python 办公自动化完全指南:excel、pdf 与 word
在日常工作中,处理 excel 表格、pdf 文档和 word 文档是必不可少的任务。python 提供了强大的第三方库来帮助我们自动化这些重复性工作,极大提高效率。本文将详细介绍如何使用 openpyxl 操作 excel,使用 pypdf2 和 pdfplumber 操作 pdf,以及使用 python-docx 操作 word。
章节一:python 使用 openpyxl 操作 excel
openpyxl 是一个用于读写 excel 2010 xlsx/xlsm/xltx/xltm 文件的 python 库。
1、openpyxl 库介绍
- 安装:
pip install openpyxl
- 核心概念:
workbook: 工作簿(整个 excel 文件)worksheet: 工作表(sheet)cell: 单元格
2、python 怎么打开及读取表格内容?
1)excel 表格术语
- workbook: excel 文件对象
- sheet: 表单
- row: 行(从 1 开始)
- column: 列(从 a 开始或从 1 开始)
- cell: 单元格
2)打开 excel 表格并获取表格名称
from openpyxl import load_workbook
# 加载工作簿
wb = load_workbook('example.xlsx')
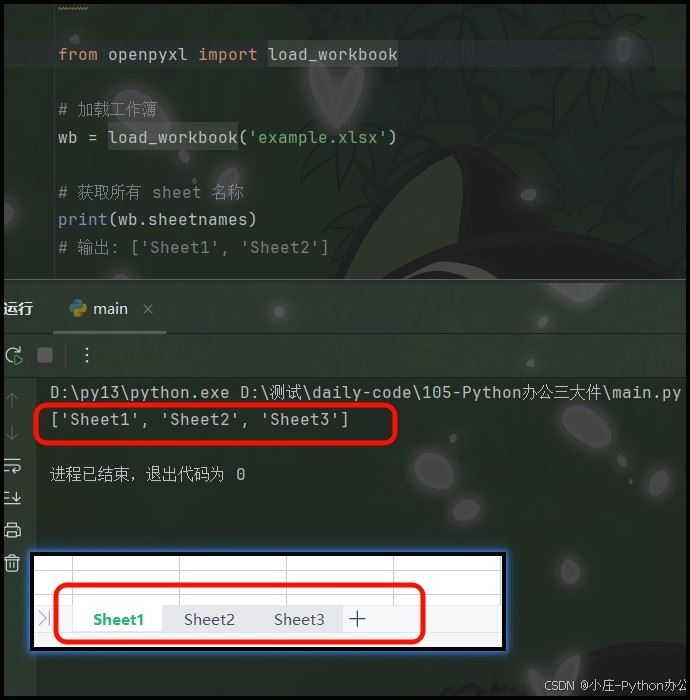
# 获取所有 sheet 名称
print(wb.sheetnames)
# 输出: ['sheet1', 'sheet2']
3)通过 sheet 名称获取表格
# 获取特定的 sheet ws = wb['sheet1'] # 或者获取当前活跃的 sheet ws_active = wb.active print(ws.title)
4)获取表格的尺寸大小
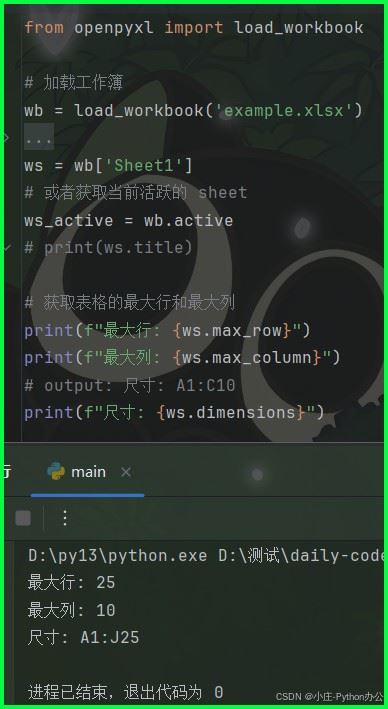
# 获取表格的最大行和最大列
print(f"最大行: {ws.max_row}")
print(f"最大列: {ws.max_column}")
# output: 尺寸: a1:c10
print(f"尺寸: {ws.dimensions}")
5)获取表格内某个格子的数据
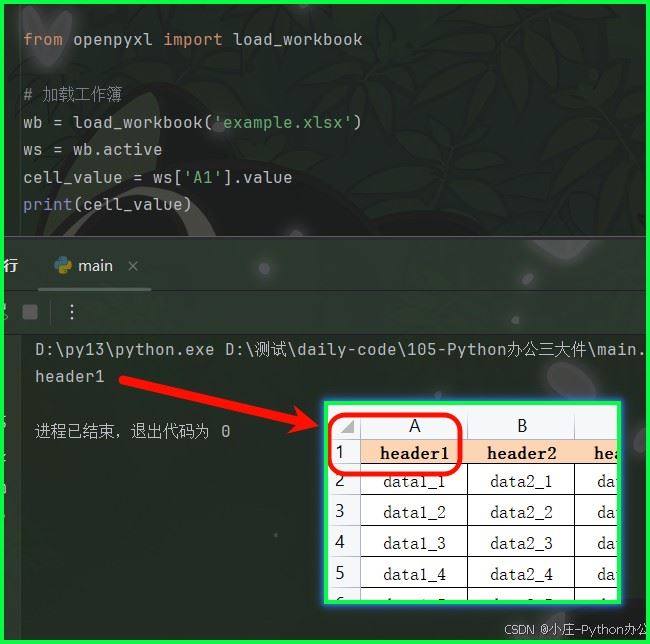
① sheet[“a1”] 方式
cell_value = ws['a1'].value print(cell_value)
② sheet.cell(row=, column=) 方式
# 注意:row 和 column 都是从 1 开始 cell_value = ws.cell(row=1, column=1).value print(cell_value)
6)获取某个格子的行数、列数、坐标
c = ws['b2']
print(f"行: {c.row}, 列: {c.column}, 坐标: {c.coordinate}")
7)获取一系列格子
① sheet[] 方式
# 获取 a 列
col_a = ws['a']
# 获取 a 到 c 列
col_range = ws['a:c']
# 获取第 1 行
row_1 = ws[1]
# 获取 a1 到 c3 的区域
cell_range = ws['a1:c3']
for row in cell_range:
for cell in row:
print(cell.value)
② .iter_rows() 方式
按行迭代,返回生成器,效率更高。
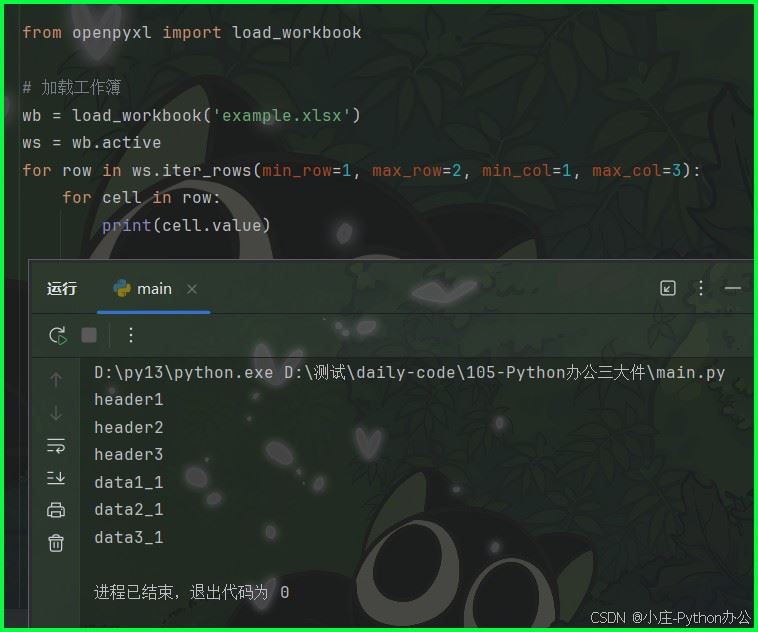
for row in ws.iter_rows(min_row=1, max_row=2, min_col=1, max_col=3):
for cell in row:
print(cell.value)
③ sheet.rows
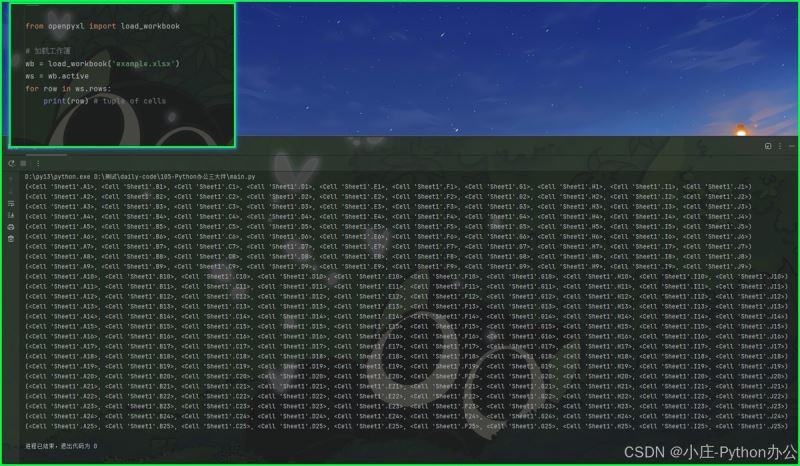
返回所有行的生成器。
for row in ws.rows:
print(row) # tuple of cells
3、python 如何向 excel 中写入某些内容?
