前言
在网站测试、ui审查或文档编写过程中,我们常常需要对网站的所有页面进行截图记录。手动逐页访问并截图不仅效率低下,还容易遗漏。今天,我将分享如何使用python开发一个自动化工具,实现一键遍历网站所有链接并生成带截图的excel报告。
项目需求
我们的目标是开发一个桌面应用程序,具备以下功能:
- 自动提取站内链接:解析网页中的所有同域名链接
- 智能点击操作:首次访问时自动点击特定按钮(如"进入关怀版")
- 完整页面截图:截取包括滚动区域在内的整个网页
- 生成详细报告:将链接信息和截图整理成excel表格
技术选型
核心技术栈
wxpython:构建图形用户界面
selenium:控制浏览器自动化操作
beautifulsoup:解析html提取链接
openpyxl:生成excel报告
为什么选择selenium
相比传统的网页截图方案,selenium具有以下优势:
- 支持完整页面截图(包括滚动区域)
- 可以执行javascript交互操作
- 支持多种浏览器(chrome、firefox等)
- 能够处理动态加载的内容
效果图
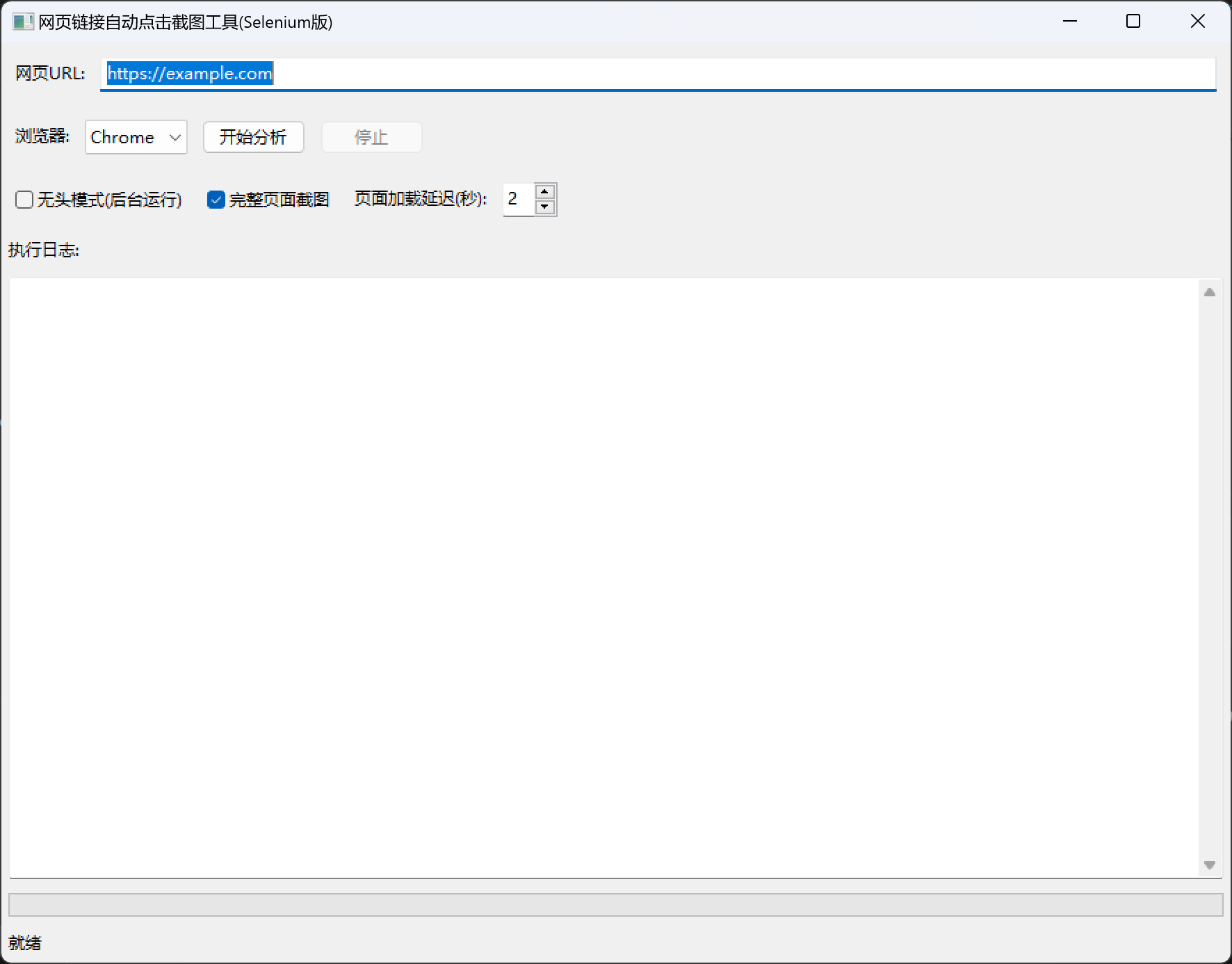
核心功能实现
1. gui界面设计
使用wxpython创建简洁直观的操作界面:
class weblinkclickerframe(wx.frame):
def __init__(self):
super().__init__(parent=none, title='网页链接自动点击截图工具', size=(900, 700))
# url输入框
self.url_input = wx.textctrl(panel, value="https://example.com")
# 浏览器选择
self.browser_choice = wx.choice(panel, choices=['chrome', 'firefox'])
# 功能选项
self.headless_cb = wx.checkbox(panel, label="无头模式(后台运行)")
self.full_page_cb = wx.checkbox(panel, label="完整页面截图")
self.delay_spin = wx.spinctrl(panel, value="2", min=1, max=10)
# 进度显示
self.progress_text = wx.textctrl(panel, style=wx.te_multiline | wx.te_readonly)
self.progress_gauge = wx.gauge(panel, range=100)
界面包含以下要素:
url输入框和浏览器选择
- 无头模式、完整截图等选项
- 实时日志显示和进度条
- 开始/停止按钮
2. selenium浏览器初始化
支持chrome和firefox两种浏览器,并提供无头模式选项:
def init_driver(self):
browser_type = self.browser_choice.getstringselection()
headless = self.headless_cb.getvalue()
if browser_type == 'chrome':
options = options()
if headless:
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--window-size=1920,1080')
self.driver = webdriver.chrome(options=options)
else:
options = firefoxoptions()
if headless:
options.add_argument('--headless')
self.driver = webdriver.firefox(options=options)
关键配置说明:
- --headless:后台运行,不显示浏览器窗口
- --no-sandbox:避免权限问题
- --window-size:设置浏览器窗口大小
3. 智能按钮点击
实现首次访问时自动点击"进入关怀版"按钮,使用多种定位策略提高成功率:
def click_care_button(self):
