前言
io 流是 java 操作数据传输的核心工具,从简单的文件复制到复杂的对象持久化,都离不开 io 流的灵活运用。本文将通过三个实战场景 ——文件复制、文本读写、对象序列化存储,带你从原理到代码彻底掌握 io 流的实战技巧,每个场景都配备直观图示和优化方案,让你在实际开发中少走弯路。
一、实战场景一:文件复制 —— 字节流的核心应用
文件复制是 io 流最基础也最常用的场景,无论是图片、视频还是文档,本质上都是字节数据的传输。我们需要解决的核心问题是:如何高效地将源文件的字节数据传输到目标文件。
1.1 基础实现:字节流直接读写
最原始的文件复制可以通过fileinputstream(字节输入流)和fileoutputstream(字节输出流)实现,原理是逐字节或按字节数组读取源文件,再写入目标文件。
public class filecopybasic {
public static void main(string[] args) {
// 源文件和目标文件路径
string sourcepath = "source.jpg";
string targetpath = "target_basic.jpg";
// 声明流对象(try-with-resources语法自动关闭资源)
try (fileinputstream fis = new fileinputstream(sourcepath);
fileoutputstream fos = new fileoutputstream(targetpath)) {
byte[] buffer = new byte[1024]; // 缓冲区(一次读1024字节)
int len; // 实际读取的字节数
// 循环读取:当len=-1时表示读取完毕
while ((len = fis.read(buffer)) != -1) {
// 写入缓冲区中的有效数据(避免写入空字节)
fos.write(buffer, 0, len);
}
system.out.println("基础字节流复制完成!");
} catch (ioexception e) {
e.printstacktrace();
}
}
}
原理图示:字节流通过缓冲区批量传输数据,减少直接操作磁盘的次数(直接逐字节读写效率极低,必须用数组缓冲)。
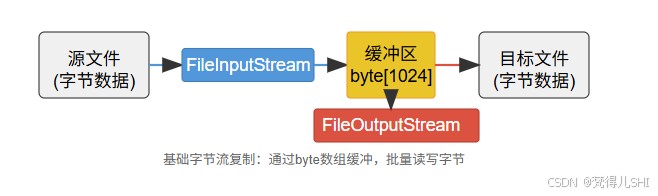
1.2 优化方案:缓冲流提升效率
基础字节流虽然能完成复制,但read()和write()仍会频繁触发系统调用。bufferedinputstream和bufferedoutputstream通过内置缓冲区(默认 8kb)进一步减少 io 次数,效率更高。
public class filecopywithbuffer {
public static void main(string[] args) {
string sourcepath = "source.jpg";
string targetpath = "target_buffer.jpg";
// 缓冲流包装基础字节流
try (bufferedinputstream bis = new bufferedinputstream(new fileinputstream(sourcepath));
bufferedoutputstream bos = new bufferedoutputstream(new fileoutputstream(targetpath))) {
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
// 缓冲流会自动刷新,大文件可手动调用bos.flush()避免数据滞留
}
system.out.println("缓冲流复制完成!");
} catch (ioexception e) {
e.printstacktrace();
}
}
}
为什么缓冲流更快?基础字节流的read()每次都从磁盘读数据,而缓冲流会一次性读取大量数据到内置缓冲区,后续read()直接从内存缓冲区获取,大幅减少磁盘 io 次数(磁盘 io 速度远低于内存)。
1.3 进阶方案:nio 的零拷贝复制
java nio 的filechannel提供了transferto()方法,支持零拷贝(数据直接从内核缓冲区传输到目标文件,不经过用户态),是大文件复制的最优选择。
public class filecopywithchannel {
public static void main(string[] args) {
string sourcepath = "source.mp4";
string targetpath = "target_channel.mp4";
try (filechannel inchannel = new fileinputstream(sourcepath).getchannel();
filechannel outchannel = new fileoutputstream(targetpath).getchannel()) {
// 传输数据:从输入通道到输出通道,每次最多传输integer.max_value字节
long position = 0;
long size = inchannel.size();
while (position < size) {
position += inchannel.transferto(position, integer.max_value, outchannel);
}
system.out.println("nio通道复制完成!");
} catch (ioexception e) {
e.printstacktrace();
}
}
}
三种方案对比:
| 实现方式 | 核心类 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 基础字节流 | fileinputstream | 简单直接 | 效率低(频繁 io) | 小文件、简单场景 |
| 缓冲字节流 | bufferedinputstream | 内置缓冲区,效率较高 | 仍有用户态 / 内核态切换 | 中大型文件 |
