相信很多坐在办公室上班的朋友每天都需要处理大量的数据,我们常常用excel制作电子表格来帮助我们处理它们。这当然是一种非常好的做法,但是我相信大家都会发现,很多表格的内容其实大同小异,常常需要我们把同样的数据复制进不同的表格里去,整理格式,然后提交给不同的人。这样没有意义的重复劳动会占用我们大量宝贵的时间。如果有什么人能帮我们把表格做好,我们只需确认一下是否有误然后提交即可,那么生活将会变得多么美好。
openpyxl就是这样一个得力的工具。
这是一个由eric gazoni和charlie clark开发的,是目前使用最广泛的用python操作excel的库开源库,也是pandas中默认读取表格数据的工具。
那么这个系列的文章——python帮你做excel——就是给大家提供一个简单的openpyxl的入门中文教程,让大家能快速上手这个好用的小工具。
首先让我们一起看一下,如何使用openpyxl读取excel文档中的数据。
openpyxl基础概念
- excel文件通常被称为电子表格,但在openpyxl中被称为工作簿
- 单个工作簿通常保存在扩展名为.xlsx的文件中
- 一个工作簿可能只有一个工作表,也可能有几十个工作表
- 活动工作表是用户正在查看或关闭文件前查看的工作表
- 每个工作表都由列组成,列的名字从a开始依次类推
- 每个工作表都由行组成,每个行从1开始编号,依次类推
- 行与列的交界处称为单元格。每个单元格对于对应的行和列就有了特定的地址。单元格内可以包含数字,公式或者文字
- 单元格组成的网格在excel中组成了工作区域或者说工作表
从excel工作表中读取数据
首先我们假设建一个excel文件,命名为testfile.xlsx。
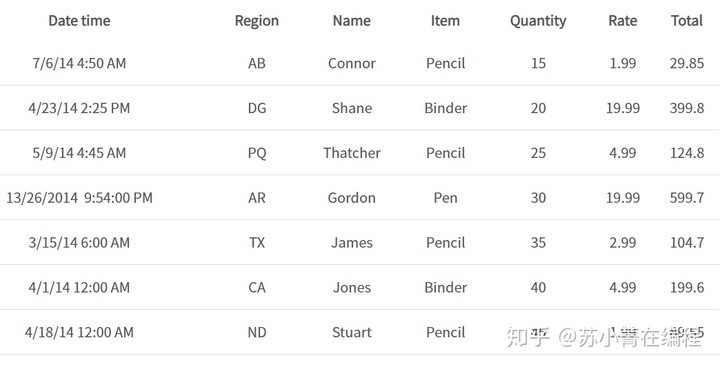
以上是testfile.xlsx的数据,你可以新建一个excel文件并把数据填进去。 不过在正式使用openpyxl读取这些数据之前,如果你不知道python的根目录在哪,你可以在prompt(中文可以理解为命令提示符,或对话框)中输入如下代码
import os os.getcwd( )
上述操作会在python中导入操作系统包,然后os.getcwd( )会读取当下的工作地址(get current working directory ——> getcwd() )。随后python会告诉你当下的工作地址,输出的结果可能会是这样
'c:python36'
如果你想更换工作地址,就需要使用命令os.chdir()。比如你想读取一个在c盘根目录下的一个叫做myfiles的文件夹里的文件,那么你可能就可以输入
os.ch.dir("c:/myfiles")现在你就可以对c盘里myfiles文件夹里的文件进行工作了!
