在oracle数据库中,in和not in的查询效率受多种因素影响,以下是关键点总结和优化建议:
1.in的效率
- 优化方式:
in通常会被优化为 or条件 或 半连接(semi-join),如果子查询关联到外部表,可能转为exists。- 若字段有索引,且优化器选择索引扫描(index scan),效率较高。
- 适用场景:
- 静态值列表较短时(例如
in (1,2,3))。 - 子查询结果集较小且能利用索引时。
- 静态值列表较短时(例如
2.not in的潜在问题
- null 值陷阱:
如果子查询结果包含null,not in会导致结果集为空(逻辑上等价于!= all)。需确保子查询字段非空(如添加where col is not null)。 - 效率问题:
- 若子查询结果集较大,
not in可能需要全表扫描,效率较低。 - 可能被优化为 反连接(anti-join),但需索引支持。
- 若子查询结果集较大,
- 替代方案:
优先使用not exists,避免null问题且通常更高效(尤其在子查询能利用索引时)。
3. 优化建议
使用 exists/not exists 替代:
-- 优于 not in select * from table1 t1 where not exists ( select 1 from table2 t2 where t2.id = t1.id );
exists在找到匹配项后立即终止子查询,减少计算量。- 对
null安全,无需额外处理。
确保索引有效:
- 为
in/not in涉及的字段创建索引(尤其是主键或高选择性字段)。 - 子查询的连接字段(如
t2.id)应建立索引。
- 为
处理长静态列表:
- 避免超过1000个元素的静态列表(如
in (1,2,...,1001)),可改用临时表或拆分查询。
- 避免超过1000个元素的静态列表(如
检查执行计划:
使用explain plan分析查询是否走索引或优化为高效的连接方式(如哈希反连接)。
4. 示例对比
场景:查询在表b中不存在的记录
- 低效写法(可能受null影响):
select * from tablea where id not in (select id from tableb);
- 高效改写:
select * from tablea a where not exists ( select 1 from tableb b where b.id = a.id );
5. 关键总结
| 操作符 | 效率影响因素 | 适用场景 | 注意事项 |
|---|---|---|---|
in | 索引、子查询结果集大小、静态列表长度 | 小结果集或静态短列表 | 避免超长静态列表 |
not in | 子查询中的null、索引缺失、结果集大小 | 需显式处理null的子查询 | 优先用 not exists 替代 |
exists | 子查询索引、关联字段 | 检查存在性,尤其是大表关联 | 对 null 安全 |
not exists | 子查询索引、关联字段 | 检查不存在性,替代 not in | 优于 not in 的通用选择 |
通过合理使用索引、避免 null 陷阱、改写为 exists/not exists,并结合执行计划分析,可以显著提升查询效率。
附:oracle中not in ()语法问题
在sql查询中使用isnotin子查询时遇到的问题,即当子查询返回值包含null时,条件始终无法匹配导致查询失败。作者通过排查发现并解释了这一现象,指出isnotin与null值的交互会导致条件始终返回false。解决方案是在子查询中过滤掉null值,通过添加'wherexxxisnotnull'来修复问题。
最近遇到一个sql,where条件中用了is not in (子查询)的语法来过滤数据,但整个sql执行时一直查不到东西
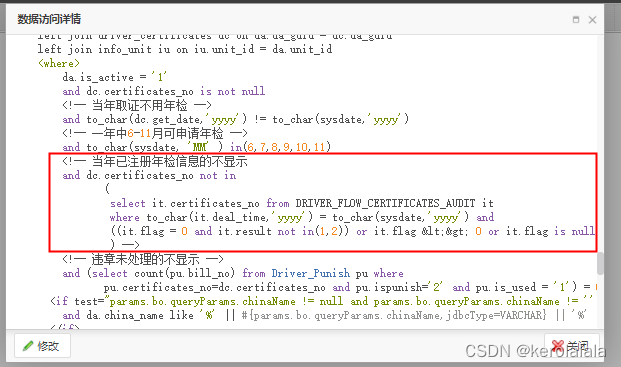
排查了下,最后定位到问题出在这个is not in ()条件中,于是将括号里面的子查询执行了下,发现他查询的字段中有一条数据为null值
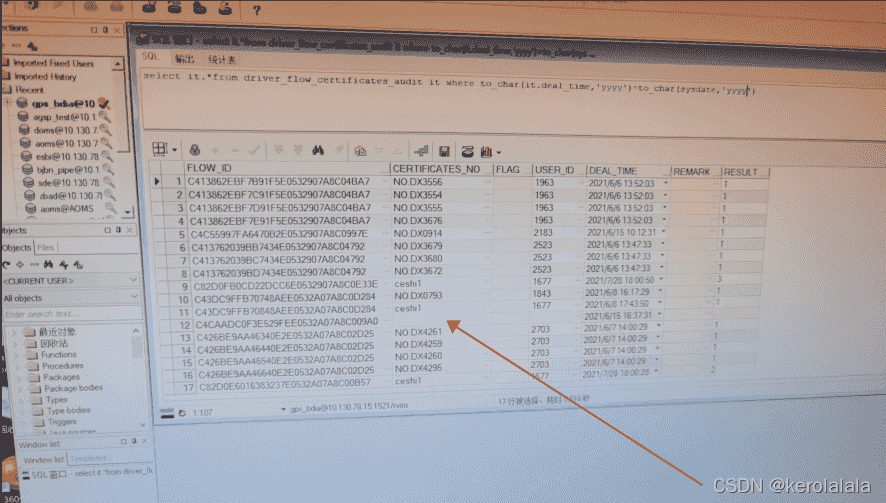
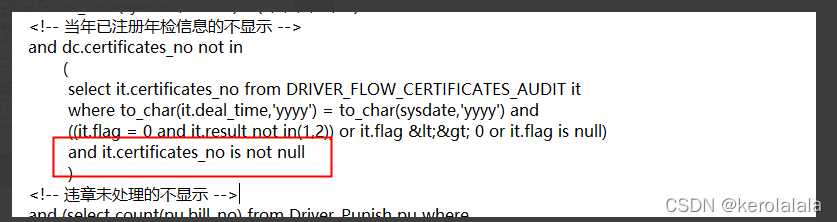
刚开始没看出有啥问题,百度一波后发现,如果is not in ()子查询返回值中有null值,那这个条件始终会返回false,导致整个sql啥都查询不到。
所以修复的方法就是在子查询中过滤掉空值,子查询后加上 "where xxx is not null"即可
到此这篇关于oracle中使用in和not in查询效率总结和优化建议的文章就介绍到这了,更多相关oracle in和not in查询效率内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论