care_button = none
# 方式1: 通过文本内容查找
try:
care_button = self.driver.find_element(by.xpath, "//*[contains(text(), '进入关怀版')]")
except:
pass
# 方式2: 通过链接文本查找
if not care_button:
try:
care_button = self.driver.find_element(by.link_text, "进入关怀版")
except:
pass
# 方式3: 通过部分链接文本查找
if not care_button:
try:
care_button = self.driver.find_element(by.partial_link_text, "关怀版")
except:
pass
# 方式4: 遍历所有按钮
if not care_button:
buttons = self.driver.find_elements(by.tag_name, "button")
for btn in buttons:
if "关怀版" in btn.text:
care_button = btn
break
# 点击按钮
if care_button:
care_button.click()
time.sleep(2) # 等待页面跳转
定位策略:
- xpath文本内容匹配
- 完整链接文本
- 部分链接文本
- 遍历button标签
- 遍历a标签
这种多重策略能够应对不同网站的html结构差异。
4. 站内链接提取
使用beautifulsoup解析html,筛选出所有站内链接:
def extract_links(self, url):
self.driver.get(url)
time.sleep(self.delay_spin.getvalue())
# 点击特定按钮(如果存在)
self.click_care_button()
# 解析页面
html = self.driver.page_source
soup = beautifulsoup(html, 'html.parser')
base_domain = urlparse(url).netloc
# 提取链接
links = []
for a_tag in soup.find_all('a', href=true):
href = a_tag['href']
full_url = urljoin(url, href)
# 只保留站内链接
if urlparse(full_url).netloc == base_domain:
link_text = a_tag.get_text(strip=true) or '无标题'
links.append({'text': link_text, 'url': full_url})
# 去重
unique_links = []
seen_urls = set()
for link in links:
if link['url'] not in seen_urls:
seen_urls.add(link['url'])
unique_links.append(link)
return unique_links
关键点:
- 使用urljoin处理相对路径
- 通过域名比对筛选站内链接
- 自动去重避免重复截图
5. 完整页面截图
这是整个项目的核心功能。使用chrome的cdp(chrome devtools protocol)实现真正的全页面截图:
def take_full_page_screenshot(self, filepath):
if isinstance(self.driver, webdriver.chrome):
# 获取页面完整尺寸
metrics = self.driver.execute_cdp_cmd('page.getlayoutmetrics', {})
width = metrics['contentsize']['width']
height = metrics['contentsize']['height']
# 使用cdp截图
screenshot = self.driver.execute_cdp_cmd('page.capturescreenshot', {
'clip': {
