一、学习目标
学习目标
- 系统了解spring batch批处理
- 项目中能熟练使用spring batch批处理
前置知识
- java基础
- maven
- spring springmvc springboot
- mybatis
二、spring batch简介
2.1 何为批处理?
何为批处理,大白话:就是将数据分批次进行处理的过程。比如:银行对账逻辑,跨系统数据同步等。
常规的批处理操作步骤:系统a从数据库中导出数据到文件,系统b读取文件数据并写入到数据库
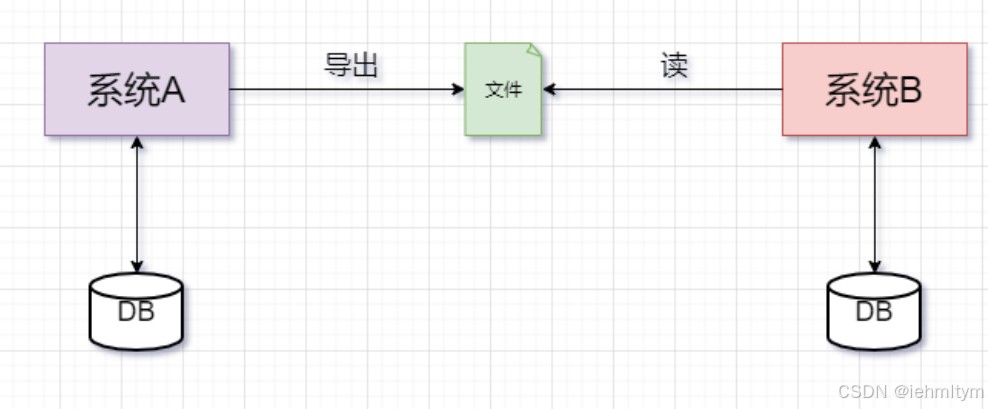
典型批处理特点:
- 自动执行,根据系统设定的工作步骤自动完成
- 数据量大,少则百万,多则上千万甚至上亿。(如果是10亿,100亿那只能上大数据了)
- 定时执行,比如:每天,每周,每月执行。
2.2 spring batch了解
官网介绍:https://docs.spring.io/spring-batch/docs/current/reference/html/spring-batch-intro.html#spring-batch-intro
这里挑重点讲下:
- sping batch 是一个轻量级的、完善的的批处理框架,旨在帮助企业建立健壮、高效的批处理应用。
- spring batch 是spring的一个子项目,基于spring框架为基础的开发的框架
- spring batch 提供大量可重用的组件,比如:日志,追踪,事务,任务作业统计,任务重启,跳过,重复,资源管理等
- spring batch 是一个批处理应用框架,不提供调度框架,如果需要定时处理需要额外引入-调度框架,比如: quartz
2.3 spring batch 优势
spring batch 框架通过提供丰富的开箱即用的组件和高可靠性、高扩展性的能力,使得开发批处理应用的人员专注于业务处理,提高处理应用的开发能力。下面就是使用spring batch后能获取到优势:
- 丰富的开箱即用组件
- 面向chunk的处理
- 事务管理能力
- 元数据管理
- 易监控的批处理应用
- 丰富的流程定义
- 健壮的批处理应用
- 易扩展的批处理应用
- 复用企业现有的it代码
2.4 spring batch 架构
spring batch 核心架构分三层:应用层,核心层,基础架构层。

application:应用层,包含所有的批处理作业,程序员自定义代码实现逻辑。
batch core:核心层,包含spring batch启动和控制所需要的核心类,比如:joblauncher, job,step等。
batch infrastructure:基础架构层,提供通用的读,写与服务处理。
三层体系使得spring batch 架构可以在不同层面进行扩展,避免影响,实现高内聚低耦合设计。
三、入门案例
3.1 批量处理流程
前面对spring batch 有大体了解之后,那么开始写个案例玩一下。
开始前,先了解一下spring batch程序运行大纲:
**
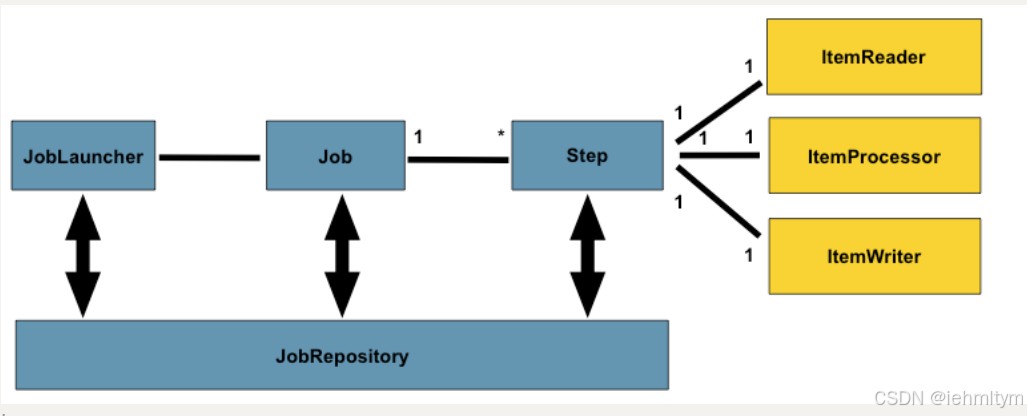
joblauncher:作业调度器,作业启动主要入口。
job:作业,需要执行的任务逻辑,
step:作业步骤,一个job作业由1个或者多个step组成,完成所有step操作,一个完整job才算执行结束。
itemreader:step步骤执行过程中数据输入。可以从数据源(文件系统,数据库,队列等)中读取item(数据记录)。
itemwriter:step步骤执行过程中数据输出,将item(数据记录)写入数据源(文件系统,数据库,队列等)。
itemprocessor:item数据加工逻辑(输入),比如:数据清洗,数据转换,数据过滤,数据校验等
jobrepository: 保存job或者检索job的信息。springbatch需要持久化job(可以选择数据库/内存),jobrepository就是持久化的接口
3.2 入门案例-h2版(内存)
需求:打印一个hello spring batch!不带读/写/处理
步骤1:导入依赖
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>2.7.3</version>
<relativepath/>
</parent>
<dependencies>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-batch</artifactid>
</dependency>
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
</dependency>
<!--内存版-->
<dependency>
<groupid>com.h2database</groupid>
<artifactid>h2</artifactid>
<scope>runtime</scope>
</dependency>
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-test</artifactid>
</dependency>
</dependencies>其中的h2是一个嵌入式内存数据库,后续可以使用mysql替换
步骤2:创建测试方法
package com.langfeiyes.batch._01_hello;
import org.springframework.batch.core.job;
import org.springframework.batch.core.step;
import org.springframework.batch.core.stepcontribution;
import org.springframework.batch.core.configuration.annotation.enablebatchprocessing;