1)修改表格中的内容
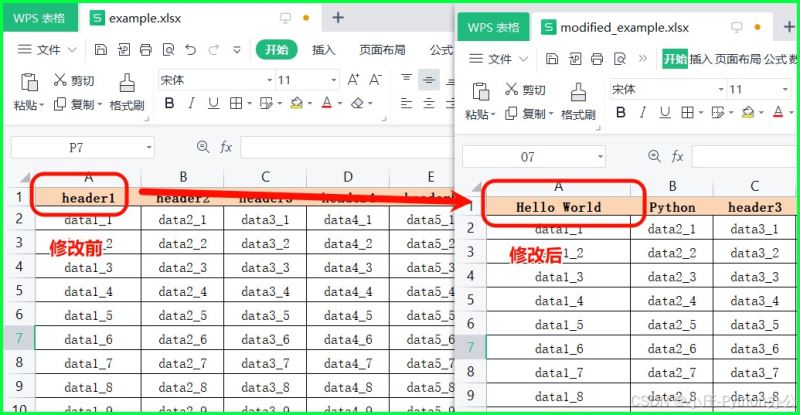
① 向某个格子中写入内容并保存
ws['a1'] = 'hello world'
ws.cell(row=1, column=2, value='python')
# 保存文件(如果是修改现有文件,建议另存为新文件名以防数据丢失)
wb.save('modified_example.xlsx')
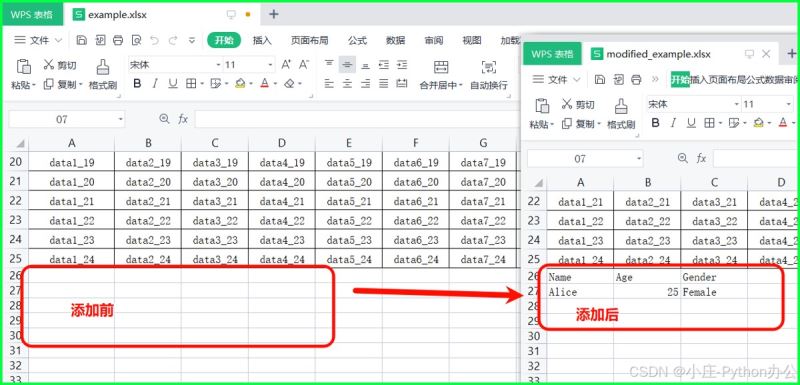
② .append():向表格中插入行数据
非常常用的方法,用于在表格末尾追加一行数据。
# 添加一行数据 ws.append(['name', 'age', 'gender']) ws.append(['alice', 25, 'female'])
③ 在 python 中使用 excel 函数公式
ws['c1'] = 10 ws['c2'] = 20 ws['c3'] = '=sum(c1:c2)' # 写入公式
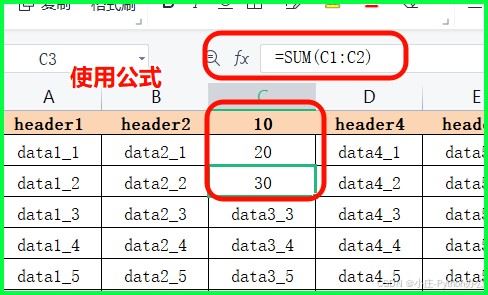
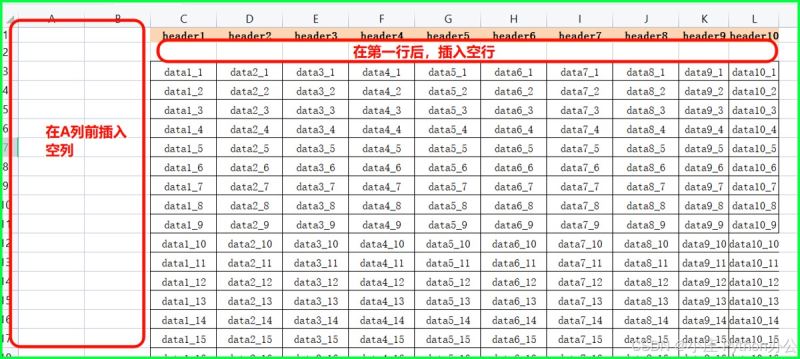
④ .insert_cols() 和 .insert_rows():插入空行和空列
ws.insert_rows(idx=2, amount=1) # 在第2行前插入1行 ws.insert_cols(idx=1, amount=2) # 在第1列前插入2列
⑤ .delete_rows() 和 .delete_cols():删除行和列
ws.delete_rows(idx=2, amount=1) # 删除第2行 ws.delete_cols(idx=1, amount=1) # 删除第1列
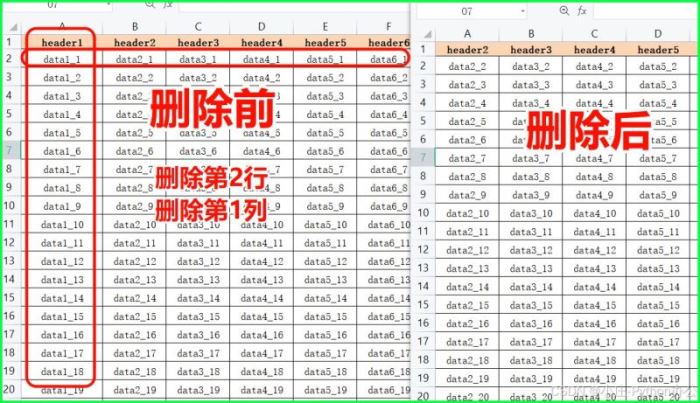
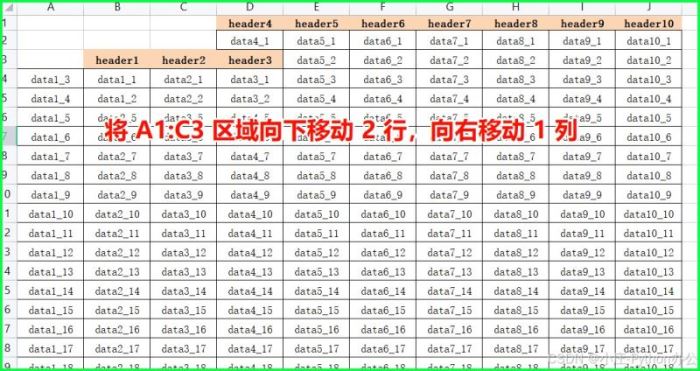
⑥ .move_range():移动格子
# 将 a1:c3 区域向下移动 2 行,向右移动 1 列
ws.move_range("a1:c3", rows=2, cols=1)
⑦ .create_sheet():创建新的 sheet 表格
ws_new = wb.create_sheet("newsheet", index=0) # index=0 插入到最前面

⑧ .remove():删除某个 sheet 表
del wb['newsheet'] # 或者 # wb.remove(wb['newsheet'])
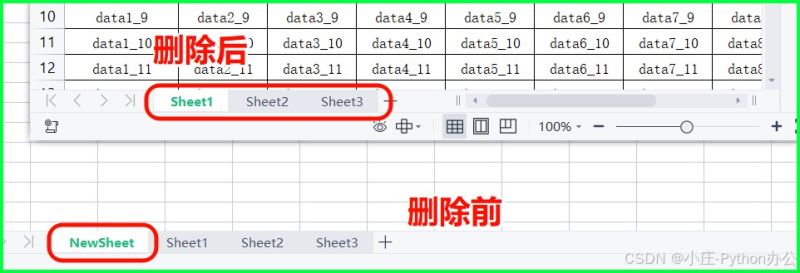
⑨ .copy_worksheet():复制一个 sheet 表
source = wb.active target = wb.copy_worksheet(source) target.title = "copy of active"
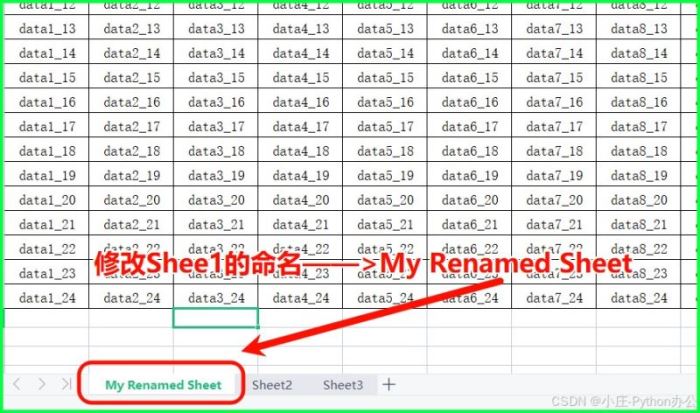
⑩ sheet.title:修改 sheet 表的名称
ws.title = "my renamed sheet"
⑪ 创建新的 excel 表格文件
from openpyxl import workbook
wb_new = workbook()
ws_new = wb_new.active
ws_new.title = "data"
wb_new.save("new_file.xlsx")
wb.save('modified_example.xlsx')
⑫ sheet.freeze_panes:冻结窗口