'width': width,
'height': height,
'x': 0,
'y': 0,
'scale': 1
},
'capturebeyondviewport': true # 关键参数
})
# 保存截图
import base64
with open(filepath, 'wb') as f:
f.write(base64.b64decode(screenshot['data']))
else:
# firefox使用标准方法
self.driver.save_screenshot(filepath)
技术亮点:
- page.getlayoutmetrics:获取页面真实尺寸
- capturebeyondviewport: true:允许截取视口外内容
- 自动处理base64编码
6. 生成excel报告
使用openpyxl将数据和截图整合到excel文件:
def generate_excel(self):
wb = openpyxl.workbook()
ws = wb.active
ws.title = "链接截图报告"
# 设置表头
headers = ['序号', '按钮名称', '链接地址', '截图']
ws.append(headers)
# 设置列宽
ws.column_dimensions['b'].width = 30
ws.column_dimensions['c'].width = 50
ws.column_dimensions['d'].width = 60
# 添加数据和截图
for data in self.links_data:
row = ws.max_row + 1
ws.cell(row, 1, data['index'])
ws.cell(row, 2, data['text'])
ws.cell(row, 3, data['url'])
# 插入截图
if data['screenshot'] and os.path.exists(data['screenshot']):
img = xlimage(data['screenshot'])
img.width = 400
img.height = 300
ws.add_image(img, f'd{row}')
ws.row_dimensions[row].height = 225
# 保存文件
excel_path = os.path.join(self.screenshot_dir, "链接报告.xlsx")
wb.save(excel_path)
报表特点:
- 自动调整列宽和行高
- 嵌入式截图,直接查看
- 包含序号、标题、url等完整信息
7. 多线程处理
为避免阻塞ui,将耗时操作放在独立线程中执行:
def on_start(self, event):
self.is_running = true
thread = threading.thread(target=self.run_analysis, args=(url,))
thread.daemon = true
thread.start()
def run_analysis(self, url):
try:
# 初始化浏览器
self.init_driver()
# 提取链接
links = self.extract_links(url)
# 处理每个链接
for index, link in enumerate(links):
if not self.is_running: # 支持中途停止
break
self.process_link(link, index)
self.update_progress(int((index / len(links)) * 100))
# 生成报告
self.generate_excel()
finally:
self.driver.quit()
线程安全:
- 使用wx.callafter更新ui
- 设置daemon=true确保程序能够正常退出
- 添加停止标志支持用户中断
安装部署
1. 安装python依赖
pip install wxpython selenium beautifulsoup4 openpyxl pillow
2. 安装浏览器驱动
chrome驱动(推荐):
# 自动管理驱动 pip install webdriver-manager
或手动下载:chromedriver下载