import org.springframework.batch.core.configuration.annotation.jobbuilderfactory;
import org.springframework.batch.core.configuration.annotation.stepbuilderfactory;
import org.springframework.batch.core.launch.joblauncher;
import org.springframework.batch.core.scope.context.chunkcontext;
import org.springframework.batch.core.step.tasklet.tasklet;
import org.springframework.batch.repeat.repeatstatus;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
import org.springframework.context.annotation.bean;
@springbootapplication
@enablebatchprocessing
public class hellojob {
//job调度器
@autowired
private joblauncher joblauncher;
//job构造器工厂
@autowired
private jobbuilderfactory jobbuilderfactory;
//step构造器工厂
@autowired
private stepbuilderfactory stepbuilderfactory;
//任务-step执行逻辑由tasklet完成
@bean
public tasklet tasklet(){
return new tasklet() {
@override
public repeatstatus execute(stepcontribution contribution, chunkcontext chunkcontext) throws exception {
system.out.println("hello springbatch....");
return repeatstatus.finished;
}
};
}
//作业步骤-不带读/写/处理
@bean
public step step1(){
return stepbuilderfactory.get("step1")
.tasklet(tasklet())
.build();
}
//定义作业
@bean
public job job(){
return jobbuilderfactory.get("hello-job")
.start(step1())
.build();
}
public static void main(string[] args) {
springapplication.run(hellojob.class, args);
}
}步骤3:分析
例子是一个简单的springbatch 入门案例,使用了最简单的一种步骤处理模型:tasklet模型,step1中没有带上读/写/处理逻辑,只有简单打印操作,后续随学习深入,我们再讲解更复杂化模型。
package com.zyy.batch._01hello;
import org.springframework.batch.core.job;
import org.springframework.batch.core.step;
import org.springframework.batch.core.stepcontribution;
import org.springframework.batch.core.configuration.annotation.enablebatchprocessing;
import org.springframework.batch.core.configuration.annotation.jobbuilderfactory;
import org.springframework.batch.core.configuration.annotation.stepbuilderfactory;
import org.springframework.batch.core.launch.joblauncher;
import org.springframework.batch.core.scope.context.chunkcontext;
import org.springframework.batch.core.step.tasklet.tasklet;
import org.springframework.batch.repeat.repeatstatus;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
import org.springframework.context.annotation.bean;
/**
* spring batch 入门示例
*
* spring batch 核心组件:
* - joblauncher: 作业调度器,作业启动的主要入口
* - job: 作业,需要执行的任务逻辑
* - step: 作业步骤,一个job由1个或多个step组成,完成所有step后,job才算执行结束
* - itemreader: 数据读取器,从数据源(文件系统,数据库,队列等)中读取数据记录
* - itemwriter: 数据写入器,将数据记录写入目标数据源
* - itemprocessor: 数据处理器,进行数据清洗、转换、过滤、校验等操作
