背景
老后台系统的数据记录导出excel功能被财务,运营吐槽难用有时候甚至用不了,我负责重构老后台系统代码,刚好把excel导出功能重新优化设计一下。接下来我会分析当前问题,针对优化性能,进行代码分层解藕实现优雅封装 尽可能在提高10秒同步流返回最大的记录条数
关键字: es滚动查询,读写分离,阻塞队列,生产消费模型,工厂模式与策略接口,抽象模板与资源控制
原代码逻辑
public responseentity export(prizedto param) {
param.setpagenum(1);
param.setpagesize(10000);
espageentity<esprizevo> result = null;
try {
result = esutil2.query(authcode, indexname, fuzzyqueryorder, fuzzyqueryorderversion, param, esprizevo.class);
} catch (throwable ex) {
log.error(ex.getmessage(), ex);
}
excelutil<esprizevo> util = new excelutil<>(esprizevo.class);
list<esprizevo> list = json.parsearray(json.tojsonstring(result.getlist()), esprizevo.class);
return util.exportexcel(list, "数据记录", null);
}
//util.exportexcel 基本与若以框架自带的excelutils一致
这一看,代码确实简单粗暴,因为数据是存在es库中的,公司的es库 分页搜索最多支持到第一万条数据,所以代码简单粗暴的直接一次查1w条
缺点可以说相当大,首先导出数据不支持一万条以上的数量,第二就是整个效率低下,查询与写记录是同步阻塞。第三就是内存还有待优化,一个list 最大情况下会保存一万条记录。
光1w条记录导出用了15s,效率实在太低


用户的诉求是希望能够导出2w条左右的数据,接下来开始进行优化分析
优化点
1.首先要突破1w条记录数量限制需要使用es的滚动查询,同时需要确定好没次滚动的数量,太长会导致单次查询较慢,同时list元素过多占用堆内存过多,滚动数量太少则会增加滚动次数,整体效率慢
2.优化整体效率,因为使用了滚动查询,那么可以进行读写分离,每次滚动的数据交给异步线程池进行异步的写excel。
3.优化内存空间占用,这里主要涉及到读写分离时中间的缓冲池的容量大小,这个容量最好能过做到写数据不需要空等待数据进来,生产数据不会出现缓存池满了阻塞的情况。还有一个写excel操作的配置,配置sxssfworkbook的 rowaccesswindowsize 属性为每次滚动查询的大小,同时我还优化了es的查询模板,减少了运营与财务不需要的数据字段,大幅降低了单条数据的大小

整体设计
先上架构图:
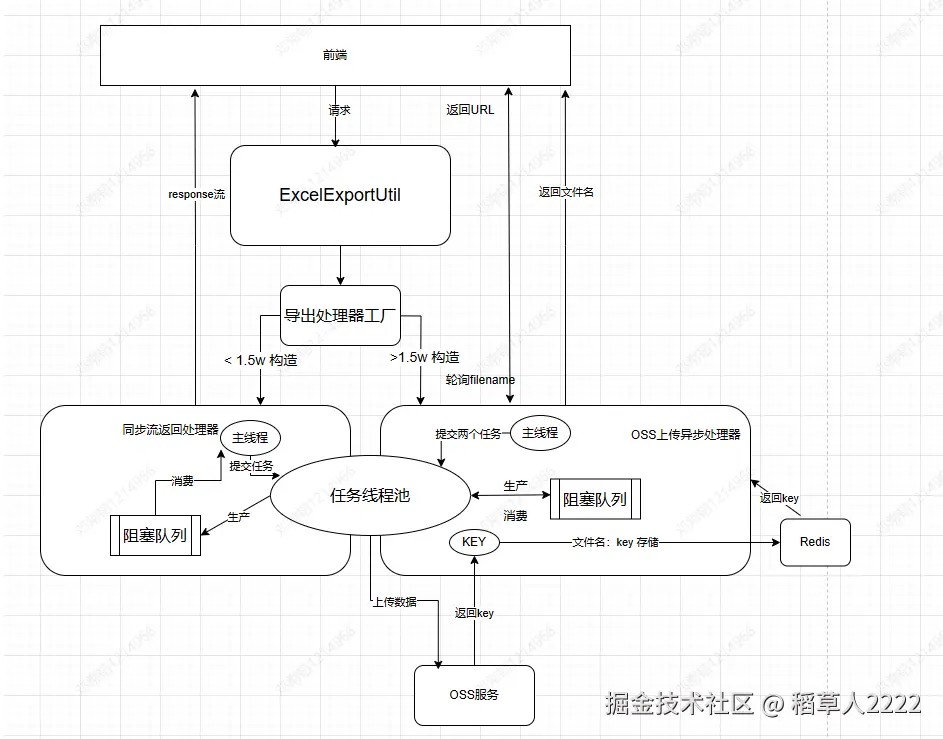
可以看到我通过数据范围的大小分为了两种处理器,一种是同步流返回处理器,面对数据量较小范围的数据进行同步导出,而数据量较大的则需要完全异步后端处理,前端再轮训或者后端主动通知的方法告知其文件下载。(1.5w 其实可以调整至5w,能过实现5秒处理)
这两种处理器的处理逻辑其实是类似的,全部都采用了生产消费模型,实现读写异步的功能。在代码上封装统一提交任务与消费数据两个主要功能。
代码细节
es 滚动查询封装
es滚动主要分为三个步骤,第一个步骤是 发送第一次滚动查询请求,es内部会生成一份查询数据快照。api: post /<index_name>/_search?scroll=<timeout> timeout 是这个快照保存的时间,可以设置为1m 即一分钟,请求体需要有一个size,即每次滚动的大小。请求返回一个scrollid,以及第一次滚动查询的数据!
{
"size": 100, // 每次滚动返回的文档数量
"query": {
"match_all": {} // 你的查询条件,可以是任何复杂的查询
},
"sort": ["_doc"] // 【最佳实践】使用 `_doc` 排序以获得最高效的检索性能
}
第二个步骤是开始滚动查询数据,api: post /_search/scroll 你需要使用第一步返回的scrollid 作为请求体去请求,不需要携带查询模板。这个步骤会再返回一个新的scrollid,然后在用新的scrollid 重复步骤二即开始滚动数据,需要注意此步骤不可并发,即使有些获取的scrollid是相同的。
{
"scroll": "1m", // 【重要】可以重新设置 scroll 的超时时间,重置倒计时
"scroll_id": "dxf1zxj5qw5krmv0y2gbaaaaaaaaad4wym9lavytznduqlnsddcwakfmnju1qq=="
}
删除查询快照,在滚动获取数据为空的时候需要去请求es删除这次的查询快照,如果不请求,那么会在设置的timeout超时时间后自动删除。api: delete /_search/scroll
封装初始化滚动查询,以及后续的滚动,使用transmittablethreadlocal存储scrollid
public class esscrollutil extends esutil implements essearch {
@value("${es.xxx.order.authcode}")
private string authcode;
