java 集合框架全解析
java 集合框架是 java 编程中最基础、最常用的部分之一。它为我们提供了一整套标准化的数据结构和算法实现,包括 list、set、queue、map 等,用于高效地存储、访问和操作对象集合。
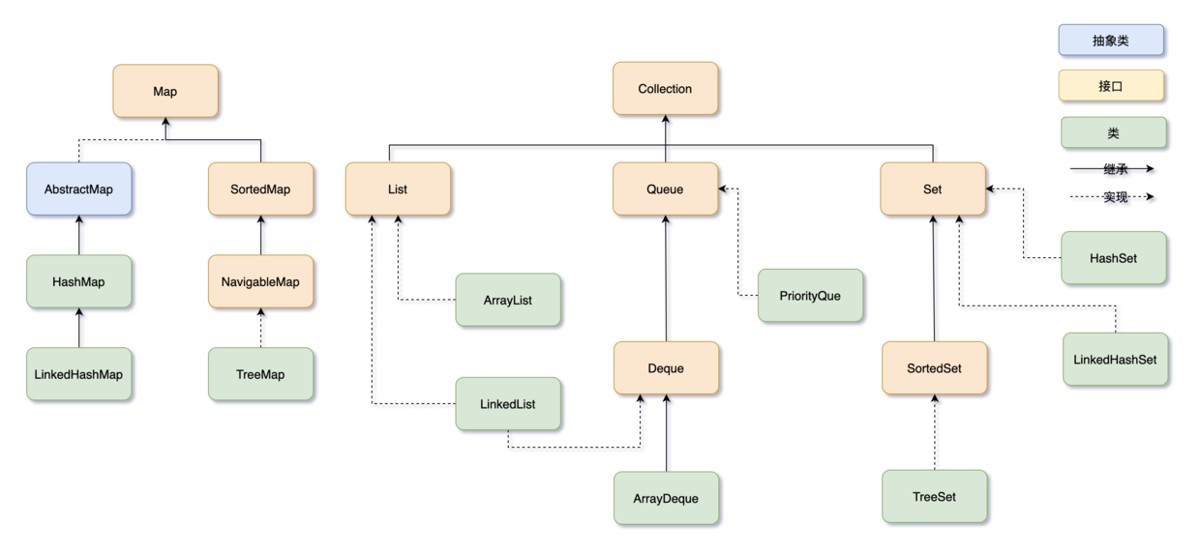
集合框架的整体结构
java 集合大体分为两条主线:
collection(单值集合)
│
├── list(有序,可重复)
│ ├── arraylist
│ ├── linkedlist
│ └── vector / stack
│
├── set(无序,不可重复)
│ ├── hashset
│ ├── linkedhashset
│ └── treeset
│
└── queue(队列)
├── arraydeque
├── linkedlist
└── priorityqueue
map(键值对集合)
├── hashmap
├── linkedhashmap
└── treemaplist:有序可重复的集合
arraylist ( 动态数组)
arraylist<string> list = new arraylist<>();
list.add("1");
list.add("2");
list.add("3");
- 底层是 动态数组;
- 支持随机访问(时间复杂度 o(1));
- 中间插入、删除代价高(涉及数组移动);
- 自动扩容(通常 1.5 倍)。
import java.util.arraylist;
import java.util.collections;
public class main {
public static void main(string[] args) {
int n = 10;
// 初始化 arraylist,大小为 10,元素值都为 0
arraylist<integer> nums = new arraylist<>(collections.ncopies(n, 0));
// 输出:false
system.out.println(nums.isempty());
// 输出:10
system.out.println(nums.size());
// 在数组尾部插入一个元素 20
nums.add(20);
// 输出:11
system.out.println(nums.size());
// 得到数组最后一个元素
// 输出:20
system.out.println(nums.get(nums.size() - 1));
// 删除数组的最后一个元素
nums.remove(nums.size() - 1);
// 输出:10
system.out.println(nums.size());
// 可以通过索引直接取值或修改
nums.set(0, 11);
// 输出:11
system.out.println(nums.get(0));
// 在索引 3 处插入一个元素 99
nums.add(3, 99);
// 删除索引 2 处的元素
nums.remove(2);
// 交换 nums[0] 和 nums[1]
collections.swap(nums, 0, 1);
// 遍历数组
// 输出:0 11 99 0 0 0 0 0 0 0
for(int num : nums) {
system.out.print(num + " ");
}
system.out.println();
}
}适用于 查找频繁、插入较少 的场景。
linkedlist ( 双向链表)
linkedlist<string> list = new linkedlist<>();
list.add("1");
list.add("2");
list.add("3");
特征:
- 底层是 双向链表;
- 不支持随机访问(时间复杂度 o(n));
- 任意位置插入、删除高效;
- 每个节点多存前后指针,内存开销更大。
适用于 插入、删除频繁 的场景。
import java.util.arrays;
import java.util.linkedlist;
public class main {
public static void main(string[] args) {
// 初始化链表
linkedlist<integer> lst = new linkedlist<>(arrays.aslist(1, 2, 3, 4, 5));
// 检查链表是否为空,输出:false
system.out.println(lst.isempty());
// 获取链表的大小,输出:5
system.out.println(lst.size());
// 在链表头部插入元素 0
lst.addfirst(0);
// 在链表尾部插入元素 6
lst.addlast(6);
// 获取链表头部和尾部元素,输出:0 6
system.out.println(lst.getfirst() + " " + lst.getlast());
// 删除链表头部元素
lst.removefirst();
// 删除链表尾部元素
lst.removelast();
// 在链表中插入元素
// 移动到第三个位置
lst.add(2, 99);
// 删除链表中某个元素
lst.remove(1);
// 遍历链表
// 输出:1 99 3 4 5
for(int val : lst) {
system.out.print(val + " ");
}
system.out.println();
}
}vector & stack(历史遗留)
vector是线程安全的arraylist;- 每个方法都加了
