序的分页查询,尤其适合数据量超过10万级的表。
五、总结:不同场景的分页查询选型
| 分页场景 | 推荐方案 | 优点 | 注意事项 |
|---|---|---|---|
| 主键自增且连续、按id排序 | where id > offset and id <= offset+size | 无无效扫描,性能最优 | 主键必须连续,无删除操作 |
| 非主键字段排序 | 子查询查id + 主键关联查详情 | 避免filesort,减少扫描行数 | 需为排序字段创建索引 |
| 主键不连续、按id排序 | 保留普通limit,或结合覆盖索引 | 结果准确,兼容性强 | 可通过“覆盖索引”减少全表扫描范围 |
通过以上优化方案,可有效解决mysql分页查询在大数据量下的性能问题,实际项目中需根据业务场景(排序字段、主键连续性)选择合适的方案,并结合索引设计进一步提升性能。
以上就是mysql分页查询优化的实践指南的详细内容,更多关于mysql分页查询优化的资料请关注代码网其它相关文章!






发表评论