@value("${es.xxx.order.indexname}")
private string indexname;
public static final transmittablethreadlocal<string> localscrollid = new transmittablethreadlocal<>();
// 每次滚动完进行tl清除
@override
public void cleanlocalscrollid() {
localscrollid.remove();
}
public <r extends baseesresult> scrollres<r> getfirstscrollid(class<r> clazz, string templatename, string templateversion, object body) {
parameterizedtypeimpl type = new parameterizedtypeimpl(new type[]{clazz}, null, espageentity.class);
scrollres<r> baseesresultscrollres = super.queryforscroll(authcode, indexname, templatename, templateversion, body, type);
localscrollid.set(baseesresultscrollres.getscrollid());
return baseesresultscrollres;
}
public <r extends baseesresult> scrollres<r> nextscrollpage(class<r> clazz){
if (stringutilsext.isempty(localscrollid.get())) {
log.error("请先调用getfirstscrollid方法获取scrollid");
throw new customexception("请先调用getfirstscrollid方法获取scrollid");
}
parameterizedtypeimpl type = new parameterizedtypeimpl(new type[]{clazz}, null, espageentity.class);
scrollres<r> res = super.queryforscrollnextpage(authcode, indexname, localscrollid.get(), type);
localscrollid.set(res.getscrollid());
return res;
}
}
这样在业务处理代码只需要执行 getfirstscrollid 然后 while 执行 nextscrollpage 不需要处理scrollid赋值的问题
基本excel导出处理夫类,封装滚动任务执行以及excel写入任务,内部使用阻塞队列实现生产消费模型
@slf4j
public class baseexcelexporter {
// clazz缓存, key为类名, value为字段名和注解的map
protected static final hashmap<class<?>, list<excel>> cacheexcelinfo = new hashmap<>();
// 解析excel缓存, key为 classname + "_" + 注解name, value为字段
protected static final hashmap<string,field> cachefield = new hashmap<>();
protected static executorservice executorservice;
static {
threadpooltaskexecutor threadpooltaskexecutor = new threadpooltaskexecutor();
// 两倍最大并发数满足了最大处理情况(单次oss处理器需要两个线程),需要使用包装ttl线程池,继承scrollid
threadpooltaskexecutor.setcorepoolsize(max_concurrency*2);
threadpooltaskexecutor.setmaxpoolsize(max_concurrency*2);
threadpooltaskexecutor.setqueuecapacity(0);
threadpooltaskexecutor.setthreadnameprefix("excel-exporterthread-");
threadpooltaskexecutor.setrejectedexecutionhandler(new threadpoolexecutor.abortpolicy());
threadpooltaskexecutor.initialize();
executorservice = ttlexecutors.getttlexecutorservice(threadpooltaskexecutor.getthreadpoolexecutor());
}
/**
* 提交es查询任务,将查询结果放入阻塞队列,异常或查询数据为空时将空数据放入队列
* @param task 滚动查询任务
* @param taskresqueue 结果阻塞队列
* @param <r> 结果类型
*/
protected <r extends baseesresult> void commitesquerytask(supplier<scrollres<r>> task,