synchronized,性能较低; - 已被
arraylist替代; stack继承自vector,实现 lifo(后进先出) 栈结构;- 推荐使用
arraydeque替代。
set:无序且元素唯一
hashset ( 基于 hashmap)
hashset<string> set = new hashset<>();
set.add("一");
set.add("二");
set.add("三");
- 底层由
hashmap实现; - 元素作为 key,value 为固定对象;
- 自动去重;
- 不保证顺序。
适用于 去重、快速查找。
import java.util.arrays;
import java.util.hashset;
public class main {
public static void main(string[] args) {
// 初始化哈希集合
hashset<integer> hashset = new hashset<>(arrays.aslist(1, 2, 3, 4));
// 检查哈希集合是否为空,输出:false
system.out.println(hashset.isempty());
// 获取哈希集合的大小,输出:4
system.out.println(hashset.size());
// 查找指定元素是否存在
// 输出:element 3 found.
if(hashset.contains(3)) {
system.out.println("element 3 found.");
} else {
system.out.println("element 3 not found.");
}
// 插入一个新的元素
hashset.add(5);
// 删除一个元素
hashset.remove(2);
// 输出:element 2 not found.
if(hashset.contains(2)) {
system.out.println("element 2 found.");
} else {
system.out.println("element 2 not found.");
}
// 遍历哈希集合
// 输出(顺序可能不同):
// 1
// 3
// 4
// 5
for(int element : hashset) {
system.out.println(element);
}
}
}linkedhashset (有序 hashset)
linkedhashset<string> set = new linkedhashset<>();
set.add("一");
set.add("二");
set.add("三");
- 继承
hashset; - 底层由
linkedhashmap实现; - 保持插入顺序;
- 查找性能与
hashset相近。
适用于 既想去重又保留插入顺序 的场景。
treeset ( 有序去重集合)
treeset<string> set = new treeset<>();
set.add("一");
set.add("二");
set.add("三");
- 基于 红黑树 实现;
- 元素自动排序;
- 不允许
null; - 可自定义排序规则(
comparator)。
适用于 需要自动排序 的场景。
queue:队列
arraydeque ( 高效双端队列)
arraydeque<string> deque = new arraydeque<>();
deque.add("一");
deque.add("二");
deque.add("三");
- 基于循环数组;
- 可在两端插入/删除;
- 性能优于
linkedlist; - 替代
stack和queue。
linkedlist (可作队列使用)
linkedlist<string> queue = new linkedlist<>();
queue.offer("一成");
queue.poll();
- 同时实现了
list和deque; - 适合频繁插入删除;
- 支持队首、队尾操作;
- 内存占用高于
arraydeque。
priorityqueue — 优先级队列
priorityqueue<student> queue = new priorityqueue<>(new studentcomparator());
- 底层是 堆结构;
- 出队顺序由优先级决定;
- 元素需实现
comparable或传入comparator。
适用于 任务调度、最小/最大堆 场景。
import java.util.queue;
import java.util.linkedlist;
public class main {
public static void main(string[] args) {
// 初始化一个空的整型队列 q
queue<integer> q = new linkedlist<>();
// 在队尾添加元素
q.offer(10);
q.offer(20);
q.offer(30);
// 检查队列是否为空,输出:false
system.out.println(q.isempty());
// 获取队列的大小,输出:3
system.out.println(q.size());
// 获取队列的队头元素
// 输出:10
system.out.println(q.peek());
// 删除队头元素
q.poll();
// 输出新的队头元素:20
system.out.println(q.peek());
}
}map:键值对集合
hashmap (哈希表实现)