| nio 通道 | filechannel | 零拷贝,效率最高 | 代码稍复杂 | 超大文件、性能敏感场景 |
二、实战场景二:文本读写 —— 字符流与编码处理
文本文件(如.txt、.java)由字符组成,直接用字节流读写可能因编码问题导致乱码。字符流(reader/writer)专门处理字符数据,能自动完成字节与字符的转换。
2.1 基础字符流:filereader/filewriter
filereader和filewriter是字符流的基础实现,默认使用系统编码(可能导致跨平台乱码),适合简单场景。
public class textreadwritebasic {
public static void main(string[] args) {
string sourcetxt = "source.txt";
string targettxt = "target_basic.txt";
// 字符流读写文本
try (filereader fr = new filereader(sourcetxt);
filewriter fw = new filewriter(targettxt)) {
char[] buffer = new char[1024]; // 字符缓冲区
int len;
while ((len = fr.read(buffer)) != -1) {
fw.write(buffer, 0, len);
}
system.out.println("基础字符流读写完成!");
} catch (ioexception e) {
e.printstacktrace();
}
}
}
2.2 解决编码问题:inputstreamreader/outputstreamwriter
当文本文件编码(如 utf-8)与系统默认编码不一致时,必须用inputstreamreader和outputstreamwriter指定编码,避免乱码。
public class textreadwritewithcharset {
public static void main(string[] args) {
string sourcetxt = "source_utf8.txt";
string targettxt = "target_utf8.txt";
string charset = "utf-8"; // 明确指定编码
// 字节流→字符流(指定编码)
try (inputstreamreader isr = new inputstreamreader(
new fileinputstream(sourcetxt), charset);
outputstreamwriter osw = new outputstreamwriter(
new fileoutputstream(targettxt), charset)) {
char[] buffer = new char[1024];
int len;
while ((len = isr.read(buffer)) != -1) {
osw.write(buffer, 0, len);
}
system.out.println("指定编码的字符流读写完成!");
} catch (ioexception e) {
e.printstacktrace();
}
}
}
编码转换原理:文本文件存储的是字节(如 utf-8 编码的汉字占 3 字节),inputstreamreader按指定编码将字节转换为字符,outputstreamwriter再将字符转换为目标编码的字节。
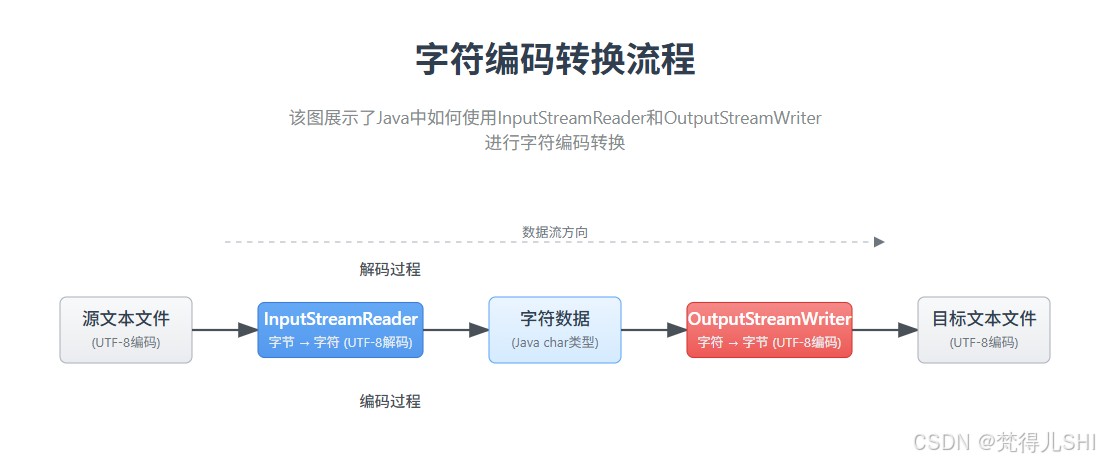
2.3 高效文本处理:缓冲字符流与特殊操作
bufferedreader和bufferedwriter是字符流的缓冲增强版,提供readline()(逐行读取)和newline()(跨平台换行)等实用方法,是文本处理的首选。
public class textreadwritewithbuffer {
public static void main(string[] args) {
string sourcetxt = "article.txt";
string targettxt = "article_copy.txt";
try (bufferedreader br = new bufferedreader(
new inputstreamreader(new fileinputstream(sourcetxt), "utf-8"));
bufferedwriter bw = new bufferedwriter(
new outputstreamwriter(new fileoutputstream(targettxt), "utf-8"))) {
string line; // 存储每行内容
// 逐行读取(readline()不包含换行符)
while ((line = br.readline()) != null) {
bw.write(line); // 写入一行内容
bw.newline(); // 换行(自动适配系统换行符:\n或\r\n)
}
system.out.println("缓冲字符流逐行读写完成!");
} catch (ioexception e) {
e.printstacktrace();
}
}
}
关键技巧:
readline()适合处理按行结构化的文本(如日志、csv);newline()比硬编码\n更通用,避免跨平台问题;- 大文件读写时,缓冲字符流的效率远高于基础字符流。
三、实战场景三:对象序列化 —— 对象的持久化存储
序列化是将对象转换为字节序列以便存储或传输的过程,反序列化则是将字节序列恢复为对象。java 通过serializable接口和对象流(objectinputstream/objectoutputstream)实现这一功能。
3.1 序列化的基本实现
步骤 1:定义可序列化的类(实现serializable接口)
import java.io.serializable;
import java.util.date;
// 实现serializable接口(标记接口,无方法)
public class user implements serializable {
