doris 中出现 “failed to send brpc when exchange” 错误,通常与 doris 的分布式执行框架中 brpc 通信异常相关,主要发生在查询执行过程中不同节点(fe/be 或 be 之间)通过 exchange 算子传递数据时。

可能的原因及解决方案
1. 网络问题
节点间网络不通或延迟过高:
- 检查 be 节点之间的网络连通性(使用
ping、telnet等工具)。 - 查看网络是否存在丢包(
mtr或traceroute命令),高延迟或丢包会导致 brpc 通信超时。 - 确保节点间防火墙规则允许 doris 通信端口(默认的 brpc 端口等)。
结果:
- ping是通的,telnet也是通的,防火墙没有开
2. brpc 配置不合理
- 超时时间过短:
在 be.conf 中适当调大 brpc 相关超时参数:
brpc_arrow_flight_work_pool_max_queue_size=-1 brpc_arrow_flight_work_pool_threads=-1 brpc_connection_check_timeout_ms=10000 brpc_heavy_work_pool_max_queue_size=-1 brpc_heavy_work_pool_threads=-1 brpc_idle_timeout_sec=-1 brpc_light_work_pool_max_queue_size=-1 brpc_light_work_pool_threads=-1 brpc_max_body_size=3147483648 brpc_num_threads=256 brpc_port=8060 brpc_socket_max_unwritten_bytes=-1 brpc_streaming_client_batch_bytes=262144
- 连接数限制:
检查是否因连接数过多导致失败,可调整 grpc_threadmgr_threads_nums 4096 等参数。
结果:
3. 节点负载过高
be 节点内存/cpu 耗尽:
- 查看 be 节点的资源使用情况(
top、free命令),若内存不足可能导致 brpc 线程无法正常工作。 - 临时减轻负载: kill 大查询任务,避免资源竞争。
- 长期优化:增加 be 节点数量,或调整查询并发度(
max_concurrent_queries)。
结果:
- 内存正常、cpu正常、磁盘io异常(使用iotop可以看到有很多basecompaction)
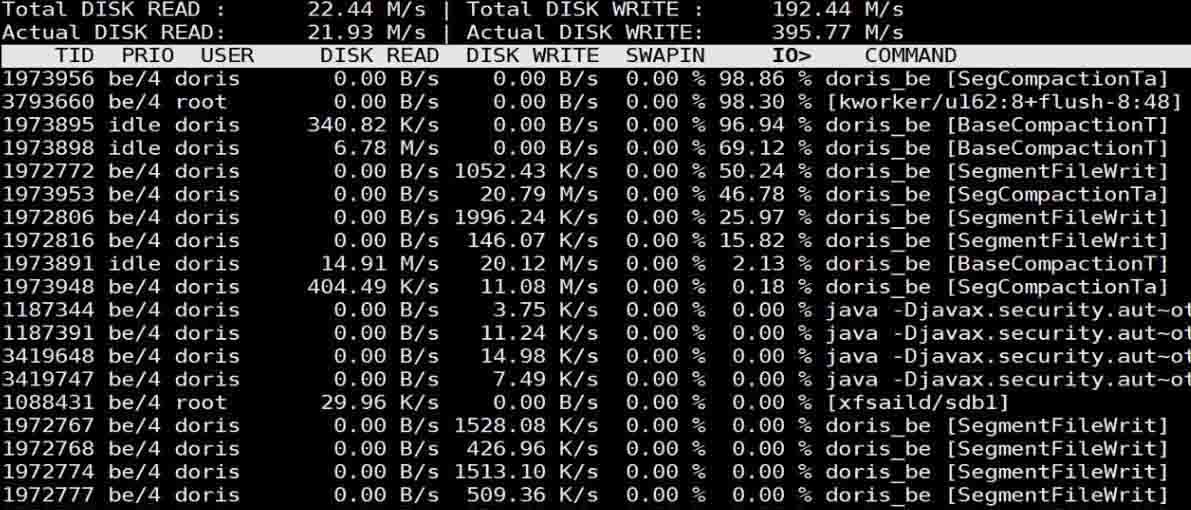
4. 数据倾斜或查询计划不合理
exchange 算子处理数据量过大:
- 某些查询可能因数据倾斜导致单个 exchange 节点需要处理远超预期的数据量,引发通信失败。
- 优化 sql:检查是否有大表 join 未指定合理的分桶键,或聚合操作未做预聚合。
- 查看查询计划:通过
explain分析 exchange 算子的分布情况,调整分桶策略或 sql 写法。
结果:
- 大表分桶数量设置不合理
5. 节点状态异常
be 节点心跳异常或已下线:
- 检查 fe 控制台(
http://fe_host:8030)的 “backends” 页面,确认所有 be 节点状态正常(alive)。 - 若节点异常,尝试重启 be 服务:
sh bin/stop_be.sh && sh bin/start_be.sh。 - 检查 be 日志(
log/be.info),搜索 “brpc” 相关错误信息,定位具体故障节点。
结果:
- 节点都正常
6. 版本兼容性问题
若近期升级过 doris 版本,可能存在 brpc 协议不兼容的情况,建议:
- 确认所有节点(fe/be)版本一致。
- 参考官方升级文档,检查是否遗漏了某些配置项的更新。
结果:
- 不存在版本兼容问题
排查步骤建议
- 查看 fe 日志(
log/fe.info)和对应 be 节点的日志(log/be.info),定位具体是哪个节点间的通信失败。 - 检查涉事节点的网络和资源状态。
- 针对频繁出现该错误的查询,优化其 sql 或表结构。
- 逐步调整 brpc 相关参数,观察是否改善。
- 通过be.info查看每个query的实例数量:
cat ./be.info |grep "total fragment num on current host"|awk '{print $1"-"$2,$6,$16,$23}'|awk -f '[ ,]' '$4>100 {print $0}'
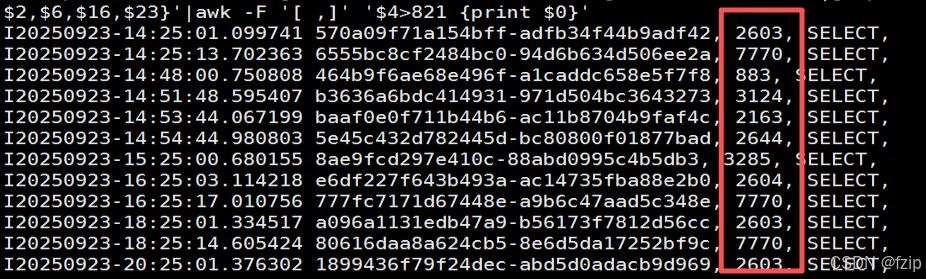
上千的特别大概率都是不合理的。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。



发表评论