blockingqueue<list<r>> taskresqueue){
try {
executorservice.submit(() -> {
try {
for (;;){
scrollres<r> taskresult = task.get();
list<r> res = taskresult.getres();
if(res.isempty()){
log.debug("任务已完成,退出循环");
taskresqueue.put(new arraylist<>());
return;
}
taskresqueue.put(res);
}
}catch (exception e) {
log.error("es滚动查询出现异常", e);
}
});
} catch (rejectedexecutionexception e) {
log.error("excel导出线程池已满,无法提交任务", e);
throw e;
}
}
protected <r extends baseesresult> void syncwritetaskresult(string handlername, class<r> clazz,
blockingqueue<list<r>> dataqueue,
sheet sheet, cellstyle datecellstyle){
long start;
try {
for (;;){
list<r> taskres = dataqueue.poll(9, timeunit.seconds);
if(taskres == null){
log.error("【{}】获取阻塞队列数据超时! 线程退出阻塞等待", handlername);
break;
}
log.info("主线程获取到阻塞队列数据,数据大小:{} 当前队列剩余数据批数:{}",taskres.size(), dataqueue.size());
// 获取的list为空则结束了(可能任务执行异常了)
if(taskres.isempty()){
log.info("excel导出任务已完成,主线程退出循环");
break;
}
// 写入数据
start = system.currenttimemillis();
writerows(sheet, taskres, clazz, datecellstyle);
log.info("主线程写入数据耗时:{} ms", system.currenttimemillis() - start);
}
} catch (interruptedexception e) {
log.error("【{}】 消费线程被中断,线程池繁忙", handlername, e);
throw new customexception("系统导出繁忙中,请稍后重试");
}
}
public void analysisexcelanno(class<?> clazz){
list<excel> excels = cacheexcelinfo.computeifabsent(clazz, k -> new arraylist<>());
//获取字段上的注解
field[] declaredfields = clazz.getdeclaredfields();
for (field declaredfield : declaredfields) {
declaredfield.setaccessible(true);
excel excel = declaredfield.getannotation(excel.class);
if (excel != null) {
excels.add(excel);
cachefield.put(clazz.getsimplename()+"_"+excel.name(), declaredfield);
}
}
}
/**
* 获取excel表头, 值为 {@link excel} 注解的 name 属性, 顺序与字段顺序一致
* 如果是第一次导出该类则会进行 {@link #analysisexcelanno(class)} 解析
* @param clazz 待导出的类
* @return 表头
*/
public string[] getexcelheader(class<?> clazz){
list<excel> excels = cacheexcelinfo.getordefault(clazz, null);
if (excels == null) {
analysisexcelanno(clazz);
excels = cacheexcelinfo.get(clazz);
}
return excels.stream().map(excel::name).toarray(string[]::new);
}
public field getfieldbyexcelname(class<?> clazz, string name){
field field = cachefield.get(clazz.getsimplename()+"_"+name);
if(field == null){
throw new customexception("未找到对应的字段,请检查是否执行analysisexcelanno(clazz) 过该类");
}
return field;
}
/**
* 写入数据行,需要注意写入后list数据已被清空,无法再次使用
* @param sheet 工作表
* @param data 待写入数据
* @param clazz 数据类型