* - jobrepository: 作业仓库,保存和检索job信息,实现job的持久化(数据库或内存)
*/
@enablebatchprocessing // 开启spring batch功能,让spring容器创建相关组件
@springbootapplication // 标记为springboot应用启动类
public class hellojob {
// 自动注入spring batch核心组件
@autowired
private joblauncher joblauncher; // 作业启动器
@autowired
private jobbuilderfactory jobbuilderfactory; // job构建工厂
@autowired
private stepbuilderfactory stepbuilderfactory; // step构建工厂
/**
* 创建tasklet,定义step的执行逻辑
* tasklet是最简单的step实现方式,适合简单的处理逻辑
*/
@bean
public tasklet tasklet() {
return new tasklet() {
@override
public repeatstatus execute(stepcontribution contribution, chunkcontext chunkcontext) throws exception {
// 业务逻辑实现
system.out.println("hello 瓦塔西在学习springbatch");
// 返回执行状态:finished表示执行完成
return repeatstatus.finished;
}
};
}
/**
* 创建step,一个job可以包含多个step
*/
@bean
public step step1() {
// 使用构建器模式创建step
return stepbuilderfactory.get("step1") // 指定step名称
.tasklet(tasklet()) // 绑定tasklet
.build(); // 构建step对象
}
/**
* 创建job,整个批处理作业的入口
*/
@bean
public job job() {
// 使用构建器模式创建job
return jobbuilderfactory.get("hello-job") // 指定job名称
.start(step1()) // 指定起始step
.build(); // 构建job对象
}
/**
* 应用程序入口
*/
public static void main(string[] args) {
springapplication.run(hellojob.class, args);
}
}详细到逆天的分析
package com.zyy.batch._01hello;
import org.springframework.batch.core.job;
import org.springframework.batch.core.step;
import org.springframework.batch.core.stepcontribution;
import org.springframework.batch.core.configuration.annotation.enablebatchprocessing;
import org.springframework.batch.core.configuration.annotation.jobbuilderfactory;
import org.springframework.batch.core.configuration.annotation.stepbuilderfactory;
import org.springframework.batch.core.launch.joblauncher;
import org.springframework.batch.core.scope.context.chunkcontext;
import org.springframework.batch.core.step.tasklet.tasklet;
import org.springframework.batch.repeat.repeatstatus;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
import org.springframework.context.annotation.bean;
/**
* spring batch 入门示例 - hello world job
*
* spring batch 是一个批处理框架,用于处理大量数据操作。它提供了可重用的功能,如日志/跟踪,
* 事务管理,作业处理统计,作业重启,跳过和资源管理等。
*
* 核心概念详解:
*
* 1. joblauncher - 作业调度器
* - 负责启动job的执行
* - 可以同步或异步方式运行job
* - 处理job参数的传递
*
* 2. job - 批处理作业
* - 表示一个完整的批处理过程
* - 由一个或多个step组成
* - 具有自己的生命周期和状态管理
*
* 3. step - 作业步骤
* - job的组成部分,表示job中的一个独立工作阶段
* - 可以是简单的tasklet模式,也可以是复杂的chunk处理模式
* - 每个step可以有自己的itemreader, itemprocessor和itemwriter
*
* 4. tasklet - 任务组件
* - 最简单的step实现方式
* - 用于简单的处理逻辑,例如执行存储过程、文件操作等
* - 一次性执行的任务单元
*
* 5. itemreader - 数据读取器
* - 负责从各种数据源(文件、数据库、消息队列等)读取数据
* - 一次读取一条数据记录
