1、应用场景
日常开发中,对于一个数据想做到存在即更新,不存在则新增,通常的做法是先查询数据库中是否存在对应的数据,如果存在就使用更新的方法,不存在就使用新增的方法
如果是单个数据,倒也没什么问题,但如果是批量数据的话,会消耗大量的资源来进行查询操作,这样就得不偿失了。
这种情况我们可以使用mysql提供的 on duplicate key update 来进行操作。
2、基础使用语法
2.1 假设此时我们表中没有数据
执行语句(为了展示效果使用用法2)
#用法1:使用values来获取值(推荐,因为插入多个的时候可以用) insert into `test` ( id, name ) values( 1, '晓明' ) on duplicate key update id = values(id), name = values(name) #用法2:直接使用值 insert into `user` ( id, name ) values( 1, '晓明') on duplicate key update id = '123', name = 'xiaoming'
- 执行结果

2.2 有数据后再次执行
执行相同sql语句,执行结果

这里就是关键:
我们可以看到变动为2,此时就是说明原数据进行了更新,更新内容为下面update中设置的字段值 ,id也可变化,数据库中数据如下

q:我们再次执行一次这个语句,结果是什么样子呢?
a:自然是判断出该表中无此数据,新增一条额外的新数据
- sql结果
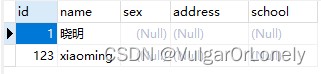
验证得到结论:
其实就是会自动检测是否存在duplicate entry,如果存在values后面的值就会自动更改,不存在则插入
3、批量插入
- 执行语句
insert into test(`id`,`name`,`address`)
values('4','修改10','北京'),
('1', '晓明',1)
on duplicate key update
name=values(name),address=values(address);- sql结果
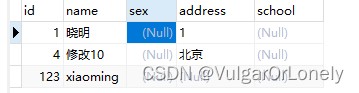
id为1和id为4的分别被修改和新增,可以同时进行两种操作类型
4、mybatis中的写法
- 单独插入
<insert id="insertuser" parametertype="com.test.user">
insert into user(
id,
name,
gender,
birthday,
address)
values
(#{id},
#{name},
#{gender},
#{birthday},
#{address})
on duplicate key update
id = values(id),
name = values(name),
gender = values(gender)
birthday = values(birthday),
address = values(address)
</insert>
- 批量插入
<insert id="insertuser" parametertype="java.util.list">
insert into user(
id,
name,
gender,
birthday,
address)
values
<foreach collection="list" item="item" index="index" separator=",">
(#{item.id},
#{item.name},
#{item.gender},
#{item.birthday},
#{item.address})
</foreach>
on duplicate key update
id = values(id),
name = values(name),
gender = values(gender)
birthday = values(birthday),
address = values(address)
</insert>
5、情景模拟
插入失败提示如下
error 1062 (23000): duplicate entry 'value' for key 'primary'
如果数据库中已有某条数据,以下的两条语句可等同:
insert into tablename (id, data) values (1, 10) on duplicate key update data=data+10;
update tablename set data=data+10 where id=1;
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论