前言
在日常数据处理工作中,我们经常遇到需要将大型csv或excel文件按照某些条件进行拆分的需求。比如将全国销售数据按地区拆分,或者将用户数据按部门分类等。手动处理这些任务不仅耗时,还容易出错。
今天,我将分享如何使用python和tkinter开发一个功能强大、界面友好的文件拆分工具,让数据处理变得轻松高效。
项目背景与需求分析
业务场景
- 数据分析师:需要将大型数据集按维度拆分进行分析
- 企业管理:将员工数据按部门、地区等维度分发
- 销售团队:将销售数据按区域、产品线拆分
- 项目管理:将项目数据按阶段、负责人拆分
核心需求
- 多格式支持:支持csv和excel文件格式
- 灵活拆分:可按任意列进行数据分组拆分
- 表头设置:支持指定任意行作为列名,适应各种excel格式
- 工作表选择:支持excel多工作表文件的工作表选择和批量应用
- 行数控制:支持设置每个拆分文件的最大行数
- 格式选择:输出文件可选择csv或excel格式
- 用户友好:图形界面操作,无需编程基础
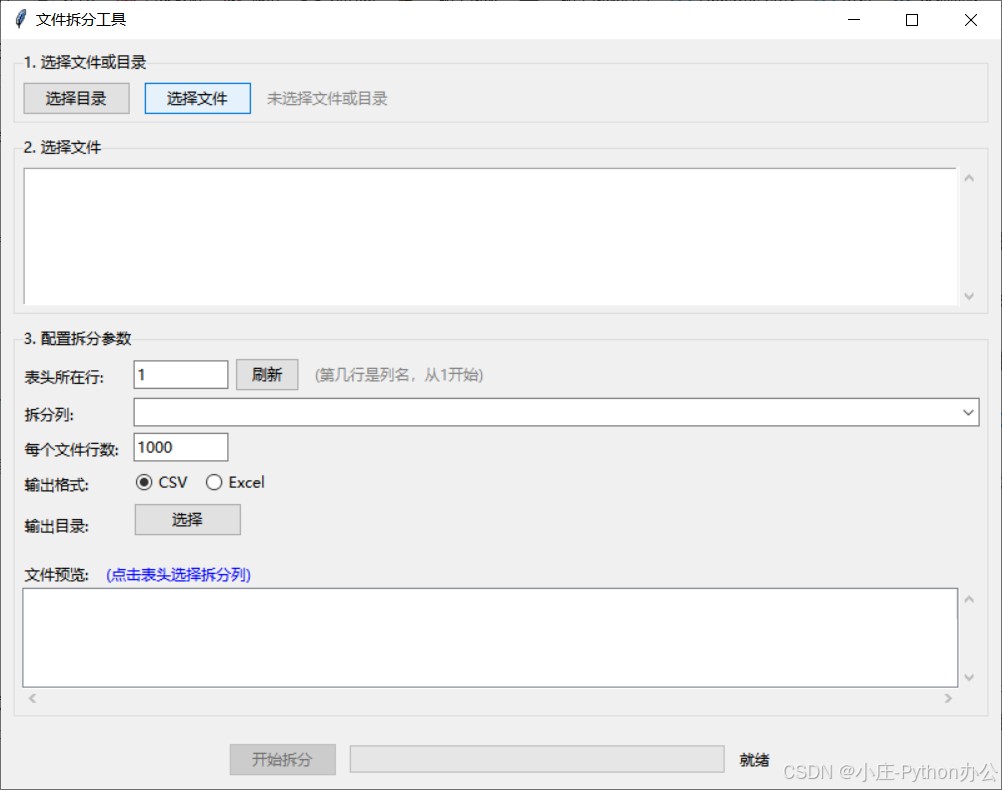
效果图
技术选型与架构设计
技术栈
- gui框架:tkinter(python内置,无需额外安装)
- 数据处理:pandas(强大的数据分析库)
- excel支持:openpyxl、xlrd(excel文件读写)
- 多线程:threading(避免界面冻结)
架构特点
┌─────────────────┐
│ 用户界面层 │ ← tkinter gui
├─────────────────┤
│ 业务逻辑层 │ ← 文件处理、拆分逻辑
├─────────────────┤
│ 数据访问层 │ ← pandas数据操作
└─────────────────┘
核心功能实现
1. 智能文件选择
def select_single_file(self):
"""选择单个文件"""
file_path = filedialog.askopenfilename(
title="选择csv或excel文件",
filetypes=[
("所有支持的文件", "*.csv;*.xlsx;*.xls"),
("csv文件", "*.csv"),
("excel文件", "*.xlsx;*.xls"),
("所有文件", "*.*")
]
)
设计亮点:
- 提供两种选择方式:目录批量选择 + 单文件直选
- 智能文件类型过滤,避免选择错误格式
- 自动文件预览和列信息加载
2. 智能编码检测
# csv文件编码自动检测
encodings = ['utf-8', 'gbk', 'gb2312', 'utf-8-sig']
for encoding in encodings:
try:
self.file_data = pd.read_csv(self.selected_file, encoding=encoding)
break
except unicodedecodeerror:
continue
解决痛点:
- 自动处理中文编码问题
- 支持多种常见编码格式
- 无需用户手动指定编码
3. excel多工作表支持
def load_file_preview(self):
if self.selected_file.endswith(('.xlsx', '.xls')):
# 检测所有工作表
excel_file = pd.excelfile(self.selected_file)
self.excel_sheets = excel_file.sheet_names
# 填充工作表选择下拉框
self.sheet_combo['values'] = self.excel_sheets
self.show_sheet_selection()
# 默认选择第一个工作表
if not self.current_sheet or self.current_sheet not in self.excel_sheets:
self.current_sheet = self.excel_sheets[0]
self.sheet_var.set(self.current_sheet)
功能特点:
- 智能检测:自动识别excel文件中的所有工作表
- 动态ui:仅在excel文件时显示工作表选择框
- 批量应用:选定的工作表设置应用到所有excel文件
- 用户提示:清晰说明批量处理规则
4. 高效拆分算法
def split_file(self):
# excel文件使用指定工作表
if self.selected_file.endswith(('.xlsx', '.xls')):
sheet_name = self.current_sheet if self.current_sheet else 0
full_data = pd.read_excel(self.selected_file, sheet_name=sheet_name, header=header_row)
# 按指定列分组
grouped = full_data.groupby(split_column)
for group_name, group_data in grouped:
# 如果组数据超过指定行数,进一步拆分
if len(group_data) > rows_per_file:
for j in range(0, len(group_data), rows_per_file):
chunk = group_data.iloc[j:j+rows_per_file]