* - 支持多种数据源的读取策略
*
* 6. itemprocessor - 数据处理器
* - 对itemreader读取的数据进行处理
* - 可进行数据转换、验证、过滤、清洗等操作
* - 是可选组件,可以没有
*
* 7. itemwriter - 数据写入器
* - 负责将处理后的数据写入目标位置
* - 批量写入多条数据记录
* - 支持多种目标位置(文件、数据库、消息队列等)
*
* 8. jobrepository - 作业仓库
* - 持久化和检索job相关的元数据
* - 跟踪job的执行状态
* - 存储job的执行历史信息
*
* 9. jobinstance - 作业实例
* - 特定job的逻辑运行单元
* - 由job和jobparameters组合确定
* - 每次使用相同参数运行同一job时会重用jobinstance
*
* 10. jobexecution - 作业执行
* - 表示一次job运行的尝试
* - 包含运行状态、开始时间、结束时间等信息
* - 一个jobinstance可以有多个jobexecution(如失败后重试)
*
* 11. stepexecution - 步骤执行
* - 表示一次step运行的尝试
* - 记录step执行的详细信息
* - 包含读取、处理、写入和跳过的记录数等统计信息
*
* 12. executioncontext - 执行上下文
* - 保存执行过程中的状态信息
* - 用于作业重启时恢复状态
* - 存在于jobexecution和stepexecution级别
*/
@enablebatchprocessing // 启用spring batch功能,自动配置jobrepository, joblauncher, jobregistry等组件
@springbootapplication // 标识为springboot应用的启动类,启用自动配置和组件扫描
public class hellojob {
/**
* joblauncher - 作业启动器
*
* 职责:
* 1. 接收并验证job和jobparameters
* 2. 根据job和jobparameters解析对应的jobinstance
* 3. 创建jobexecution并执行job
* 4. 处理作业执行中的异常
* 5. 返回jobexecution给调用者
*
* 注:通过@enablebatchprocessing注解,spring boot会自动创建并注册joblauncher bean
*/
@autowired // 自动注入由spring容器管理的joblauncher实例
private joblauncher joblauncher;
/**
* jobbuilderfactory - job构建工厂
*
* 作用:
* 1. 提供流式api创建和配置job
* 2. 简化job的创建过程
* 3. 设置job的各种属性(名称、监听器、验证器等)
* 4. 配置job的流程控制(顺序执行、条件执行等)
*
* 常用方法:
* - get(string name): 创建指定名称的jobbuilder
* - start(step step): 设置job的第一个step
* - next(step step): 添加下一个要执行的step
* - flow(step step): 创建基于流程的job
* - validator(jobparametersvalidator validator): 设置参数验证器
* - listener(jobexecutionlistener listener): 添加job执行监听器
*/
@autowired // 自动注入由spring容器管理的jobbuilderfactory实例
private jobbuilderfactory jobbuilderfactory;
/**
* stepbuilderfactory - step构建工厂
*
* 作用:
* 1. 提供流式api创建和配置step
* 2. 简化step的创建过程
* 3. 支持创建不同类型的step(tasklet步骤、chunk步骤)
* 4. 配置step的各种属性(名称、监听器、事务等)
*
* 常用方法:
* - get(string name): 创建指定名称的stepbuilder
* - tasklet(tasklet tasklet): 创建tasklet类型的step
* - chunk(int commitinterval): 创建chunk类型的step,指定提交间隔
* - reader(itemreader reader): 设置数据读取器
* - processor(itemprocessor processor): 设置数据处理器
* - writer(itemwriter writer): 设置数据写入器
* - listener(stepexecutionlistener listener): 添加step执行监听器
* - faulttolerant(): 配置容错处理
* - transactionmanager(platformtransactionmanager tm): 设置事务管理器
*/
@autowired // 自动注入由spring容器管理的stepbuilderfactory实例
private stepbuilderfactory stepbuilderfactory;
/**
* 创建tasklet - 定义step的执行逻辑
*
* tasklet是step的最简单实现方式,适合简单的处理逻辑。
* 它的execute方法会被反复调用,直到返回repeatstatus.finished或抛出异常。
*
* 参数说明:
* - stepcontribution: 包含更新当前stepexecution所需的信息
* - chunkcontext: 包含当前step执行的相关上下文信息
