一、聚合类开窗函数
1、sum(字段) over(开窗说明)
该函数是聚合类最常用的。
开窗说明:partition by–分组,并且没有去重效果,order by—排序。开窗说明可以不写。
聚合类开窗函数可以与未分组(group by)的字段一起显示。
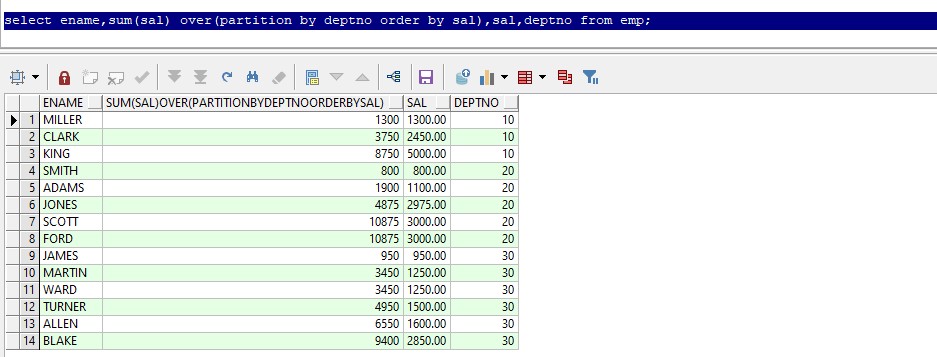
select ename,sum(sal) over(partition by deptno order by sal),deptno from emp;
例:以上查询为,各部门工资累加之后的结果。如:10部门,第一行为第一行累加到当前行的结果(1300),第二行为第一行累加到当前行的结果(1300+2450=3750),第三行为第一行累加到当前行的结果(1300+2450+5000 = 8750)。
运行效果:
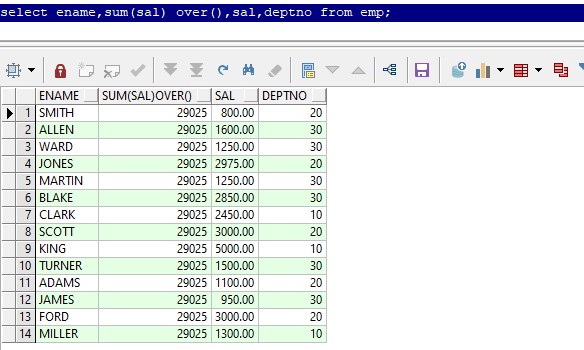
sum(sal) over()不分组不排序则,获取全公司工资的总和,使用效果与聚合函数sum()一致,但是结果有多条。运行效果:
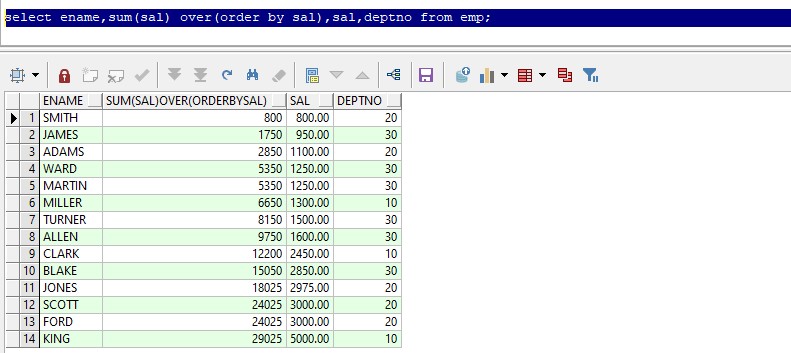
sum(sal) over(order by sal )只排序,默认是从第一行累加到当前行,如:第一行为运行效果:
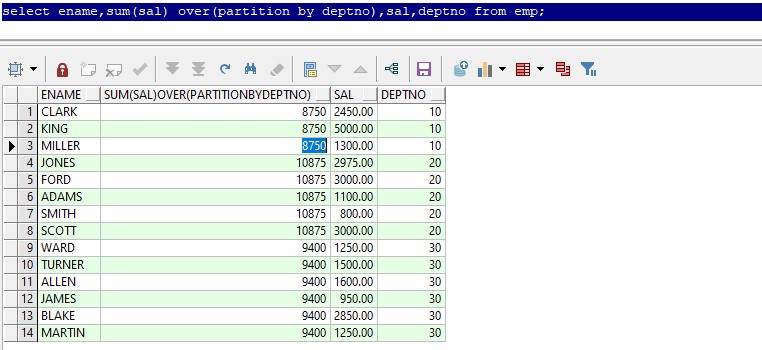
sum(sal) over(partition by deptno)只分组,查询结果为各部门的工资总和以及各部门每个员工的工资。
2、min()、max()、avg()、count(),用法与sum()一致
只需改变函数名,通过查询后的数据就可看出数据的特征,其他函数不怎么用就不全部举例了,下面就举两个例子。
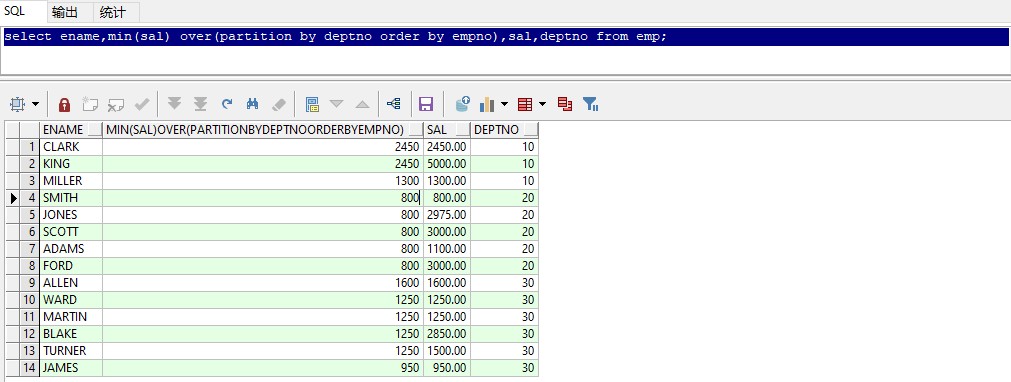
select ename,max(sal) over(partition by deptno order by empno),sal,deptno from emp;
查询跟部门内工资最高的员工。根据部门分组,比较组内第一行到组内当前的最高工资,如:10部门,第一行为2450,则最高为2450,。第二行为5000,比2450大,所以最高工资为5000,第三行为1300,比5000小,则最高工资还是5000。