ws.freeze_panes = 'a2' # 冻结第一行 # ws.freeze_panes = 'b1' # 冻结第一列

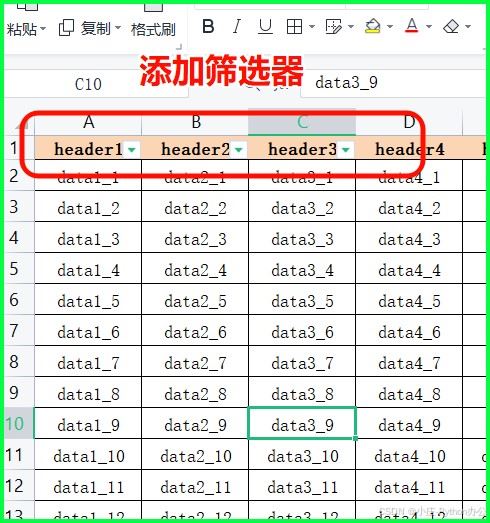
⑬ sheet.auto_filter.ref:给表格添加“筛选器”
from openpyxl import load_workbook
wb = load_workbook('example.xlsx')
ws = wb.active
ws.auto_filter.ref = ws.dimensions # 给所有有数据的区域添加筛选
# 或者指定区域
ws.auto_filter.ref = "a1:c10"
wb.save('modified_example.xlsx')
4、批量调整字体和样式
需要导入 openpyxl.styles 模块。
1)修改字体样式
from openpyxl.styles import font
ws = wb.active
# 粗体,斜体,红色,字号20
font_style = font(name='arial', size=20, bold=true, italic=true, color='ff0000')
ws['a1'].font = font_style
wb.save('modified_example.xlsx')
2)获取表格中格子的字体样式
current_font = ws['a1'].font print(current_font.name, current_font.size)
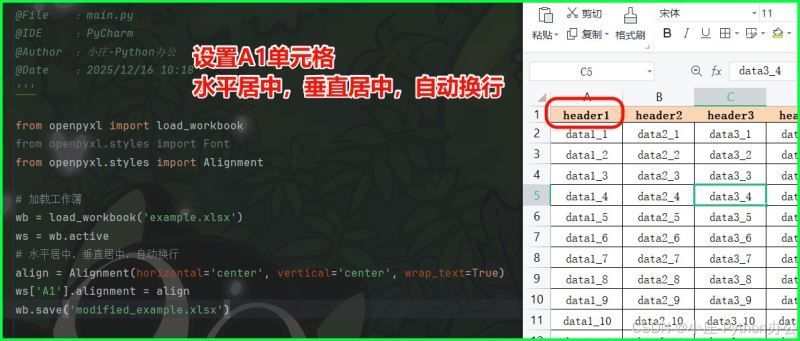
3)设置对齐样式
from openpyxl.styles import alignment
# 水平居中,垂直居中,自动换行
align = alignment(horizontal='center', vertical='center', wrap_text=true)
ws['a1'].alignment = align
wb.save('modified_example.xlsx')
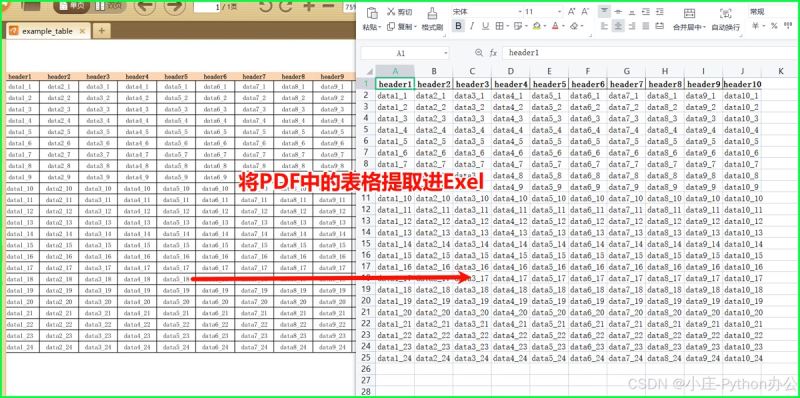
4)设置边框样式
from openpyxl import load_workbook
from openpyxl.styles import border, side
wb = load_workbook('example.xlsx')
ws = wb.active
# 使用双线边框,视觉上看起来更粗
double_border = side(border_style="double", color="ff0000")
border = border(left=double_border,
right=double_border,
top=double_border,
bottom=double_border)
ws['a1'].border = border
wb.save('modified_example.xlsx')
"thin" - 细边框
"medium" - 中等粗细
"thick" - 粗边框
"double" - 双线边框
"hair" - 极细边框
"dashed" - 虚线边框
"dotted" - 点线边框等
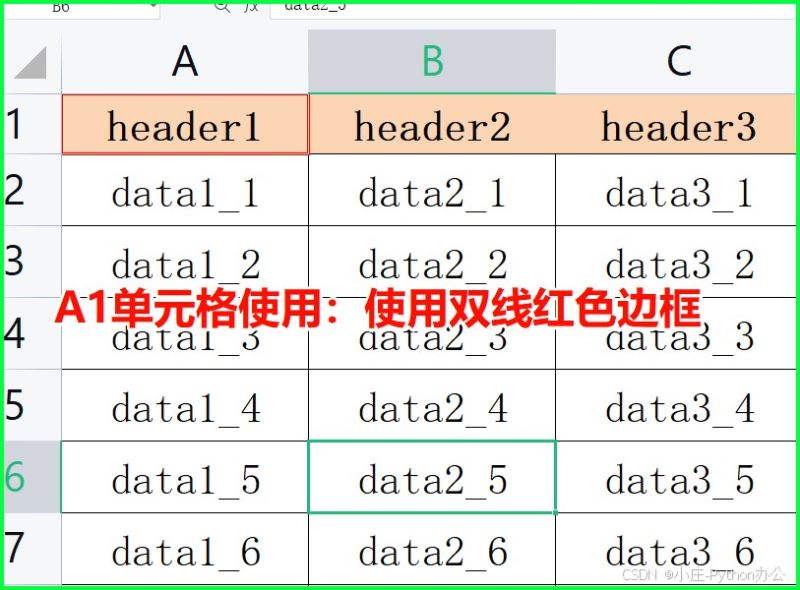
5)设置填充样式
from openpyxl import load_workbook
from openpyxl.styles import patternfill
# 加载工作簿
wb = load_workbook('example.xlsx')
ws = wb.active
