一个老生常谈的话题:线程的创建及销毁是非常消耗时间及资源的,所以线程应该交由线程池去执行。
threadpoolexecutor构造说明及常用方法
threadpoolexecutor提供了很多构造方法,这里主要说以下这个,其他构造方法都是基于此方法:
public threadpoolexecutor(int corepoolsize,
int maximumpoolsize,
long keepalivetime,
timeunit unit,
blockingqueue<runnable> workqueue,
threadfactory threadfactory,
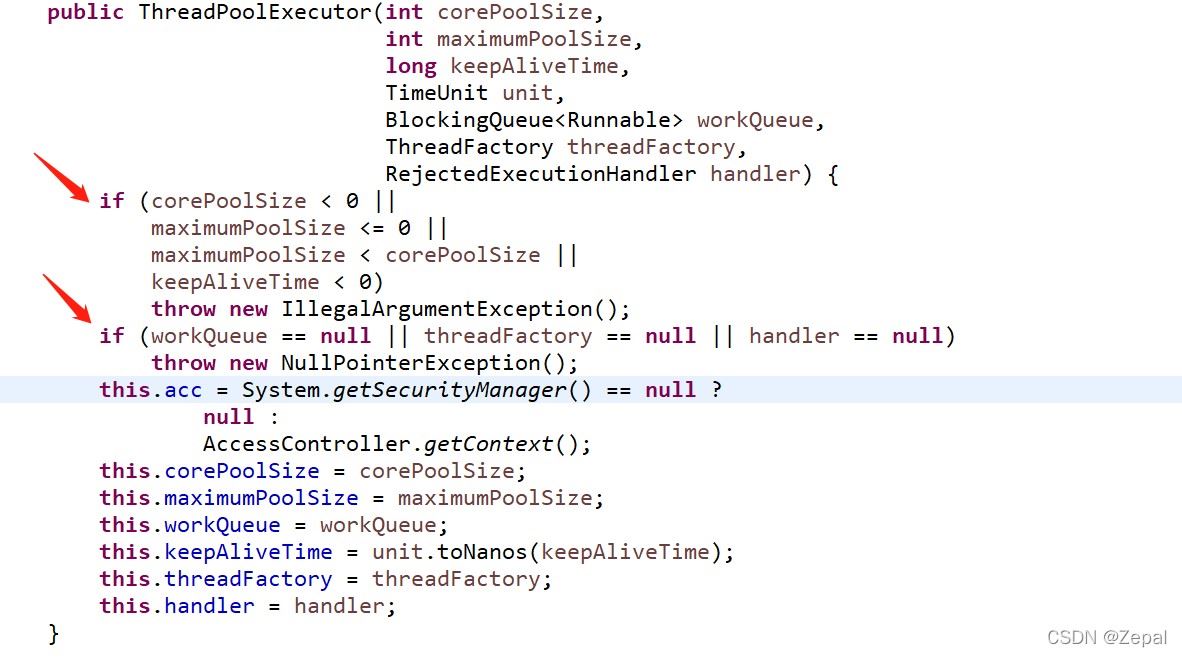
rejectedexecutionhandler handler)- 参数int corepoolsize:核心线程池大小,不能小于0;
- 参数int maximumpoolsize:最大线程池大小(核心线程数+临时线程数),不能小于等于0且不能小于corepoolsize参数,线程池的大小会在corepoolsize与maximumpoolsize之间动态变化;
- 参数long keepalivetime:临时线程(非核心线程,核心线程空闲之后不会被销毁)最大空闲时间,不能小于0;
- 参数timeunit unit:keepalivetime参数的时间单位;
- 参数blockingqueue<runnable> workqueue:线程等待队列;
- 参数threadfactory threadfactory:线程创建工厂;
- 参数rejectedexecutionhandler handler:拒绝策略;
下面是构造threadpoolexecutor的参数校验:
其他常用方法:
- int prestartallcorethreads():根据线程核心数,启动所有的核心线程,让它们全部处于空闲状态等待工作
- boolean prestartcorethread():随机启动一个核心线程,当所有核心线程都已经启动的时候,返回false(表示未启动到有效资源);
- void allowcorethreadtimeout(boolean value):设置是否允许临时线程永久空闲存活,设置true后,keepalivetime参数失效;
- boolean allowscorethreadtimeout():获取是否允许临时线程永久空闲存活;
- void shutdown():销毁线程池,此前还存在于线程池的任务依然会被执行;
- list<runnable> shutdownnow():销毁线程池,与shutdown()的区别是,未执行完成的线程会被标记为中断;
参数举例说明:
1、当创建一个任务并交给线程池执行执行后,会从消耗一个核心线程资源,当该任务执行完毕之后,会变成一个空闲线程,另外,如果核心线程数足以支撑任务运行,即使有核心空闲线程,依然会创建一个新的核心线程资源;
2、当加入线程池的任务超过核心线程数,会进入workqueue中等待执行;
3、当加入线程池的任务超过核心线程数,溢出的任务数如果超过等待队列长度,会直接创建大于corepoolsize且小于maximumpoolsize的线程资源用于执行任务,超过核心线程数的部分称为临时线程;
4、keepalivetime:当线程池被扩大到corepoolsize与maximumpoolsize之间之后,当执行完所有任务后,不再有新的任务进来,超出corepoolsize的部分会作为空闲线程,会在keepalivetime指定时间后,线程池大小缩小为corepoolsize,如果设置allowcorethreadtimeout(true),则空闲线程一直不会销毁;
5、blockingqueue<runnable> workqueue:用于保存等待执行的任务的阻塞队列接口,java提供了以下实现类:
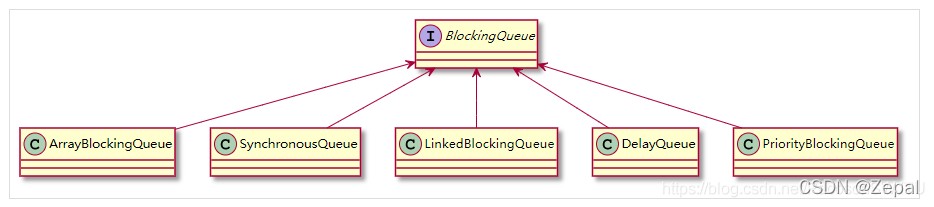
线程池中,blockingqueue是典型的"生产者消费者"模型:生产者调用插入元素的方法(add/offer/put等方法),消费者调用移除元素的方法(remove/poll/take等方法),其中,生产者插入和消费者移除都有阻塞和非阻塞的方法,offer/poll是非阻塞方法,put/take是阻塞方法(队列后面单独再写);