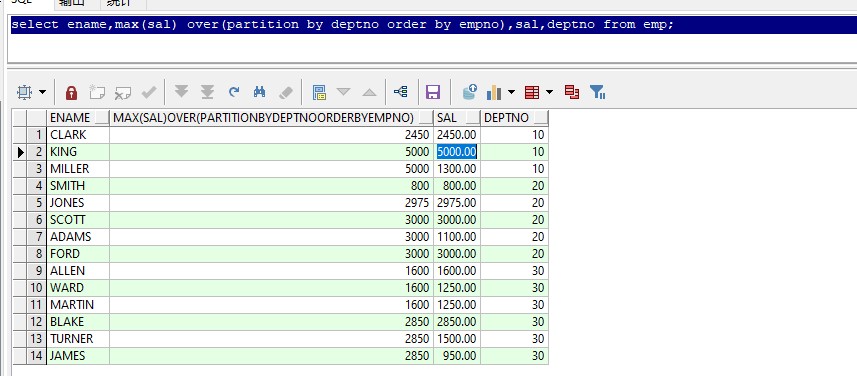
select ename,min(sal) over(partition by deptno order by empno),sal,deptno from emp;
查询跟部门内工资最高低的员工。根据部门分组,比较组内第一行到组内当前的最低工资,如:10部门,第一行为2450,则最低为2450。第二行为5000,比2450大,所以最低工资还是为2450,第三行为1300,比2450小,所以最低工资就位1300。
3、拓展:统计范围
范围值:
current row:当前行
n preceding:向上n行
n following:向下n行
unbounded preceding:起点开始,第一行开始
unbounded following:到终点,到最后一行
范围关键字:rows between and
select sum(sal) over(order by empno) s1, sum(sal) over(order by empno rows between current row and unbounded following) s2, sum(sal) over(order by empno rows between 1 preceding and 1 following) s3, sum(sal) over(order by empno rows between unbounded preceding and unbounded following) s4, sal,empno from emp;
- s1:表示累加。
- s2:表示当前行到最后一行,也是累减的效果,第一行是从第一行开始到最后一行全部员工工资相加的结果,第二行是从第二行开始到最后一行全部员工工资相加的结果,第三行则是从第三行开始到最后一行全部员工工资相加的结果,以此类推。
- s3:表示上一行到下一行,第一行的结果为第一行的上一行(无)、第一行、第一行的下一行(也就是第二行)相加的结果,0+800+1600=2400,第二行的结果则为第一行、第二行、第三行相加的结果,800+1600+1250=3650,以此类推。