// 序列化版本号(强烈建议显式声明,避免类结构变化导致反序列化失败)
private static final long serialversionuid = 1l;
private string username;
private int age;
private transient string password; // transient修饰的字段不参与序列化
private date registertime;
// 构造器、getter、setter、tostring()
public user(string username, int age, string password) {
this.username = username;
this.age = age;
this.password = password;
this.registertime = new date();
}
@override
public string tostring() {
return "user{username='" + username + "', age=" + age +
", password='" + password + "', registertime=" + registertime + "}";
}
}
步骤 2:使用对象流进行序列化和反序列化
import java.io.*;
public class objectserialization {
public static void main(string[] args) {
string filepath = "user.ser";
user user = new user("zhangsan", 25, "123456");
// 1. 序列化:将对象写入文件
try (objectoutputstream oos = new objectoutputstream(
new fileoutputstream(filepath))) {
oos.writeobject(user);
system.out.println("序列化完成:" + user);
} catch (ioexception e) {
e.printstacktrace();
}
// 2. 反序列化:从文件恢复对象
try (objectinputstream ois = new objectinputstream(
new fileinputstream(filepath))) {
user deserializeduser = (user) ois.readobject();
system.out.println("反序列化结果:" + deserializeduser);
// 注意:password为null(transient字段未被序列化)
} catch (ioexception | classnotfoundexception e) {
e.printstacktrace();
}
}
}
输出结果:
序列化完成:user{username='zhangsan', age=25, password='123456', registertime=...}
反序列化结果:user{username='zhangsan', age=25, password='null', registertime=...}
3.2 序列化的核心知识点
serializable 接口:是一个标记接口(无任何方法),仅用于告诉 jvm 该类可以被序列化。若类未实现此接口,序列化时会抛出
notserializableexception。serialversionuid 的作用:用于验证序列化和反序列化的类版本是否一致。若不显式声明,jvm 会根据类结构自动生成,类结构(如增减字段)变化会导致版本号改变,反序列化失败。建议所有可序列化类显式声明此常量。
transient 关键字:被
transient修饰的字段不参与序列化,反序列化时会被赋予默认值(如 null、0)。适合存储敏感信息(如密码)或无需持久化的临时数据。父类序列化规则:若父类未实现
serializable,则父类必须有默认无参构造器,否则反序列化时会报错(无法初始化父类字段)。
序列化流程图示:

3.3 序列化的应用场景与限制
应用场景:
- 对象持久化(如存储到文件、数据库 blob 字段);
- 网络传输(如 rpc 框架中对象的跨服务传输);
- 深拷贝(通过序列化 + 反序列化实现对象的完全复制)。
限制:
- 不能序列化静态字段(静态字段属于类,不属于对象);
- 循环引用的对象可序列化(jvm 会处理引用关系);
- 序列化后的字节流与 jvm 相关,跨语言兼容性差(可考虑 json、protobuf 等跨语言格式)。
四、io 流实战总结与最佳实践
通过三个场景的实战,我们可以总结出 io 流使用的核心原则:
选择合适的流类型:
- 字节流:处理非文本文件(图片、视频、二进制数据);
- 字符流:处理文本文件(需注意编码);
- 对象流:处理对象的序列化 / 反序列化。
优先使用缓冲流:缓冲流(
bufferedxxx)通过内置缓冲区减少 io 次数,效率远高于基础流,几乎所有场景都应优先使用。资源管理必须严谨:始终使用try-with-resources 语法(自动关闭资源),避免流未关闭导致的资源泄漏(尤其是文件流和网络流)。
关注编码问题:文本处理时必须明确指定编码(如 utf-8),避免依赖系统默认编码导致的乱码。
大文件优化:大文件复制优先用 nio 的
filechannel.transferto(),利用零拷贝提升性能;大文件读写避免一次性加载到内存,应分块处理。
io 流是 java 开发的基础技能,掌握这些实战技巧不仅能解决日常开发问题,更能帮助你理解 io 操作的底层原理。希望本文的三个实战场景能让你对 io 流的运用更加得心应手,欢迎在评论区分享你的实战经验!

总结
到此这篇关于java io流实战之文件复制、文本读写、对象序列化详细解析的文章就介绍到这了,更多相关java io流文件复制、文本读写、对象序列化内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论