* @param datecellstyle 单元格样式
*/
public void writerows(sheet sheet, list<?> data, class<?> clazz, cellstyle datecellstyle){
string[] headers = getexcelheader(clazz);
// 获取当前行数,判断是否需要创建表头
int currentrownum = sheet.getphysicalnumberofrows();
// 如果当前行数为 0,说明表头还未创建,需要创建表头
if (currentrownum == 0) {
row headerrow = sheet.createrow(0); // 第 0 行作为表头行
for (int i = 0; i < headers.length; i++) {
// 创建表头单元格,值为注解的 name 属性
cell cell = headerrow.createcell(i);
cell.setcellvalue(headers[i]);
// 设置每个列的宽度
excel excel = cacheexcelinfo.get(clazz).get(i);
sheet.setcolumnwidth(i, (int) ((excel.width() + 0.72) * 256));
}
currentrownum++; // 表头占用第 0 行,所以数据从第 1 行开始
}
// 写入数据行
for (object item : data) {
row datarow = sheet.createrow(currentrownum++); // 从当前行开始写入数据
for (int j = 0; j < headers.length; j++) {
cell cell = datarow.createcell(j); // 创建每列单元格
field field = getfieldbyexcelname(clazz,headers[j]); // 根据表头名称获取字段
try {
object value = field.get(item); // 获取字段值
if (value instanceof date) {
// 如果是日期类型,设置日期值和样式
cell.setcellvalue((date) value);
cell.setcellstyle(datecellstyle);
} else {
// 其他类型直接转换为字符串
cell.setcellvalue(value == null ? "" : value.tostring());
}
} catch (illegalaccessexception e) {
log.error("获取字段值异常", e);
throw new customexception("获取字段值异常");
}
}
}
// 显式清空辅助jvm回收
data.clear();
}
}
excel导出接口,对excel handler 的抽象接口
public interface excelexporthandler {
// 导出接口,执行此方法即完成了excel导出
public <r extends baseesresult> excelhandleres export(class<r> clazz, scrollres<r> firstscroll, supplier<scrollres<r>> nextscroll, sxssfworkbook workbook, cellstyle datecellstyle);
// 判断该处理器是否支持处理该滚动查询,这里通过res的count即文档数量来选择同步返回流处理器还是oss异步处理器
public boolean support(scrollres<?> scrollres);
}
同步流excel导出处理器-简单导出处理器
/**
* 简单excel导出处理器,支持导出数据量小于40000的数据。
* 主线程写入数据,子线程请求es进行滚动查询,提高导出效率。
*/
@service
@slf4j
public class sampleexporthandler extends baseexcelexporter implements excelexporthandler {
@override
public <r extends baseesresult> excelhandleres export(class<r> clazz, scrollres<r> firstscroll,
supplier<scrollres<r>> nextscroll, sxssfworkbook workbook,
cellstyle datecellstyle) {
servletoutputstream outputstream = null;
try {
sheet sheet = workbook.createsheet("sheet1");
// 设置一个较小值,size 即为缓冲池的滚动批次大小,这里最多允许两个滚动批次结果存在队列中
blockingqueue<list<r>> dataqueue = new linkedblockingqueue<>(2);
// 提交es滚动查询任务至线程池中
commitesquerytask(nextscroll, dataqueue);
// 后写入第一次滚动的数据
writerows(sheet, firstscroll.getres(), clazz, datecellstyle);
// 主线程消费阻塞队列的写入数据