- s4:表示从第一行到最后一行,效果与累加一样。
运行效果:
二、排名类开窗函数
row_number() over(开窗说明)、rank() over(开窗说明)、dense_rank() over(开窗说明)
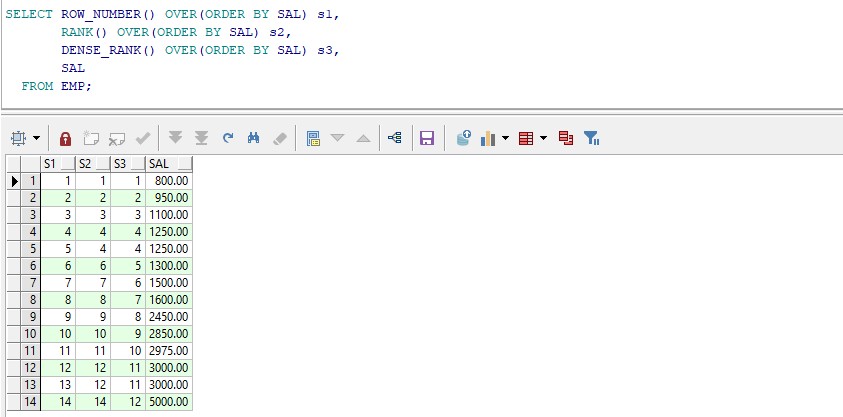
select row_number() over(order by sal) s1, rank() over(order by sal) s2, dense_rank() over(order by sal) s3, sal from emp;
按照员工工资进行排名,通过观察结果集数据可看出数据的特征所在。
三者的共同点与不同点
共同点:
函数后小括号都不写任何东西;
三者的开窗说明中,必须包含order by 关键字,不写则会报错;
不同点:
row_number 生成一组连续且不重复的序号 123456;
rank 有可能生成一组重复且不连续的序号 123356;
dense_rank 有可能生成一组重复且连续的序号 123345;
序号总数会变少
经典题型演练
查询用户连续登入三天及三天以上的用户信息:
先建表以及插入数据:
create table logintest(user_id number,log_date date); insert into logintest values(111,to_date(‘2021-06-01',‘yyyy-mm-dd')); insert into logintest values(111,to_date(‘2021-06-02',‘yyyy-mm-dd')); insert into logintest values(111,to_date(‘2021-06-03',‘yyyy-mm-dd')); insert into logintest values(111,to_date(‘2021-06-05',‘yyyy-mm-dd')); insert into logintest values(111,to_date(‘2021-06-08',‘yyyy-mm-dd')); insert into logintest