# 黄色背景填充
fill = patternfill(start_color="ffff00", end_color="ffff00", fill_type="solid")
ws['a1'].fill = fill
# 保存修改
wb.save('modified_example.xlsx')
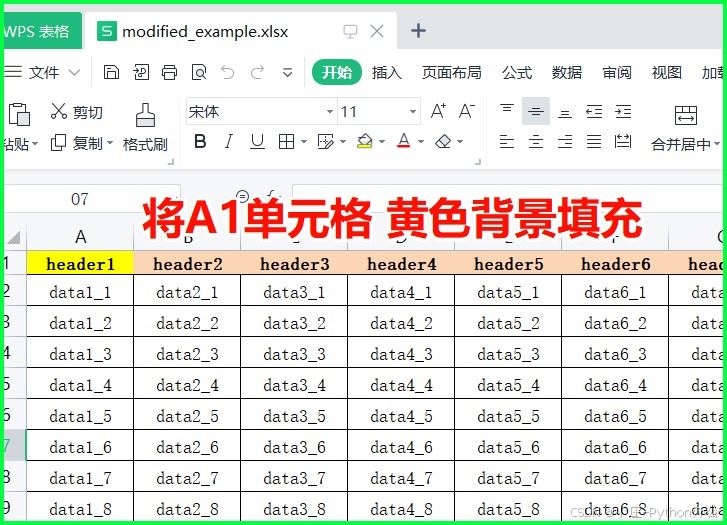
6)设置行高和列宽
from openpyxl import load_workbook
# 加载工作簿
wb = load_workbook('example.xlsx')
ws = wb.active
ws.row_dimensions[1].height = 30 # 设置第1行高度
ws.column_dimensions['a'].width = 20 # 设置a列宽度
# 保存修改
wb.save('modified_example.xlsx')
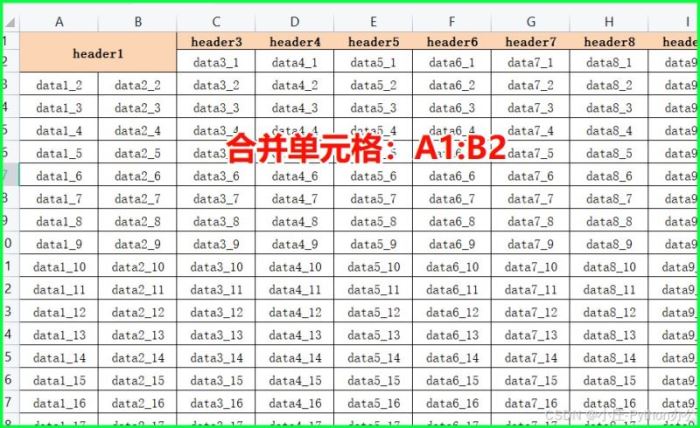
7)合并单元格
from openpyxl import load_workbook
# 加载工作簿
wb = load_workbook('example.xlsx')
ws = wb.active
ws.merge_cells('a1:b2')
# 或者
# ws.merge_cells(start_row=1, start_column=1, end_row=2, end_column=2)
# 取消合并
# ws.unmerge_cells('a1:b2')
# 保存修改
wb.save('modified_example.xlsx')
章节二:python 使用 pypdf2 和 pdfplumber 操作 pdf
1、pypdf2 和 pdfplumber 库介绍
pypdf2: 主要用于合并、拆分、旋转、加密 pdf 等页面级操作,提取文本能力较弱。
pdfplumber: 专注于提取 pdf 中的文本和表格,准确率较高。
安装:
pip install pypdf2 pdfplumber
2、python 提取 pdf 文字内容
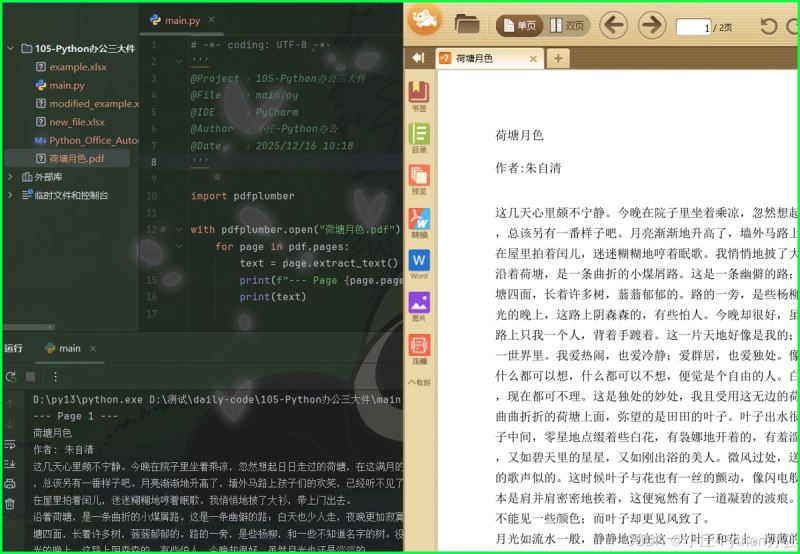
1)利用 pdfplumber 提取文字
import pdfplumber
with pdfplumber.open("荷塘月色.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()
print(f"--- page {page.page_number} ---")
print(text)
2)利用 pdfplumber 提取表格并写入 excel
import pdfplumber
import pandas as pd
with pdfplumber.open("example_table.pdf") as pdf:
page = pdf.pages[0] # 假设表格在第一页
table = page.extract_table()
if table:
df = pd.dataframe(table[1:], columns=table[0]) # 假设第一行是表头
df.to_excel("output_table.xlsx", index=false)
3、pdf 合并及页面的排序和旋转
使用 pypdf2 进行操作。
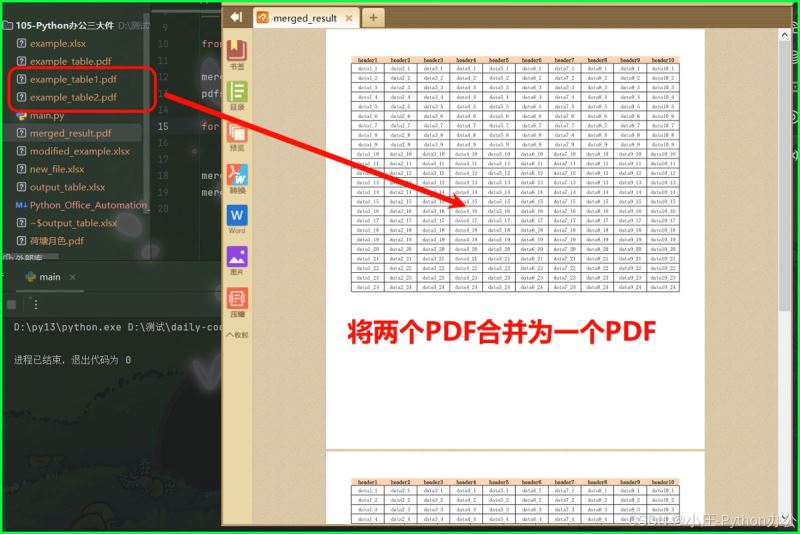
1)分割及合并 pdf
① 合并 pdf
from pypdf2 import pdfmerger
merger = pdfmerger()
pdfs = ['example_table1.pdf', 'example_table2.pdf']