threadpoolexecutor提交任务采用的是不阻塞的offer方法,从队列中获取任务采用的是阻塞的take方法,正是因为threadpoolexecutor使用了不阻塞的offer方法,所以当队列容量已满,线程池会去创建新的临时线程,去处理队列中溢出的任务。
- arrayblockingqueue:是一个基于数组结构的有界阻塞队列,此队列按 fifo(先进先出)原则对元素进行排序,允许迭代中修改队列(删除元素时会更新迭代器),当然,一般也不会有场景需要迭代阻塞队列;
- linkedblockingqueue:一个基于链表结构的默认无界双端阻塞队列,双端意味着可以像普通队列一样fifo(先进先出),可以以像栈一样filo(先进后出)。吞吐量通常要高于arrayblockingqueue(如无需在迭代中修改元素,优于arrayblockingqueue,同时记得指定队列长度,提供了一个可选有界的构造函数,而在未指明容量时,容量默认为integer.max_value);
- synchronousqueue:一个不存储元素的阻塞队列,所谓不存储元素,正如名字描述,同步队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,即生产一个,就消费一个,因此它也被认为是无界的队列,吞吐量通常要高于linkedblockingqueue。同时,synchronousqueue不能遍历,因为它没有元素可以遍历;
- delayqueue:使用二叉堆实现的优先级阻塞队列,通过执行时延从队列中提取任务,时间没到任务取不出来,可用于实现有延时场景的需求;
- priorityblockingqueue:使用二叉堆实现的优先级阻塞队列,可以实现comparable接口也可以提供comparator来对队列中的元素进行比较,跟时间没有任何关系,仅仅是按照优先级取任务,如果有根据某个规则优先取出任务的场景,适用;
综上,需要根据每个队列的特点选择适合自己场景的队列。
6、rejectedexecutionhandler handler:当队列和线程池都满了(从上面可以看出,一个线程池可以容纳的的最大任务数是maximumpoolsize+队列长度,因此使用无界队列会造成队列永不会满的情况,一旦控制不好就容易出现oom),说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。
1、abortpolicy:直接抛出异常;
2、callerrunspolicy:只用调用者所在线程来运行任务;
3、discardoldestpolicy:丢弃队列里最近的一个任务,并执行当前任务;
4、discardpolicy:不处理,丢弃掉;
5、也可以根据应用场景需要来实现rejectedexecutionhandler接口自定义策略。如记录日志或持久化不能处理的任务;
注:abortpolicy/callerrunspolicy/discardoldestpolicy/discardpolicy都是threadpoolexecutor的内部类,如下:
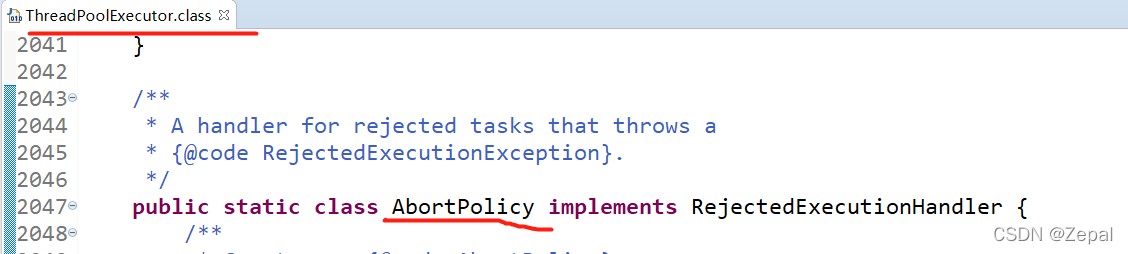
所以,实例化需要用内部类的方式,如下:
abortpolicy abortpolicy = new threadpoolexecutor.abortpolicy();
自定义rejectedexecutionhandler拒绝策略示例:
public class rejectedexecutionhandlertest implements rejectedexecutionhandler {
@override
public void rejectedexecution(runnable r, threadpoolexecutor executor) {
// 啥逻辑都没有,表示忽略,比如discardpolicy
try {
executor.getqueue().put(r);
} catch (interruptedexception e) {
// todo 记录错误日志等
e.printstacktrace();
}
}
}threadpoolexecutor的特点总结起来就是以下4点:
1、当有任务提交的时候,会创建核心线程去执行任务(即使有核心线程空闲);