*
* 返回值说明:
* - repeatstatus.finished: 表示tasklet执行完成,不再重复执行
* - repeatstatus.continuable: 表示tasklet需要继续执行
*
* @return 配置好的tasklet实例
*/
@bean // 标记为spring bean,由spring容器管理生命周期
public tasklet tasklet() {
// 创建匿名内部类实现tasklet接口
return new tasklet() {
@override
public repeatstatus execute(stepcontribution contribution, chunkcontext chunkcontext) throws exception {
// 实现业务逻辑 - 这里只是简单打印一条消息
system.out.println("hello 瓦塔西在学习springbatch");
// 返回finished状态,表示任务执行完成,不再重复执行
return repeatstatus.finished;
// 注:如果返回repeatstatus.continuable,则会重复执行此tasklet
}
};
// 也可以使用lambda表达式简化代码:
// return (contribution, chunkcontext) -> {
// system.out.println("hello 瓦塔西在学习springbatch");
// return repeatstatus.finished;
// };
}
/**
* 创建step - 定义批处理作业的一个步骤
*
* step表示批处理作业中的一个独立阶段,可以配置自己的处理逻辑、事务控制、重启策略等。
* 这里使用最简单的tasklet类型step,适合一次性执行的简单任务。
*
* 构建过程:
* 1. 使用stepbuilderfactory.get()获取stepbuilder
* 2. 通过stepbuilder配置step属性
* 3. 调用build()方法创建step实例
*
* @return 配置好的step实例
*/
@bean // 标记为spring bean,由spring容器管理生命周期
public step step1() {
return stepbuilderfactory
.get("step1") // 指定step名称,用于在job执行过程中标识该step
.tasklet(tasklet()) // 使用上面定义的tasklet实现step的处理逻辑
.build(); // 构建step对象并返回
// 更复杂的step配置示例(仅供参考):
// return stepbuilderfactory.get("step1")
// .tasklet(tasklet())
// .listener(new stepexecutionlistener() { ... }) // 添加step执行监听器
// .allowstartifcomplete(true) // 允许重新执行已完成的step
// .startlimit(3) // 设置重启次数上限
// .build();
}
/**
* 创建job - 定义整个批处理作业
*
* job是spring batch中的顶级概念,表示一个完整的批处理过程。
* 它由一个或多个step组成,定义了steps的执行顺序和条件。
*
* 构建过程:
* 1. 使用jobbuilderfactory.get()获取jobbuilder
* 2. 通过jobbuilder配置job属性和流程
* 3. 调用build()方法创建job实例
*
* @return 配置好的job实例
*/
@bean // 标记为spring bean,由spring容器管理生命周期
public job job() {
return jobbuilderfactory
.get("hello-job") // 指定job名称,用于在执行和监控中标识该job
.start(step1()) // 设置job的第一个step
.build(); // 构建job对象并返回
// 多步骤job配置示例(仅供参考):
// return jobbuilderfactory.get("hello-job")
// .start(step1())
// .next(step2())
// .next(step3())
// .listener(new jobexecutionlistener() { ... }) // 添加job执行监听器
// .validator(new jobparametersvalidator() { ... }) // 添加参数验证器
// .preventrestart() // 禁止重启该job
// .build();
// 条件分支job配置示例(仅供参考):
// return jobbuilderfactory.get("hello-job")
// .start(step1())
// .on("completed").to(step2()) // 如果step1完成,则执行step2
// .from(step1()).on("failed").to(errorstep()) // 如果step1失败,则执行errorstep
// .end()
// .build();
}
/**
* 应用程序入口方法
*
* 作用:
* 1. 启动springboot应用
* 2. 初始化spring上下文
* 3. 注册和配置所有bean
* 4. 触发批处理作业的执行
*
* 注:
* 在默认配置下,当应用启动时,spring batch会自动执行所有已配置的job。
* 这一行为可通过application.properties中的spring.batch.job.enabled=false禁用。