values(222,to_date(‘2021-06-01',‘yyyy-mm-dd')); insert into logintest values(222,to_date(‘2021-06-03',‘yyyy-mm-dd')); insert into logintest values(222,to_date(‘2021-06-04',‘yyyy-mm-dd')); insert into logintest values(222,to_date(‘2021-06-06',‘yyyy-mm-dd')); insert into logintest values(222,to_date(‘2021-06-07',‘yyyy-mm-dd')); insert into logintest values(333,to_date(‘2021-06-01',‘yyyy-mm-dd')); insert into logintest values(333,to_date(‘2021-06-02',‘yyyy-mm-dd')); insert into logintest values(333,to_date(‘2021-06-04',‘yyyy-mm-dd')); insert into logintest values(333,to_date(‘2021-06-06',‘yyyy-mm-dd')); insert into logintest values(333,to_date(‘2021-06-07',‘yyyy-mm-dd')); commit;
查询用户登入表
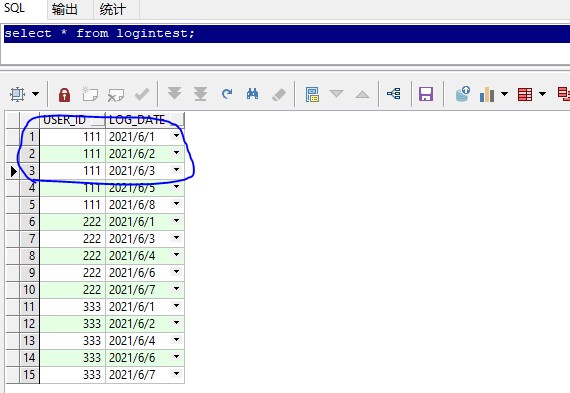
select * from logintest;
从数据中可看出111号用户,有三天是连续登入的,所以我们要查询的就是该用户的信息。
分析解题思路:
1.先利用row_number() over(order by )开窗函数进行一个组内排序,得出一个排序的结果(展示字段 jg)。
select user_id,log_date,row_number() over(partition by user_id order by log_date) jg from logintest;
运行效果:
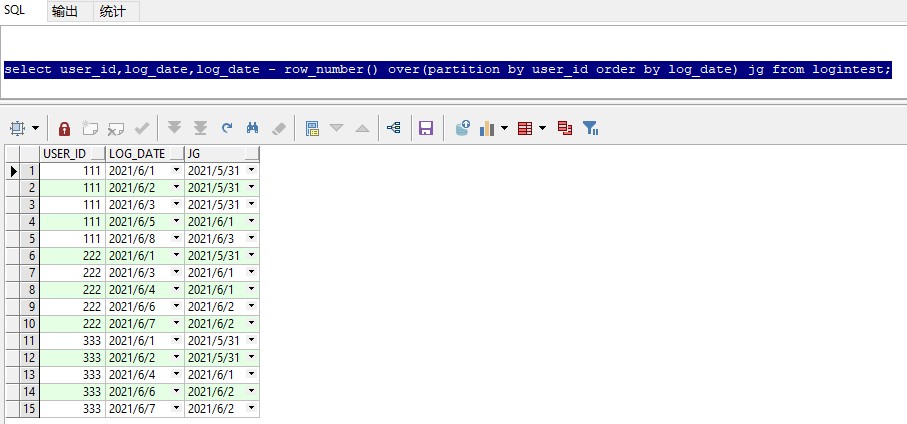
2.用登入日期减去这个结果,会得到一个新的日期,由于登入日期是按从小到大的排序,这个排序结果也是,连续登入相差的天数是1,排序相减也是1,如果是连续登入的日期减去对应的排序结果最后得到的日期是一样。
select user_id,log_date,log_date - row_number() over(partition by user_id order by log_date) jg from logintest;
运行效果:
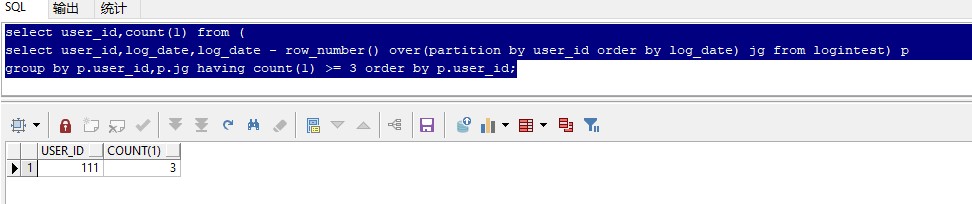
3.将以上得到的结果集当做一个子表,用子查询的方式再对该表按user_id,jg进行分组,并统计出现相同日期的次数,最后使用having过滤>=3的用户信息。
select user_id,count(1) from ( select user_id,log_date,log_date - row_number() over(partition by user_id order by log_date) jg from logintest) p group by p.user_id,p.jg having count(1) >= 3 order by p.user_id;
运行效果:
三、偏移类开窗函数
1、lead(字段,偏移值,缺省值) over(开窗说明)–向上偏移
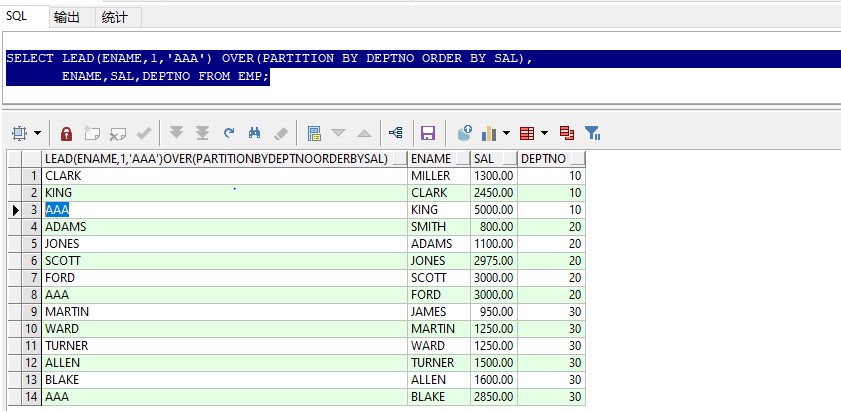
select lead(ename,1,‘aaa') over(partition by deptno order by sal), ename,sal,deptno from emp;
按照部门分组,在组内向上偏移一个单位,如:10部门,miller原本在第一位,现在进行了向上偏移,miller给过滤掉了,clark和king统统向上偏移了一位,第三位空出来的有缺省值’aaa’填补,偏移单位和缺省值可以不写,默认为1个单位和空。
开窗说明中必须存在关键字order by。
运行效果:
2、lag(字段,偏移值,缺省值) over(开窗说明)–向下偏移
使用方式与lead() over()一致,只是偏移方向改变了而已。
3、拓展