for pdf in pdfs:
merger.append(pdf)
merger.write("merged_result.pdf")
merger.close()
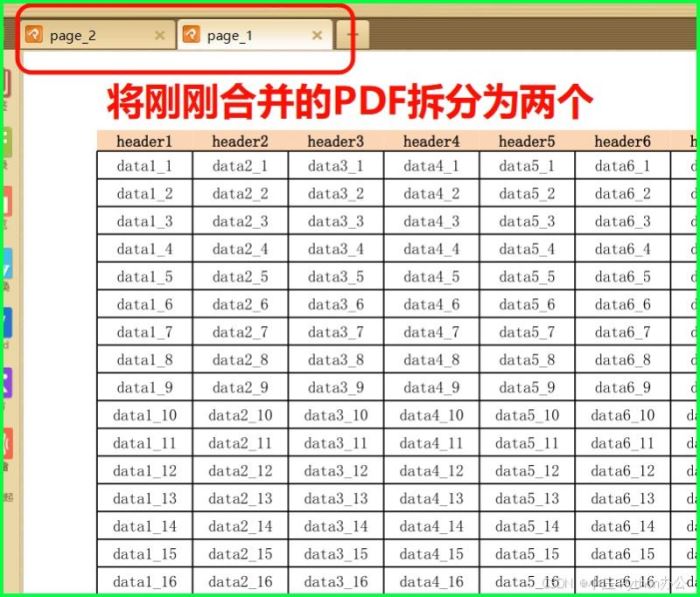
② 拆分 pdf
from pypdf2 import pdfreader, pdfwriter
reader = pdfreader("merged_result.pdf")
for i, page in enumerate(reader.pages):
writer = pdfwriter()
writer.add_page(page)
with open(f"page_{i+1}.pdf", "wb") as f:
writer.write(f)
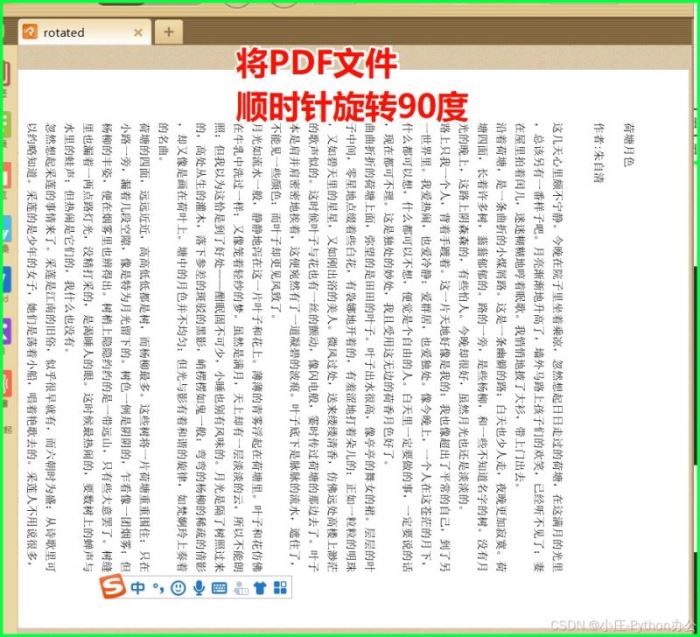
2)旋转及排序 pdf
① 旋转 pdf
from pypdf2 import pdfreader, pdfwriter
reader = pdfreader("荷塘月色.pdf")
writer = pdfwriter()
page = reader.pages[0]
page.rotate(90) # 顺时针旋转90度
writer.add_page(page)
with open("rotated.pdf", "wb") as f:
writer.write(f)
② 排序 pdf
可以通过调整 add_page 的顺序来实现。
# 假设倒序保存
from pypdf2 import pdfreader, pdfwriter
reader = pdfreader("荷塘月色.pdf")
writer = pdfwriter()
for page in reversed(reader.pages):
writer.add_page(page)
with open("reversed.pdf", "wb") as f:
writer.write(f)

4、pdf 批量加水印及加密、解密
1)批量加水印
原理:将水印页面作为“印章”盖在每一页上。
from pypdf2 import pdfreader, pdfwriter
watermark = pdfreader("watermark.pdf").pages[0]
reader = pdfreader("content.pdf")
writer = pdfwriter()
for page in reader.pages:
page.merge_page(watermark) # 合并页面
writer.add_page(page)
with open("watermarked.pdf", "wb") as f:
writer.write(f)
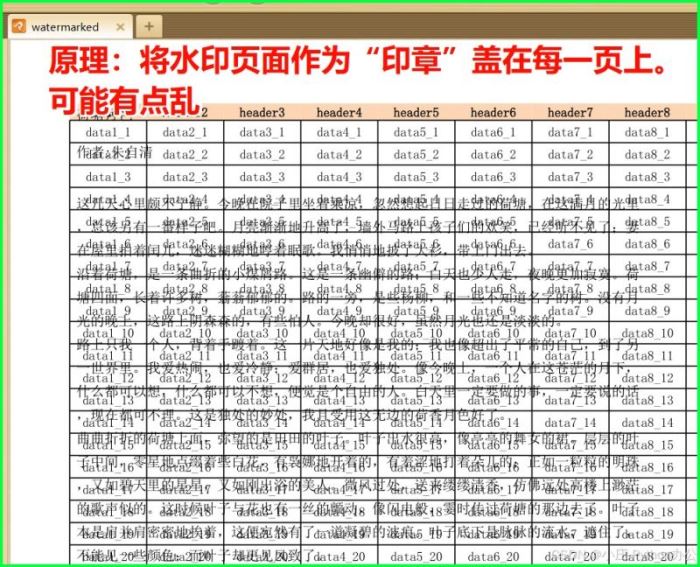
2)批量加密、解密
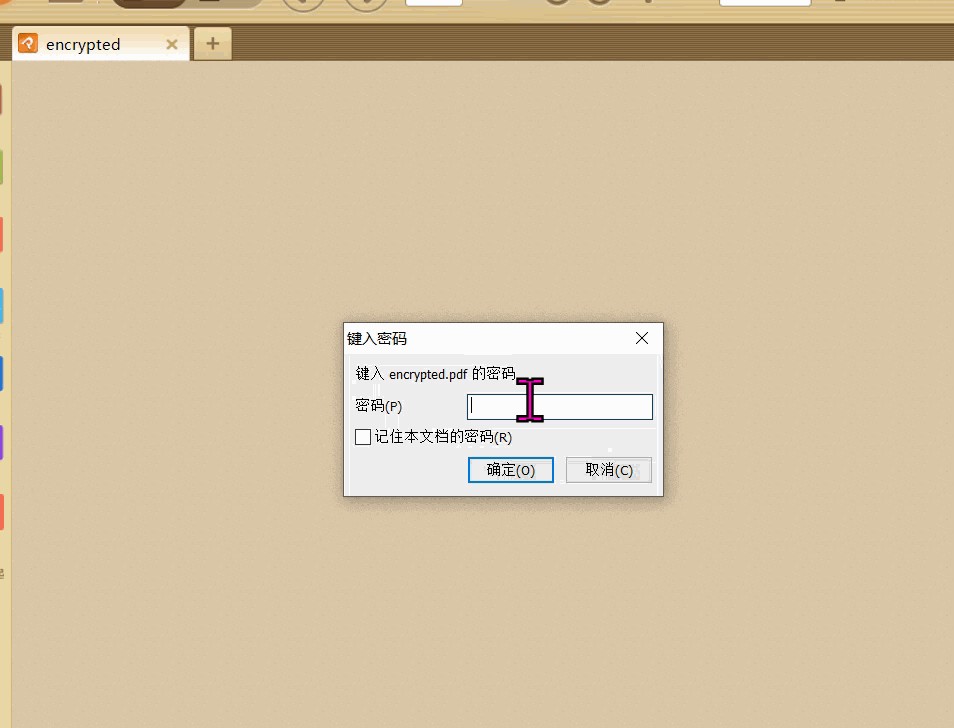
① 加密 pdf
from pypdf2 import pdfreader, pdfwriter
writer = pdfwriter()
reader = pdfreader("荷塘月色.pdf")
for page in reader.pages:
writer.add_page(page)
writer.encrypt("password123") # 设置密码
with open("encrypted.pdf", "wb") as f:
writer.write(f)
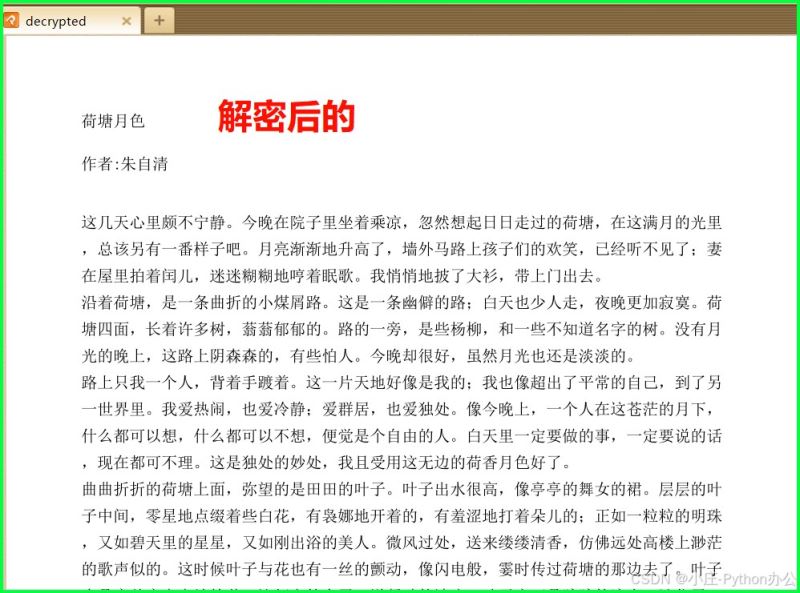
② 解密 pdf 并保存为未加密的 pdf