*
* @param args 命令行参数
*/
public static void main(string[] args) {
// 启动springboot应用,传入主类和命令行参数
springapplication.run(hellojob.class, args);
// 注:如果需要手动控制job的启动,可以注入joblauncher和job,然后使用以下代码启动job:
// jobparameters parameters = new jobparametersbuilder()
// .addlong("time", system.currenttimemillis())
// .tojobparameters();
// joblauncher.run(job, parameters);
}
}3.3 入门案例-mysql版
mysql跟上面的h2一样,区别在连接数据库不一致。
步骤1:在h2版本基础上导入mysql依赖
爆红记得多刷新maven
<!-- <dependency>
<groupid>com.h2database</groupid>
<artifactid>h2</artifactid>
<scope>runtime</scope>
</dependency> -->
<dependency>
<groupid>mysql</groupid>
<artifactid>mysql-connector-java</artifactid>
<version>8.0.12</version>
</dependency>步骤2:配置数据库四要素与初始化sql脚本
spring:
datasource:
# 数据库四要素 账号 密码 链接地址 驱动名称
username: root
password: 123456
url: jdbc:mysql://127.0.0.1:3306/springbatch?servertimezone=gmt%2b8&usessl=false&allowpublickeyretrieval=true
driver-class-name: com.mysql.cj.jdbc.driver
# 初始化数据库,文件在依赖jar包中
sql:
init:
schema-locations: classpath:org/springframework/batch/core/schema-mysql.sql
# mode: always
mode: never
# 全局搜索快捷鍵 ctrl n 或者 shift按两次
# 繁体简体转换 “ctrl + shift + f” 快捷键这里要注意, sql.init.model 第一次启动为always, 后面启动需要改为never,否则每次执行sql都会异常。
第一次启动会自动执行指定的脚本,后续不需要再初始化
步骤3:测试
跟h2版一样。
如果是想再执行,需要换一下job名字,不然springboot不会执行:hello-job1
四、入门案例解析
idea 查看 类 所有方法的快捷键
idea:ctrl+f12
eclipse:ctrl+o
1>@enablebatchprocessing
批处理启动注解,要求贴配置类或者启动类上
@springbootapplication
@enablebatchprocessing
public class hellojob {
...
}
贴上@enablebatchprocessing注解后,springboot会自动加载joblauncher jobbuilderfactory stepbuilderfactory 类并创建对象交给容器管理,要使用时,直接@autowired即可
//job调度器 @autowired private joblauncher joblauncher; //job构造器工厂 @autowired private jobbuilderfactory jobbuilderfactory; //step构造器工厂 @autowired private stepbuilderfactory stepbuilderfactory;
2>配置数据库四要素
批处理允许重复执行,异常重试,此时需要保存批处理状态与数据,spring batch 将数据缓存在h2内存中或者缓存在指定数据库中。入门案例如果要保存在mysql中,所以需要配置数据库四要素。
3>创建tasklet对象
//任务-step执行逻辑由tasklet完成
@bean
public tasklet tasklet(){
return new tasklet() {
@override
public repeatstatus execute(stepcontribution contribution, chunkcontext chunkcontext) throws exception {
system.out.println("hello springbatch....");
return repeatstatus.finished;
}
};
}
tasklet负责批处理step步骤中具体业务执行,它是一个接口,有且只有一个execute方法,用于定制step执行逻辑。
public interface tasklet {
repeatstatus execute(stepcontribution contribution, chunkcontext chunkcontext) throws exception;
}
execute方法返回值是一个状态枚举类:repeatstatus,里面有可继续执行态与已经完成态
public enum repeatstatus {
/**
* 可继续执行的-tasklet返回这个状态会进入死循环
*/
continuable(true),
/**
* 已经完成态
*/
finished(false);
....