1.first_value(字段)over(开窗说明),获取某个字段下的第一行数据,开窗说明可以不写。
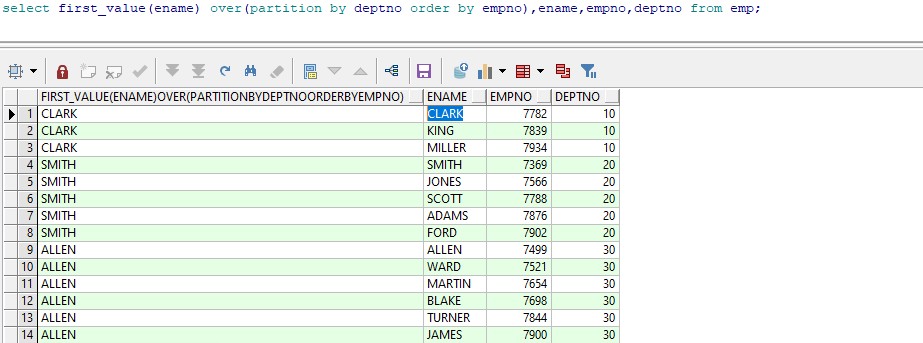
select first_value(ename) over(partition by deptno order by empno),ename,empno,deptno from emp;
例:进行组内排序,获取各部门中第一行的员工姓名,10部门第一行的员工姓名为clark。运行效果:
2.last_value(字段)over(开窗说明),获取某个字段下的最后一行数据,用法与first_value() over()一致。
四、占比类开窗函数
ratio_to_report(字段)over(开窗说明)
求某个值在全部范围内所占的比重。
注意:开窗说明中禁止使用order by 关键字,否则就会报错。
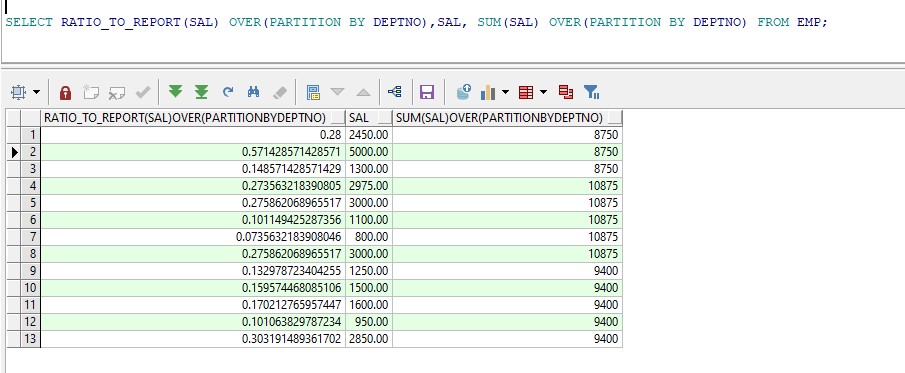
select ratio_to_report(sal) over(partition by deptno),sal, sum(sal) over(partition by deptno) from emp;
例:求各部门下各员工工资所占部门总工资的比重,10部门第一行,所占比重为2450.00/8750 = 0.28,运行效果:
五、切片类开窗函数
1、ntile(切分数量)over(开窗说明 )
ntile函数对一个数据分区中的有序结果集进行划分,将其分组为各个桶,并为每个小组分配一个唯一的组编号。
注意:开窗说明中必须包含order by 关键字,否则就会报错,可搭配partition by 分组使用。
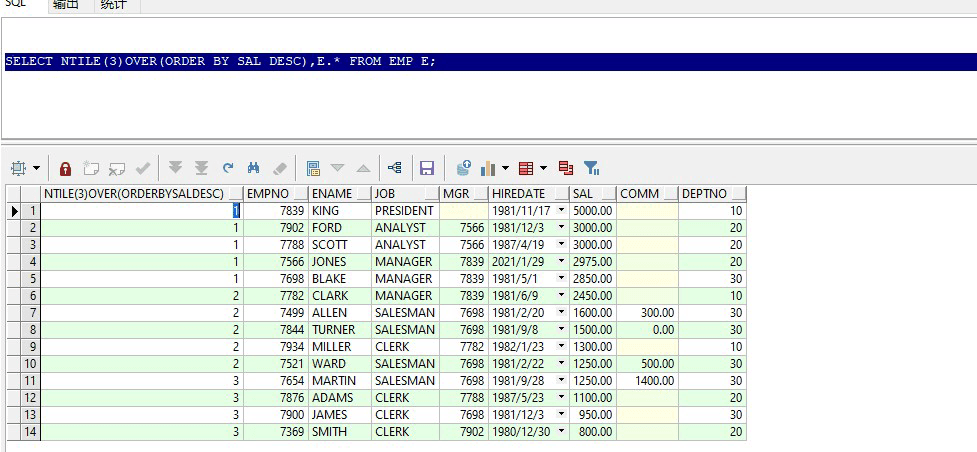
select ntile(3)over(order by sal desc),e.* from emp e;
例:按工资降序排序,分为三个级别(ntile(3)),系统会自动划分。运行效果:
总结
到此这篇关于oracle数据库开窗函数的文章就介绍到这了,更多相关oracle开窗函数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论