syncwritetaskresult("sampleexcel导出处理器",clazz, dataqueue, sheet, datecellstyle);
httpservletresponse response = getresponse();
// 获取输出流
outputstream = response.getoutputstream();
// 将工作簿写入输出流
workbook.write(outputstream);
// 刷新输出流
outputstream.flush();
return new excelhandleres(true);
} catch (exception e){
log.error("导出 excel 时发生异常",e);
return new excelhandleres(false);
}
finally {
if(outputstream != null){
try {
outputstream.close();
} catch (exception e) {
log.error("outputstream 关闭时发生异常, ", e);
}
}
}
}
private httpservletresponse getresponse() {
httpservletresponse response = ((servletrequestattributes) requestcontextholder.getrequestattributes()).getresponse();
response.setcontenttype("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
try {
response.setheader("content-disposition", "attachment; filename=" + urlencoder.encode("export.xlsx", "utf-8"));
} catch (unsupportedencodingexception e) {
throw new runtimeexception(e);
}
return response;
}
@override
public boolean support(scrollres<?> scrollres) {
return scrollres.getcount() <= 40000;
}
}
两个处理器的代码是相似的,这里就不重复写了。小细节是先去提交滚动查询任务至线程池中然后再去写入第一次滚动数据,如果顺序相反则第一次写入数据是阻塞读任务的。
导出工厂,通过第一次滚动查询的结果数量 调用excelexporthandler.support 找到合适的处理器
@component
public class excelexporthandlerfactory {
@autowired
private list<excelexporthandler> handlers;
public excelexporthandler buildhandler(scrollres<?> scrollres) {
for (excelexporthandler handler : handlers) {
if (handler.support(scrollres)) {
return handler;
}
}
return null;
}
}
exccel 导出工具, 直接用于service 调用
public class largeexcelutil implements applicationcontextaware {
private static excelexporthandlerfactory excelexporthandlerfactory;
public static final int max_concurrency = 2;
// 最大并发数量
private static final atomicinteger atomicinteger = new atomicinteger(max_concurrency);
/**
* 一定要设置分页大小!
* @param clazz 返回结果的类型,必须使用 {@link excel} 注解
* @param essearch es查询工具类
* @param templatename es查询模板名称
* @param templateversion es查询模板版本
* @param body es查询参数
* @return
* @param <r>
*/
public static <r extends baseesresult> excelhandleres export(class<r> clazz, essearch essearch, string templatename, string templateversion, object body, integer pagesize) {
if(atomicinteger.decrementandget() < 0){
atomicinteger.incrementandget();
throw new customexception("系统导出繁忙中,请稍后重试");
}
// 通过第一次滚动获取scrollid以及滚动数据量再通过数据量获取处理器来执行导出
scrollres<r> firstscrollid = essearch.<r>getfirstscrollid(clazz, templatename, templateversion, body);