# 保存文件...
算法优势:
- 内存友好:分块处理大文件
- 双重拆分:先按列分组,再按行数拆分
- 智能命名:自动生成有意义的文件名
- 工作表支持:完整支持excel多工作表处理
用户体验设计
1. 渐进式操作流程
选择文件/目录 → 预览数据 → 配置参数 → 执行拆分 → 查看结果
2. 实时反馈机制
- 进度条显示:实时显示拆分进度
- 状态提示:每个操作步骤都有状态反馈
- 手动刷新控制:点击"刷新"按钮更新预览,智能验证表头行号输入
- 错误处理:友好的错误提示和异常处理
3. 界面布局优化
# 响应式布局设计 main_frame.columnconfigure(1, weight=1) main_frame.rowconfigure(2, weight=1) # 分区域功能组织 select_frame = ttk.labelframe(main_frame, text="1. 选择文件或目录") file_frame = ttk.labelframe(main_frame, text="2. 选择文件") config_frame = ttk.labelframe(main_frame, text="3. 配置拆分参数")
性能优化策略
1. 多线程处理
def start_split(self):
# 在新线程中执行拆分,避免界面冻结
thread = threading.thread(target=self.split_file)
thread.daemon = true
thread.start()
2. 内存优化
- 分块读取:大文件分块处理,避免内存溢出
- 预览限制:只加载前100行用于预览
- 及时释放:处理完成后及时释放内存
3. 文件i/o优化
- 批量写入:减少磁盘i/o次数
- 格式优化:根据需要选择最适合的输出格式
实际应用案例
案例1:销售数据分析
场景:某公司需要将全国销售数据按地区拆分给各区域经理
操作步骤:
- 选择包含全国销售数据的excel文件
- 选择"地区"列作为拆分依据
- 设置每个文件最多5000行
- 选择excel格式输出
- 一键拆分,生成各地区数据文件
结果:原本需要手动操作2小时的工作,现在30秒完成!
案例2:用户数据分发
场景:hr部门需要将员工信息按部门分发
操作步骤:
- 选择员工信息csv文件
- 按"部门"列拆分
- 设置每个文件1000行
- 输出csv格式便于后续处理
效果:自动生成各部门员工信息文件,大大提高工作效率
案例3:多工作表excel文件处理
场景:财务部门需要处理包含多个工作表的年度报表,只需要"销售明细"工作表的数据
操作步骤:
- 选择包含多个工作表的excel文件
- 从工作表下拉框中选择"销售明细"
- 选择"产品类别"列作为拆分依据
- 设置批量处理目录,应用相同设置到所有excel文件
- 一键处理,所有文件都使用"销售明细"工作表进行拆分
优势:
- 统一处理:批量处理时自动应用工作表设置
- 智能提示:界面清晰提示批量处理规则
- 错误处理:自动跳过不包含指定工作表的文件
扩展功能展望
近期规划
- excel多工作表支持:支持选择和批量应用工作表设置
- 自定义过滤:支持按条件过滤数据
- 模板保存:保存常用的拆分配置
- 日志记录:详细的操作日志
长期规划
- 云端处理:支持云端大文件处理
- api接口:提供程序化调用接口
- 插件系统:支持自定义处理插件
- 数据可视化:拆分结果的图表展示
开发心得与总结
技术收获
- tkinter进阶:掌握了复杂gui应用的开发技巧
- pandas优化:学会了大数据文件的高效处理方法
- 用户体验:深入理解了用户友好界面的设计原则
最佳实践
- 异常处理:完善的错误处理机制是用户体验的关键
- 性能优化:多线程和内存管理对大文件处理至关重要
- 界面设计:清晰的操作流程和实时反馈提升用户满意度
项目价值
- 效率提升:将小时级的手动操作缩短到分钟级
- 错误减少:自动化处理避免人为错误
- 技能普及:让非技术人员也能高效处理数据
结语
这个文件拆分工具的开发过程让我深刻体会到,好的工具不仅要功能强大,更要简单易用。通过python和tkinter的结合,我们可以快速开发出实用的桌面应用,解决实际工作中的痛点问题。
希望这个项目能够帮助更多的朋友提高数据处理效率。如果你有任何建议或想法,欢迎交流讨论!
项目信息
- 开发语言:python 3.6+
- 主要依赖:pandas, openpyxl, xlrd
- 运行环境:windows/macos/linux
- 项目类型:开源工具
快速开始:
# 安装依赖 pip install -r requirements.txt # 运行程序 python file_splitter.py
让数据处理变得更简单,让工作变得更高效!
到此这篇关于基于python编写文件拆分工具(兼容excel&csv)的文章就介绍到这了,更多相关python文件拆分内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论