}
4>创建step对象
//作业步骤-不带读/写/处理
@bean
public step step1(){
return stepbuilderfactory.get("step1")
.tasklet(tasklet())
.build();
}
job作业执行靠step步骤执行,入门案例选用最简单的tasklet模式,后续再讲chunk块处理模式。
5>创建job并执行job
//定义作业
@bean
public job job(){
return jobbuilderfactory.get("hello-job")
.start(step1())
.build();
}
创建job对象交给容器管理,当springboot启动之后,会自动去从容器中加载job对象,并将job对象交给joblauncherapplicationrunner类,再借助joblauncher类实现job执行。
验证过程;
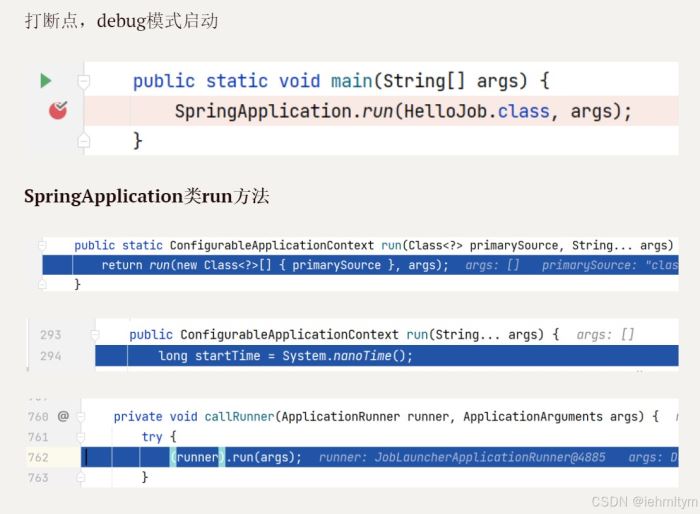
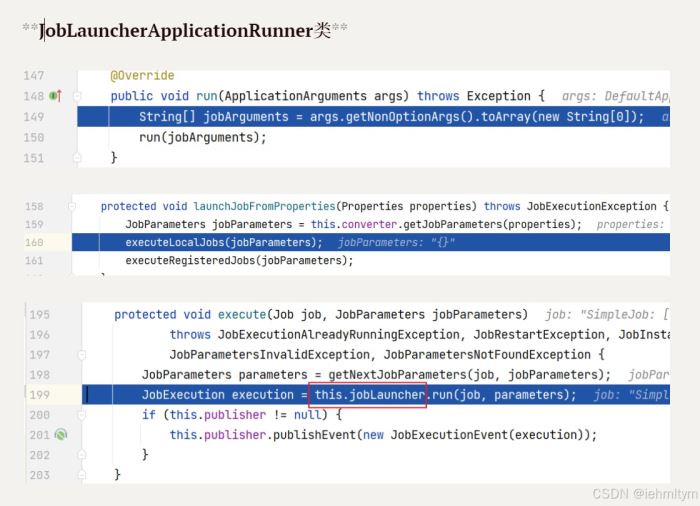
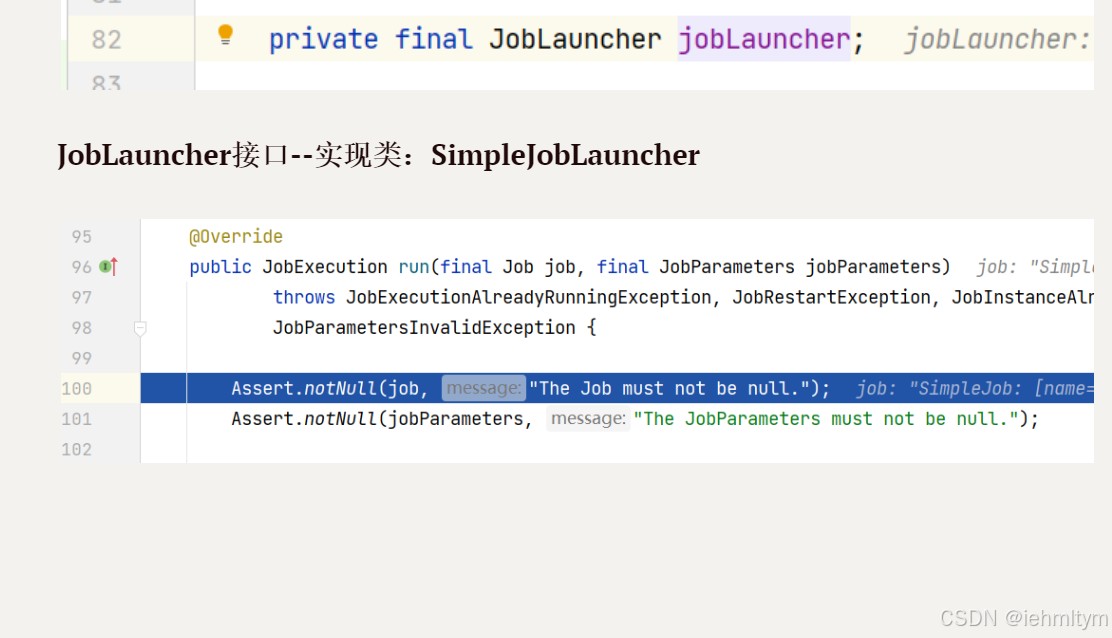
到此这篇关于springbatch简单入门案例的文章就介绍到这了,更多相关springbatch入门内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论