excelexporthandler excelexporthandler = excelexporthandlerfactory.buildhandler(firstscrollid);
if (excelexporthandler == null) {
throw new runtimeexception("待导出数据太多了,暂不支持的导出");
}
sxssfworkbook workbook = null;
try {
// 创建 sxssfworkbook工作簿,内存最大保存pagesize个数据, 开启压缩临时文件减少磁盘空间,但不要开启使用共享字符会提高一倍多的写入时间
workbook = new sxssfworkbook(null,pagesize,true,false);
cellstyle datecellstyle = workbook.createcellstyle();
// 格式化日期数据
creationhelper creationhelper = workbook.getcreationhelper();
datecellstyle.setdataformat(creationhelper.createdataformat().getformat("yyyy-mm-dd hh:mm:ss"));
return excelexporthandler.export(clazz, firstscrollid, () -> essearch.nextscrollpage(clazz), workbook, datecellstyle);
}
finally {
// 因为使用了localstorage存储scrollid,使用完后必须清除
essearch.cleanlocalscrollid();
atomicinteger.incrementandget();
try {
if(workbook != null){
// 先尝试关闭工作簿同时释放了内存与临时文件
workbook.close();
}
} catch (ioexception e) {
log.error("sxssfworkbook close 失败,错误信息", e);
}finally {
if(workbook != null){
// 如果关闭工作簿失败则释放临时文件
workbook.dispose();
}
}
}
}
@override
public void setapplicationcontext(applicationcontext applicationcontext) throws beansexception {
excelexporthandlerfactory = applicationcontext.getbean(excelexporthandlerfactory.class);
}
}
实现效果
机器2c4g 每次滚动数量2000 时 写入 与 读取的耗时比较接近,下图中es滚动查询 平均比写入多大概50ms

在导出4w条数据时,接口总耗时6911ms

总结 (偷个懒)
1.突破数据量限制 - 引入 es 滚动查询 (scroll api)
动作:替换原有的简单分页查询,采用 es 滚动查询机制。
关键设计:
- 创建查询快照,保证数据一致性。
- 分批次获取数据,通过
size参数控制每批数据量(如 2000 条),平衡单次查询速度和网络请求次数。 - 使用
transmittablethreadlocal在线程池间安全地传递滚动 id (scroll_id),优雅地封装了查询细节。
2.提升处理效率 - 生产消费模型 & 异步化
动作:将 数据查询(生产) 和 excel 写入(消费) 分离。
关键设计:
- 生产者:一个后台线程专门负责执行滚动查询,将获取到的数据批次放入一个阻塞队列 (
blockingqueue)。 - 消费者:主线程(或另一个消费者线程)从队列中取出数据批次,异步写入 excel。
- 效益:读写操作并行,消除了查询等待写入的阻塞时间,极大提升了 cpu 和 i/o 利用率。
3.优化内存占用 - 流式处理与缓存
动作:避免大数据量的整体驻留。
关键设计:
- 使用
sxssfworkbook:替换传统的xssfworkbook,设置rowaccesswindowsize(如 2000),实现了磁盘换内存的流式写入,极大降低了内存压力。 - 精简数据字段:优化 es 查询模板,只获取导出必需的字段,从源头上减少了单条数据大小和网络传输量。
- 可控的队列容量:设置合理的阻塞队列大小(如容量为 2),作为生产者和消费者之间的缓冲,防止内存堆积。
4.架构扩展性 - 策略模式与工厂模式
动作:根据数据量大小智能选择不同的处理策略。
关键设计:
定义 excelexporthandler 接口:统一导出处理器的行为。
实现不同处理器:
sampleexporthandler:处理数据量较小(如 ≤ 2w 条)的场景,直接同步响应流返回文件。ossexporthandler(文中提及):处理大数据量场景,异步导出至 oss,前端通过轮询或通知下载。
工厂模式自动选择:通过 excelexporthandlerfactory 根据第一次查询的结果总数,自动选择最合适的处理器。
5.资源保护 - 限流与清理
动作:防止系统过载和资源泄漏。
关键设计:
- 并发控制:使用原子计数器 (
atomicinteger) 限制最大同时导出任务数,超出则友好拒绝,保护系统稳定性。 - 资源清理: finally 块中确保关闭
sxssfworkbook(释放临时文件)和清除threadlocal中的scroll_id(释放 es 服务端资源)。
优化成果
- 功能上:彻底打破了 1w 条的数据限制,可支持海量数据导出。