from pypdf2 import pdfreader, pdfwriter
reader = pdfreader("encrypted.pdf")
if reader.is_encrypted:
reader.decrypt("password123")
writer = pdfwriter()
for page in reader.pages:
writer.add_page(page)
with open("decrypted.pdf", "wb") as f:
writer.write(f)
章节三:python 使用 python-docx 操作 word
1、python-docx 库介绍
- 用途:用于创建和更新 .docx 文件。
- 安装:
pip install python-docx
2、python 读取 word 文档内容
1)word 文档结构介绍
- document: 整个文档
- paragraph: 段落(回车符分隔)
- run: 文本块(具有相同样式的连续文本)
2)python-docx 提取文字和文字块儿
① python-docx 提取文字
from docx import document
doc = document("example.docx")
full_text = []
for para in doc.paragraphs:
full_text.append(para.text)
print("\n".join(full_text))
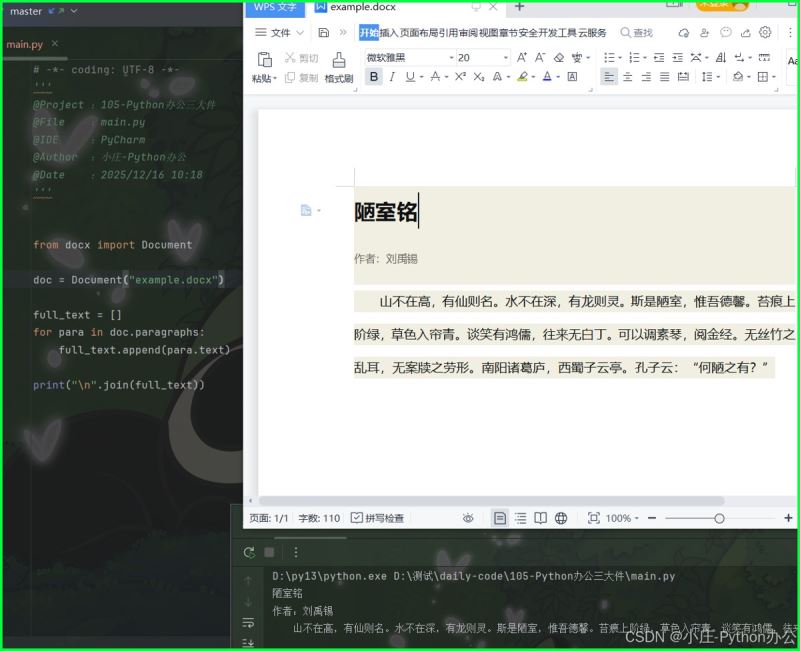
② python-docx 提取文字块儿
from docx import document
doc = document("example.docx")
for para in doc.paragraphs:
for run in para.runs:
print(run.text) # 打印每个样式块的文本
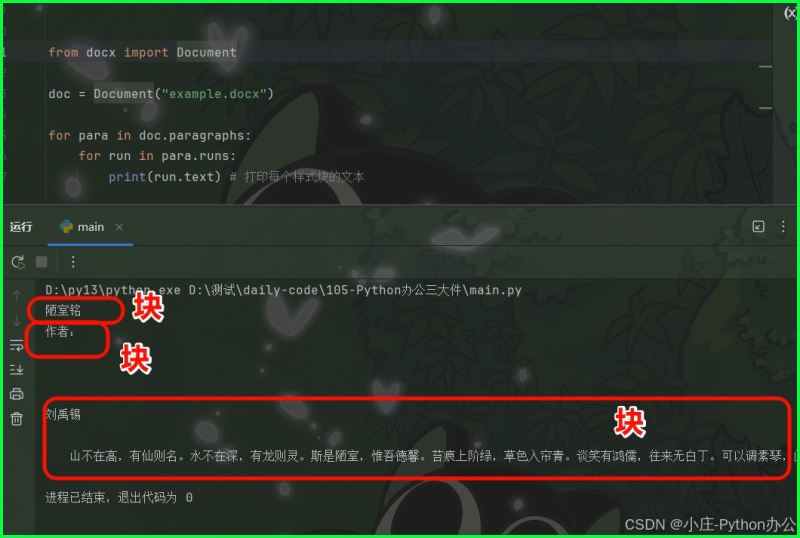
3)利用 python 向 新建word 文档写入内容
① 添加段落
from docx import document
doc = document()
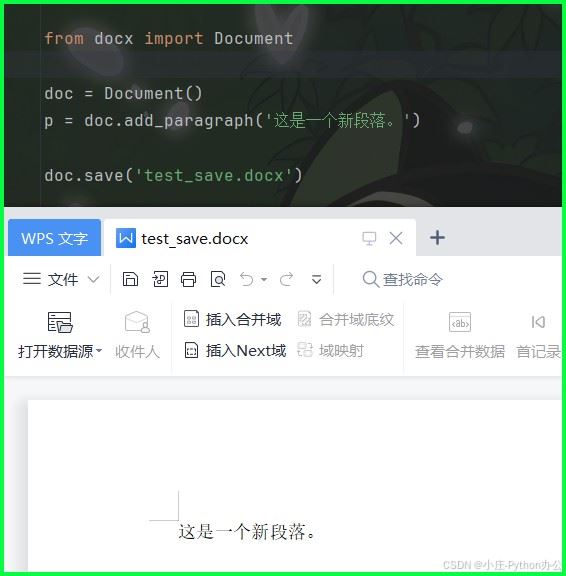
p = doc.add_paragraph('这是一个新段落。')
doc.save('test_save.docx')
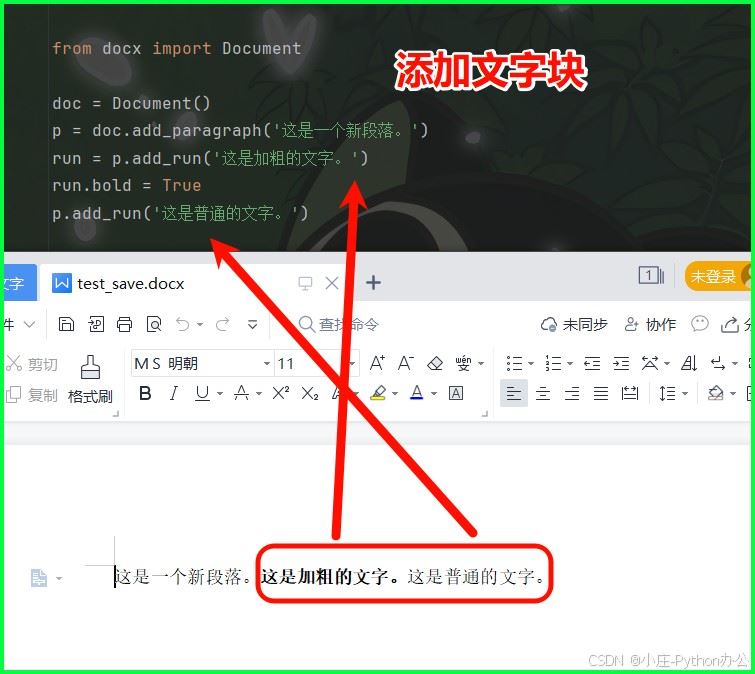
② 添加文字块儿
from docx import document
doc = document()
p = doc.add_paragraph('这是一个新段落。')
run = p.add_run('这是加粗的文字。')
run.bold = true
p.add_run('这是普通的文字。')
doc.save('test_save.docx')
③ 添加一个分页
from docx import document
doc = document()
p = doc.add_paragraph('这是一个新段落。')
run = p.add_run('这是加粗的文字。')
run.bold = true
p.add_run('这是普通的文字。')
doc.add_page_break()
doc.save('test_save.docx')

④ 添加图片
from docx import document
from docx.shared import inches
doc = document()
p = doc.add_paragraph('这是一个新段落。')