用python打开excel文件
首先我们需要用这个语句在python中导入openpyxl模块
import openpyxl
如果没有错误信息提示,那就表示openpyxl模块安装正确,并且可以对excel文件进行操作了。接下来需要做的是载入工作簿testfile.xlsx
wb= openpyxl.load_workbook('testfile.xlsx')
openpyxl.load_workbook()是一个函数,它将文件名作为参数读入然后返回一个工作簿的数据类型(workbook datatype)。工作簿数据类型实际上与python打开文件对象的类型是一样的,使用下述的语句可以看到对handle的说明:
type (wb) <class 'openpyxl.workbook.workbook.workbook'>
上面的第二行文字应该会显示在对话框中,此处我们对前面所有输入的命令进行个简单的汇总展示
>>> import os
>>> os.getcwd()
'c:python34'
>>> import openpyxl
>>> wb=openpyxl.load_workbook('testfile.xlsx')
>>> type(wb)
<class 'openpyxl.workbook.workbook.workbook'>
>>>从加载的工作簿访问工作表
现在我们已经能够访问excel文件了,现在我们可以尝试读取文件里的数据。首先,如果想要访问工作簿中工作表的数量以及它们的名字,可以使用函数get_sheet_names()。这个函数会返回工作表的名字,当然你也可以数出工作表的总数。完整的代码是这样的
>>> wb.get_sheet_names() ['sheet1', 'sheet2', 'sheet3']
可以看到函数返回了三个工作表的名字,也就是说工作簿内只含有三个工作表。那么现在你可以尝试多操作几次,比如手动修改这些工作表的名字,然后保存文件,随后用上述代码重新加载文件,看看工作表的名字是否有变动,当然此处就不再多加赘述了。 在知道了工作表的名字之后,我们可以访问其中的任何一个工作表了。假设我们想要访问sheet3,代码就应该是
>>> import openpyxl
>>> wb=openpyxl.load_workbook('testfile.xlsx')
>>> wb.get_sheet_names()
['sheet1', 'sheet2', 'sheet3']
>>> sheet=wb.get_sheet_by_name('sheet3')函数get_sheet_by_name('sheet3')可以访问一个特定的工作表,它接收工作表的名字作为输入,然后返回一个工作表对象。我们将其赋值给sheet变量,然后就可以对它进行下述操作
>>> sheet <worksheet "sheet3"> >>> type(sheet) <class 'openpyxl.worksheet.worksheet.worksheet'> >>> sheet.title 'sheet3' >>>
如果只输入sheet,那么就会输出,该变量指向哪个工作表。在这里例子里,对话框就会返回工作表"sheet3"。如果想要知道该变量的类型,则输入type(sheet),此时就会返回变量sheet指向什么对象。sheet.title会返回sheet的标题。 另外,如果我们想访问活动的工作表,可以使用下述代码,对话框就会返回活动工作表的名字了
>>> wb.active <worksheet "sheet1">
访问工作表单元格中的数据
从工作表单元格中访问数据,首先应用工作表,然后输入单元格的地址,具体展示如下
>>> sheet['a2'].value datetime.datetime(2014, 7, 6, 4, 50, 30)
还有访问单元格数据的另一个方法
>>> e=sheet['b2'] >>> e.value 'ab' >>> e.row 2 >>> e.column 'b' >>>
还可以使用cell()函数,将row和column作为参数输入,读取单元格数据
>>> sheet.cell(row=2, column=4) <cell sheet1.d2> >>> sheet.cell(row=2, column=4).value 'pencil'
现在让我们来尝试输出整列的数据,当然,此处需要使用到循环语句。输出整个列的代码展示如下
>>> for x in range (1,9):
print(x,sheet.cell(row=x,column=4).value)
1 item
2 pencil
3 binder
4 pencil
5 pen
6 pencil
7 binder
8 pencil
>>>在输出了整列数据后,现在可以尝试输出多列的数据了。由于我们的文件很小,所以我们就输出完整的表格。详见下方代码
for y in range (1,9,1): print(sheet.cell(row=y,column=1).value,sheet.cell(row=y,column=2).value, sheet.cell(row=y,column=3).value,sheet.cell(row=y,column=4).value, sheet.cell(row=y,column=5).value, sheet.cell(row=y,column=6).value, sheet.cell(row=y,column=7).value,sheet.cell(row=y,column=8).value)
这些代码可以输出工作表中的所有列,那么至此,我们已经访问了excel文件,将其载入内存,访问工作表以及单元格里的数据。
到此这篇关于使用python实现读取文件夹中所有excel的文章就介绍到这了,更多相关python读取文件夹中所有excel内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论