2、当核心线程数达到corepoolsize时,后续提交的都会进blockingqueue中排队;
3、当blockingqueue满了(offer失败),就会创建临时线程(临时线程空闲超过一定时间后,会被销毁),其中临时线程最大数量=maximumpoolsize - corepoolsize,空闲最大时间由keepalivetime控制,如果设置allowcorethreadtimeout(true),临时线程永不销毁;
4、当线程总数达到maximumpoolsize 时,后续提交的任务都会被rejectedexecutionhandler拒绝。
为什么强制要求使用threadpoolexecutor创建线程池
在executor类中,提供了以下场景的创建线程池的方法:
1、newcachedthreadpool,特点:必要时创建新线程,空闲线程会保留60s;
public static executorservice newcachedthreadpool(threadfactory threadfactory) {
return new threadpoolexecutor(0, integer.max_value,
60l, timeunit.seconds,
new synchronousqueue<runnable>(),
threadfactory);
}根据上面的threadpoolexecutor,允许的创建线程数量为 integer.max_value,可能会创建大量的线程,从而导致 oom,还无法指定拒绝策略。
2、newfixedthreadpool,特点:包含固定的线程数,空闲线程会被一直保留;
public static executorservice newfixedthreadpool(int nthreads, threadfactory threadfactory) {
return new threadpoolexecutor(nthreads, nthreads,
0l, timeunit.milliseconds,
new linkedblockingqueue<runnable>(),
threadfactory);
}
public linkedblockingqueue() {
this(integer.max_value);
}允许的请求队列长度为 integer.max_value,可能会堆积大量的请求,从而导致 oom,还无法指定拒绝策略。
3、newsinglethreadexecutor,特点:只有一个线程的池,顺序执行每一个提交的任务;
public static executorservice newsinglethreadexecutor(threadfactory threadfactory) {
return new finalizabledelegatedexecutorservice
(new threadpoolexecutor(1, 1,
0l, timeunit.milliseconds,
new linkedblockingqueue<runnable>(),
threadfactory));
}
public linkedblockingqueue() {
this(integer.max_value);
}允许的请求队列长度为 integer.max_value,可能会堆积大量的请求,从而导致 oom,还无法指定拒绝策略。
4、scheduledthreadpoolexecutor,特点:用于构建具有延时队列的线程池,空闲线程一直被保留;
public scheduledthreadpoolexecutor(int corepoolsize) {
super(corepoolsize, integer.max_value, 0, nanoseconds,
new delayedworkqueue());
}允许的创建线程数量为 integer.max_value,可能会创建大量的线程,从而导致 oom。
............省略executors其他创建线程的方法。
从上面可以看到,使用executors创建的线程池,虽然都是threadpoolexecutor,但是灵活度都不高,且创建出来的是具有一定特色的线程池,使用threadpoolexecutor类本身去创建线程池,除了可以更加明确线程池的运行规则,还能更多的规避资源耗尽的风险,毕竟我命由我不由天。