run = p.add_run('这是加粗的文字。')
run.bold = true
p.add_run('这是普通的文字。')
# doc.add_page_break()
doc.add_picture('img.jpg', width=inches(1.25)) # 需要 from docx.shared import inches
doc.save('test_save.docx')

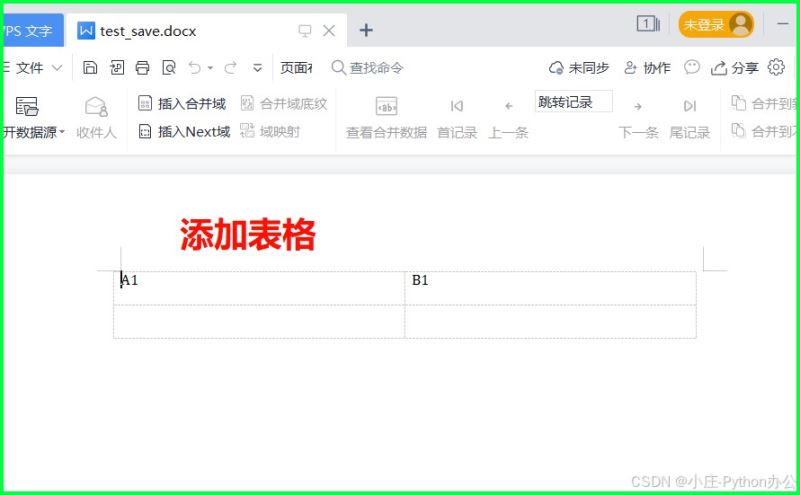
⑤ 添加表格
from docx import document
doc = document()
table = doc.add_table(rows=2, cols=2)
table.cell(0, 0).text = "a1"
table.cell(0, 1).text = "b1"
doc.save('test_save.docx')
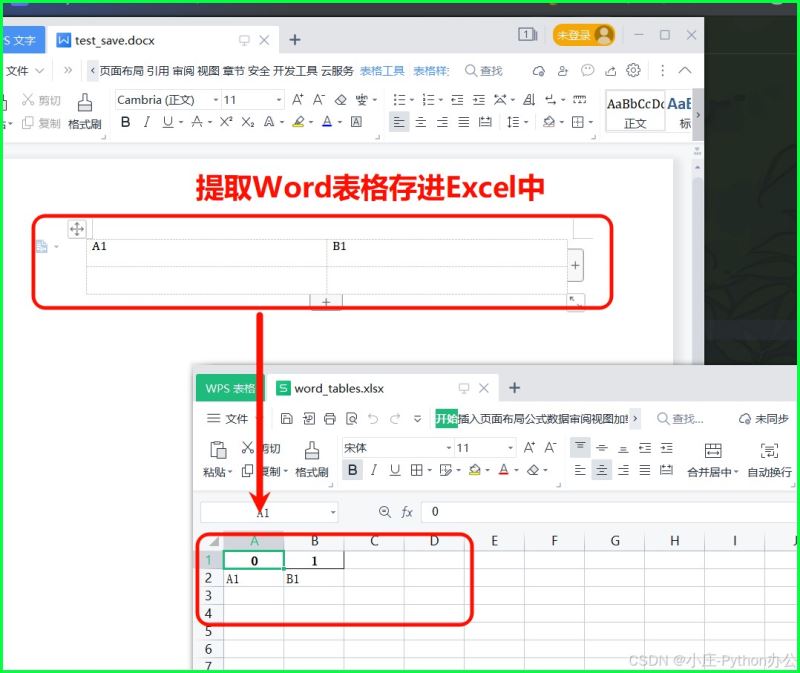
⑥ 提取 word 表格,并保存在 excel 中
import pandas as pd
from docx import document
doc = document("test_save.docx")
tables_data = []
for table in doc.tables:
for row in table.rows:
row_data = [cell.text for cell in row.cells]
tables_data.append(row_data)
df = pd.dataframe(tables_data)
df.to_excel("word_tables.xlsx", index=false)
3、利用 python 调整 word 文档样式
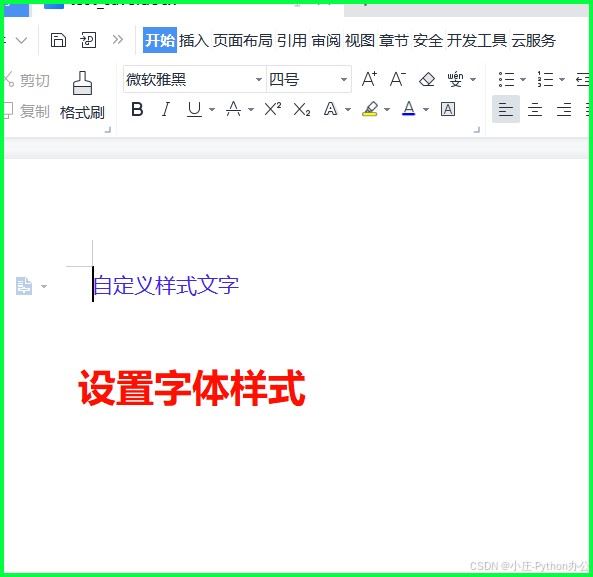
1)修改文字字体样式
from docx import document
from docx.shared import pt, rgbcolor
from docx.oxml.ns import qn
doc = document()
p = doc.add_paragraph()
run = p.add_run('自定义样式文字')
run.font.size = pt(14)
run.font.color.rgb = rgbcolor(0x42, 0x24, 0xe9)
# 设置中文字体需要特殊处理
run.font.name = '微软雅黑'
run._element.rpr.rfonts.set(qn('w:eastasia'), '微软雅黑')
doc.save('test_save.docx')
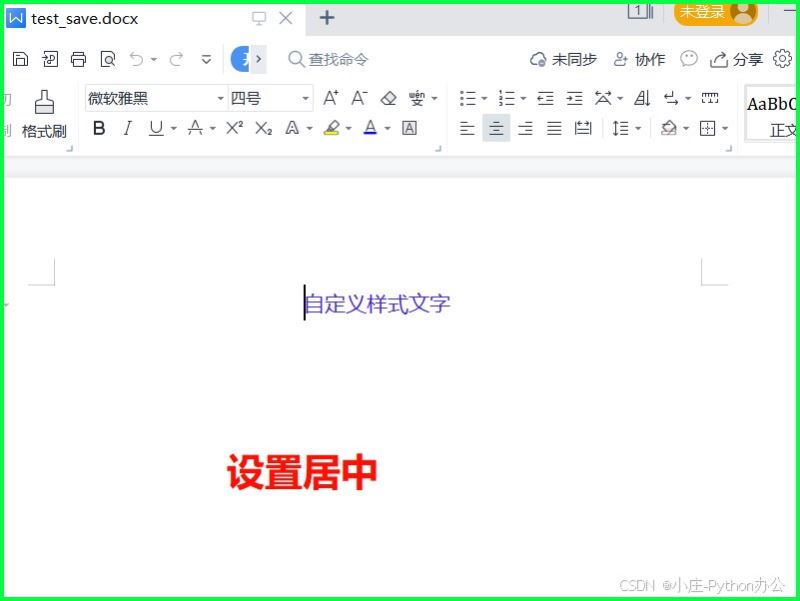
2)修改段落样式
① 对齐样式
from docx import document
from docx.shared import pt, rgbcolor
from docx.oxml.ns import qn
from docx.enum.text import wd_align_paragraph
doc = document()
p = doc.add_paragraph()
run = p.add_run('自定义样式文字')
run.font.size = pt(14)
run.font.color.rgb = rgbcolor(0x42, 0x24, 0xe9)
# 设置中文字体需要特殊处理
run.font.name = '微软雅黑'
run._element.rpr.rfonts.set(qn('w:eastasia'), '微软雅黑')