hashmap<string, string> map = new hashmap<>();
map.put("一成", "yicheng");
map.put("在成长", "zaichengzhang");
- 键唯一,值可重复;
- 查找/插入效率高;
- 默认容量 16,负载因子 0.75;
- 可存
null键与null值; - 无序。
import java.util.hashmap;
import java.util.map;
public class main {
public static void main(string[] args) {
// 初始化哈希表
hashmap<integer, string> hashmap = new hashmap<>();
hashmap.put(1, "one");
hashmap.put(2, "two");
hashmap.put(3, "three");
// 检查哈希表是否为空,输出:false
system.out.println(hashmap.isempty());
// 获取哈希表的大小,输出:3
system.out.println(hashmap.size());
// 查找指定键值是否存在
// 输出:key 2 -> two
if(hashmap.containskey(2)) {
system.out.println("key 2 -> " + hashmap.get(2));
} else {
system.out.println("key 2 not found.");
}
// 获取指定键对应的值,若不存在会返回 null
// 输出:null
system.out.println(hashmap.get(4));
// 获取指定键对应的值,若不存在则返回默认值
// 输出:defaultval
system.out.println(hashmap.getordefault(4, "defaultval"));
// 插入一个新的键值对
hashmap.put(4, "four");
// 获取新插入的值,输出:four
system.out.println(hashmap.get(4));
// 删除键值对
hashmap.remove(3);
// 检查删除后键 3 是否存在
// 输出:key 3 not found.
if(hashmap.containskey(3)) {
system.out.println("key 3 -> " + hashmap.get(3));
} else {
system.out.println("key 3 not found.");
}
// 遍历哈希表
// 输出(顺序可能不同):
// 1 -> one
// 2 -> two
// 4 -> four
for(map.entry<integer, string> pair : hashmap.entryset()) {
system.out.println(pair.getkey() + " -> " + pair.getvalue());
}
}
}linkedhashmap (有序 hashmap)
linkedhashmap<string, string> linkedmap = new linkedhashmap<>();
linkedmap.put("一成", "yicheng");
linkedmap.put("在成长", "zaichengzhang");
- 保留插入顺序;
- 可设置访问顺序;
- 常用于实现 lru 缓存。
treemap ( 红黑树实现)
treemap<string, string> treemap = new treemap<>();
treemap.put("a", "apple");
treemap.put("b", "banana");
treemap.put("c", "cat");
- 键有序;
- 基于红黑树;
- 查找、插入、删除为 o(log n)。
适用于 需要有序 map 的场景。
| 需求 | 推荐集合 | 说明 |
|---|---|---|
| 有序且可重复 | arraylist | 动态数组,随机访问快 |
| 插入删除多 | linkedlist | 链表结构,插入删除快 |
| 去重但无序 | hashset | 由 hashmap 实现 |
| 去重且有序 | linkedhashset | 保留插入顺序 |
| 自动排序 | treeset / treemap | 基于红黑树 |
| 双端队列 | arraydeque | 替代 stack/queue |
| 按优先级取出 | priorityqueue | 堆结构 |
| 键值映射 | hashmap | 最常用的 map |
| 有序 map | linkedhashmap / treemap | 插入或自然顺序 |
java 集合框架
│
├── collection
│ ├── list → arraylist / linkedlist / vector / stack
│ ├── set → hashset / linkedhashset / treeset
│ └── queue → arraydeque / linkedlist / priorityqueue
│
└── map
├── hashmap
├── linkedhashmap
└── treemap到此这篇关于java集合(含list、map、set和queue)超详细讲解的文章就介绍到这了,更多相关java list map set queue内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论