当然,threadpoolexecutor提供了相关参数的set方法,如果一定要用executors去创建,那么记得调整一下相关参数,避免大量任务堆积,产生oom。
在项目中创建线程池
如果需要在项目中创建线程池,那么应该将它设置成单例模式。
示例,用枚举的方式创建单例:
// 线程工厂
public class userthreadfactory implements threadfactory {
// 线程组命名标识
private final string nameprefix;
// 线程编号
private final atomicinteger nextid = new atomicinteger(1);
// 定义线程组名称,在 jstack 问题排查时,非常有帮助
userthreadfactory(string whatfeaturofgroup) {
nameprefix = "from userthreadfactory's " + whatfeaturofgroup + "-worker-";
}
@override
public thread newthread(runnable task) {
string name = nameprefix + nextid.getandincrement();
thread thread = new thread(task, name);
return thread;
}
}
// 单例线程池
public enum threadpoolenum {
instance;
private threadpoolexecutor threadpoolexecutor;
// 枚举的特性,在jvm中只会被实例化一次
private threadpoolenum() {
threadpoolexecutor = new threadpoolexecutor(2,
4, 10, timeunit.seconds, new priorityblockingqueue<runnable>(),
new userthreadfactory("first-threadpool"),
new threadpoolexecutor.discardpolicy());
}
public threadpoolexecutor getinstance() {
return threadpoolexecutor;
}
public static void main(string[] args) throws interruptedexception {
threadpoolexecutor executor1 = threadpoolenum.instance.getinstance();
threadpoolexecutor executor2 = threadpoolenum.instance.getinstance();
system.out.println(executor1 == executor2);
runnable r = () -> {
system.out.println("新创建的线程任务,交由线程池执行");
system.out.println(thread.currentthread().getname());
};
executor1.execute(r);
// 销毁线程池
executor1.shutdown();
}
}执行结果:

在spring中创建线程池
@configuration
public class threadpoolconfig {
// 线程池的参数配置可由外部配置引入
@bean(destroymethod = "shutdown")
public threadpoolexecutor initthreadpoolexecutor() {
return new threadpoolexecutor(2,
4, 10, timeunit.seconds, new priorityblockingqueue<runnable>(),
new threadpoolexecutor.discardpolicy());
}
}总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论