firefox驱动:
从 geckodriver releases 下载
3. 运行程序
python web_link_clicker.py
使用指南
基本操作
1.输入url:在输入框中填写要分析的网站首页地址
2.选择浏览器:chrome或firefox(推荐chrome)
3.配置选项:
- 勾选"无头模式"后台运行
- 勾选"完整页面截图"捕获整个页面
- 调整页面加载延迟(1-10秒)
4.开始分析:点击"开始分析"按钮
5.查看结果:完成后会弹出提示,在生成的文件夹中查看excel报告
运行流程
输入url → 点击开始 → 初始化浏览器 → 打开首页
↓
点击"进入关怀版"(如有)→ 提取所有站内链接
↓
逐个访问链接 → 完整页面截图 → 更新进度
↓
生成excel报告 → 关闭浏览器 → 完成
输出内容
程序会在工作目录下生成一个以时间戳命名的文件夹,包含:
- 所有截图png文件:按序号_链接名称命名
- 链接报告.xlsx:包含序号、按钮名称、url和嵌入截图的完整报告
功能特色
1. 智能容错
找不到特定按钮时自动跳过,不影响后续流程
截图失败时记录日志但继续处理其他链接
支持中途停止,已完成的数据会被保留
2. 用户体验
实时日志显示当前操作
进度条展示任务完成度
完成后自动弹出文件路径提示
3. 灵活配置
无头模式节省系统资源
可调节延迟适应不同网速
支持chrome和firefox双浏览器
实际应用场景
1. 网站测试
qa团队可以使用此工具快速生成网站所有页面的截图档案,便于:
- 版本对比
- ui一致性检查
- 问题定位和记录
2. 文档编写
技术文档编写者可以:
- 自动生成产品界面截图
- 制作操作手册配图
更新帮助文档
3. 竞品分析
市场人员可以:
- 快速获取竞品网站截图
- 分析页面布局和功能
- 制作对比报告
4. 网站归档
运维团队可以:
- 定期保存网站状态
- 版本发布前后对比
- 历史版本存档
进阶优化
1. 添加webdriver-manager
自动管理浏览器驱动版本:
from webdriver_manager.chrome import chromedrivermanager from selenium.webdriver.chrome.service import service service = service(chromedrivermanager().install()) self.driver = webdriver.chrome(service=service, options=options)
2. 增加等待策略
使用显式等待提高稳定性:
from selenium.webdriver.support.ui import webdriverwait from selenium.webdriver.support import expected_conditions as ec wait = webdriverwait(self.driver, 10) element = wait.until(ec.presence_of_element_located((by.id, "content")))
3. 添加异常处理
更细致的错误分类:
try:
self.driver.get(url)
except timeoutexception:
self.log("页面加载超时")
except webdriverexception as e:
self.log(f"浏览器错误: {str(e)}")
4. 支持更多格式
除了excel,还可以生成:
- pdf报告
- html网页
- markdown文档
常见问题
q1: chrome驱动版本不匹配
解决方案:
- 使用webdriver-manager自动管理
- 或手动下载与chrome版本匹配的驱动
q2: 截图不完整
确保勾选"完整页面截图",且使用chrome浏览器(firefox不支持完整截图)
q3: 页面加载太慢
增加"页面加载延迟"时间,或检查网络连接
q4: 找不到"进入关怀版"按钮
这是正常的,程序会自动跳过此步骤继续执行
以上就是python+wxpython打造智能网页截图工具的详细内容,更多关于python网页截图的资料请关注代码网其它相关文章!





发表评论