- 性能上:耗时从 15 秒(1w条)降低到约 7 秒(4w条) ,性能提升超过 8 倍,且吞吐量大幅增加。
- 稳定性上:内存占用可控,无 oom 风险;通过线程池和队列管理,系统负载更加平稳。
- 架构上:代码清晰,模块解耦,扩展性强,为未来处理更复杂的导出需求打下了良好基础。
代码设计模式与架构总结
1.baseexcelexporter(公共父类) - 模板方法模式 & 资源复用
设计意图:抽取共性,封装流程。将导出过程中不变的核心算法骨架(生产-消费模型)与可变的实现细节(具体如何查询、如何写入)分离。
实现要点:
模板方法:commitesquerytask 和 syncwritetaskresult 这两个 protected 方法定义了“提交查询任务”和“消费写入数据”的标准流程。子类只需调用它们即可完成核心逻辑,无需关心多线程同步和队列管理的复杂细节。
公共资源:
- 线程池:集中管理所有导出任务的线程资源,避免重复创建,方便参数调优(如使用
ttlexecutors解决线程池中threadlocal传递问题)。 - 缓存机制:
cacheexcelinfo和cachefield使用hashmap缓存了类的注解信息,通过“懒加载”机制,避免了每次导出都通过反射解析注解的巨大开销,这是性能优化的关键点之一。
好处:极大减少了子类的代码量,确保了所有导出器行为的一致性,并且将性能优化手段(缓存、线程池)集中在父类,便于维护。
2.excelexporthandler(接口类) - 策略模式
设计意图:定义标准,开放扩展。声明一个通用的导出契约,将不同的导出算法(如同步流、异步oss)抽象为不同的策略,使它们可以相互替换。
实现要点:
export(...)方法是策略的核心执行方法,接收所有必要的参数(如首次查询结果、工作簿、后续查询的supplier等)。support(...)方法是策略的选择依据,根据数据量等条件判断该处理器是否适用。
好处:
- 符合开闭原则:未来如果需要增加新的导出方式(如导出为csv、分片zip下载),只需实现新的
excelexporthandler即可,无需修改现有任何代码。 - 解耦:使用方(如
largeexcelutil)只依赖于接口,不依赖于具体实现,降低了系统各个部分的耦合度。
3.excelexporthandlerfactory(工厂类) - 工厂模式
设计意图:对象创建与使用分离。负责根据业务规则(数据量)自动选择并创建具体的策略实现对象。
实现要点:
- 利用 spring 的依赖注入(
@autowired private list<excelexporthandler> handlers)自动收集所有实现了excelexporthandler的 bean。 buildhandler方法遍历处理器列表,通过调用每个处理器的support方法来找到最合适的那个。
好处:
- 简化客户端代码:使用方(
largeexcelutil.export)无需知道有哪些处理器,也无需写一堆if-else来判断,只需调用工厂方法即可获得合适的处理器。代码非常简洁和清晰。 - 集中管理:所有处理器的选择逻辑都集中在工厂里,规则变化只需修改一处。
4.largeexcelutil(utils类) - 外观模式 & 资源管理
设计意图:提供简洁的高层接口,整合复杂子系统。它不再是传统的静态工具类,而是一个集成了复杂流程和资源管理的门户类(facade) 。
实现要点:
外观模式:对外提供一个非常简单的 export 静态方法,内部却整合了参数校验、并发控制、es查询初始化、处理器工厂、工作簿创建、资源清理等一整套复杂流程。对调用者而言,导出功能变得非常简单。
资源管理:
- 并发控制:使用
atomicinteger实现了一个简单的令牌桶限流器,是系统稳定性的重要保障。 - 资源清理:在
finally块中严格保证了workbook.close()/dispose()和scrollid的清理,避免了内存泄漏和资源悬挂,体现了良好的编程习惯。
实现了 applicationcontextaware:这是一个巧妙的设计,让这个静态工具类能够获取到 spring 容器中的 bean(excelexporthandlerfactory),解决了静态方法无法直接注入 spring bean 的问题。
5.esscrollutil(utils类) - 职责单一 & 封装
设计意图:封装复杂细节,提供友好api。将es滚动查询的三个步骤(初始化、滚动、清理)及其资源管理(transmittablethreadlocal)封装起来。
实现要点:
总结:架构图景
- 提供了
getfirstscrollid和nextscrollpage两个核心方法,内部处理了scroll_id的存储和传递,让业务代码可以像使用迭代器一样简单地进行滚动查询。 - 职责非常单一,就是管理es滚动查询,符合单一职责原则。
总结:架构图景
- 调用层 (
service) -> 门户层 (largeexcelutil):提供简单接口,负责流程编排和资源管理。 - 门户层 -> 策略工厂 (
excelexporthandlerfactory):根据上下文选择策略。 - 策略工厂 -> 具体策略 (
sampleexporthandler等):执行特定算法。 - 具体策略 -> 抽象模板 (
baseexcelexporter):复用基础流程和组件。 - 抽象模板 -> 工具层 (
esscrollutil):调用更底层的技术组件。
以上就是java导出excel实现八倍效率优化的方法详解的详细内容,更多关于java导出excel的资料请关注代码网其它相关文章!





发表评论