p.alignment = wd_align_paragraph.center # 居中
doc.save('test_save.docx')
② 行间距调整
from docx import document
from docx.shared import pt, rgbcolor
from docx.oxml.ns import qn
from docx.enum.text import wd_align_paragraph
doc = document()
p = doc.add_paragraph()
run = p.add_run('自定义样式文字测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试')
run.font.size = pt(14)
run.font.color.rgb = rgbcolor(0x42, 0x24, 0xe9)
# 设置中文字体需要特殊处理
run.font.name = '微软雅黑'
run._element.rpr.rfonts.set(qn('w:eastasia'), '微软雅黑')
p.alignment = wd_align_paragraph.center # 居中
p.paragraph_format.line_spacing = 1.5 # 1.5倍行距
doc.save('test_save.docx')

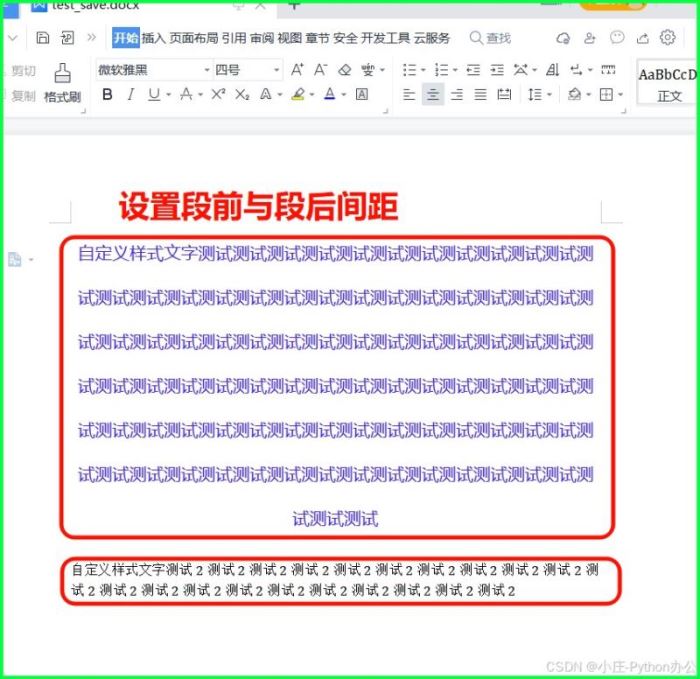
③ 段前与段后间距
from docx import document
from docx.shared import pt, rgbcolor
from docx.oxml.ns import qn
from docx.enum.text import wd_align_paragraph
doc = document()
p = doc.add_paragraph()
run = p.add_run('自定义样式文字测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试')
run.font.size = pt(14)
run.font.color.rgb = rgbcolor(0x42, 0x24, 0xe9)
# 设置中文字体需要特殊处理
run.font.name = '微软雅黑'
run._element.rpr.rfonts.set(qn('w:eastasia'), '微软雅黑')
p.alignment = wd_align_paragraph.center # 居中
p.paragraph_format.line_spacing = 1.5 # 1.5倍行距
p.paragraph_format.space_before = pt(12) # 段前12磅
p.paragraph_format.space_after = pt(12) # 段后12磅
p = doc.add_paragraph()
run = p.add_run('自定义样式文字测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2测试2')
doc.save('test_save.docx')
注意:以上代码示例需要配合相应的文件环境运行。使用前请确保已安装 openpyxl, pandas, pypdf2, pdfplumber, python-docx 等库。
以上就是python自动化处理excel、word、pdf文档的操作大全的详细内容,更多关于python处理excel、word、pdf文档的资料请关注代码网其它相关文章!





发表评论