mysql 中的在线ddl(online ddl)功能是一种强大的工具,可以在不中断表或数据库的情况下进行数据定义语言(ddl)操作。通过在线ddl,使得在对表进行结构变更时,仍然能够进行读写操作,避免了整个表的锁定和阻塞。
一、online ddl的发展历史
mysql online ddl 功能从 5.6 版本开始正式引入,发展到现在的 8.0 版本,经历了多次的调整和完善。本文主要就 online ddl 的发展过程,以及各版本的区别进行总结。其实早在 mysql 5.5 版本中就加入了 inplace ddl 方式,但是因为实现的问题,依然会阻塞 insert、update、delete 操作,这也是 mysql 早期版本长期被吐槽的原因之一。
在 mysql 5.6 中,官方开始支持更多的 alter table 类型操作来避免数据拷贝,同时支持了在线上 ddl 的过程中不阻塞 dml 操作,真正意义上的实现了 online ddl。然而并不是所有的 ddl 操作都支持在线操作,后面会附上 mysql 官方文档对于 ddl 操作的总结。
到了 mysql 5.7,在 5.6 的基础上又增加了一些新的特性,比如:增加了重命名索引支持,支持了数值类型长度的增大和减小,支持了 varchar 类型的在线增大等。但是基本的实现逻辑和限制条件相比 5.6 并没有大的变化。
mysql 8.0 对 ddl 的实现重新进行了设计,其中一个最大的改进是 ddl 操作支持了原子特性。另外,online ddl 的 algorithm 参数增加了一个新的选项:instant,只需修改数据字典中的元数据,无需拷贝数据也无需重建表,同样也无需加排他 mdl 锁,原表数据也不受影响。整个 ddl 过程几乎是瞬间完成的,也不会阻塞 dml。
二、online ddl的算法
了解 online ddl 先了解一下之前 ddl 的 2 种算法 copy 和 inplace。
copy算法
- 按照原表定义创建一个新的临时表
- 对原表加写锁(禁止 dml,允许 select)
- 步骤 1)建立的临时表执行 ddl
- 将原表中的数据 copy 到临时表
- 释放原表的写锁
- 将原表删除,并将临时表重命名为原表
可见,采用 copy 方式期间需要锁表,禁止 dml,因此是非 online 的。比如:删除主键、修改列类型、修改字符集,这些操作会导致行记录格式发生变化(无法通过全量 + 增量实现 online)。
inplace算法
在原表上进行更改,不需要生成临时表,不需要进行数据 copy 的过程。根据是否变更行记录格式,分为两类:
- rebuild:需要重建表(重新组织聚簇索引)。比如 optimize table、添加索引、添加/删除列、修改列 null/not null 属性等;
- no-rebuild:不需要重建表,只需要修改表的元数据,比如删除索引、修改列名、修改列默认值、修改列自增值等。
对于 rebuild 方式实现 online 是通过缓存 ddl 期间的 dml,待 ddl 完成之后,将 dml 应用到表上来实现的。
说明:
- 在 copy 数据到新表期间,在原表上是加的 mdl 读锁(允许 dml,禁止 ddl)
- 在应用增量期间对原表加 mdl 写锁(禁止 dml 和 ddl)
- 根据表a重建出来的数据是放在 tmp_file 里的,这个临时文件是 innodb 在内部创建出来的,整个 ddl 过程都在 innodb 内部完成。对于 server 层来说,没有把数据挪动到临时表,是一个原地操作,这就是“inplace”名称的来源。
mysql中,表级别的锁有2种
一种是我们通常说的表锁,由innodb引擎实现,如lock tables …
read/write,表锁影响较大,不常用。另一种表级别的锁是mdl( metadata lock
),由server层实现,mdl我们不显式使用,是在访问一个表时由数据库自动加的,对表记录增删改查时,加mdl读锁;对表结构进行变更时,加mdl写锁。mdl锁,读读不互斥,读写、写写互斥。
哪些常用操作“锁表”
创建二级索引(二级索引是指除主键索引之外的索引)、删除索引、重命名索引、改变索引类型——不“锁表”。
添加字段、删除字段、重命名字段、调整字段顺序、设置字段默认值、删除字段默认值、修改auto-increment值、调整字段允许null、调整字段不允许null
—— 不“锁表”。
扩展varchar字段大小——不“锁表”。
更改字段数据类型,如varchar改成text——“锁表”
三、online ddl过程中的锁
默认情况下,mysql就是支持online的ddl操作的,在online的ddl语句执行的过程中,mysql会尽量少使用锁的限制,我们不需要特殊的操作来启用它。
mysql在选择的时候,尽量少使用锁,但是不排除它会选择使用锁。而如果我担心它选择了锁而导致我们的表不能读也不能写,显然这不是我们想要的结果,我们希望:如果选择了锁就不要执行,直接退出执行;如果没有选择锁就执行。想要达到我们希望的这个效果,该怎么做呢?
可以在执行我们的online ddl语句的时候,使用algorithm和lock关键字,这两个关键字在我们的ddl语句的最后面,用逗号隔开即可。示例如下:
alter table tbl_name add column col_name col_type, algorithm=inplace, lock=none;
algorithm的选项
- inplace:替换:直接在原表上面执行ddl的操作。
- copy:复制:使用一种临时表的方式,克隆出一个临时表,在临时表上执行ddl,然后再把数据导入到临时表中,在重命名等。这期间需要多出一倍的磁盘空间来支撑这样的 操作。执行期间,表不允许dml的操作。
- default:默认方式,有mysql自己选择,优先使用inplace的方式。
lock的选项
- share:共享锁,执行ddl的表可以读,但是不可以写。
- none:没有任何限制,执行ddl的表可读可写。
- exclusive:排它锁,执行ddl的表不可以读,也不可以写。
- default:默认值,也就是在ddl语句中不指定lock子句的时候使用的默认值。如果指定lock的值为default,那就是交给mysql子句去觉得锁还是不锁表。不建议使用,如果你确定你的ddl语句不会锁表,你可以不指定lock或者指定它的值为default,否则建议指定它的锁类型。
执行ddl操作时,algorithm选项可以不指定,这时候mysql按照instant、inplace、copy的顺序自动选择合适的模式。也可以指定algorithm=default,也是同样的效果。如果指定了algorithm选项,但不支持的话,会直接报错。
注意:
在执行onlineddl之前,要在非业务高峰期去执行,并要确认待执行的表上面没有未提交的事务、锁等信息。可以通过如下的sql语句查看是否有事务和锁等信息。
select * from information_schema.innodb_locks; select * from information_schema.innodb_trx; select * from information_schema.innodb_lock_waits; select * from information_schema.processlist;
四、理解ddl操作的需求和挑战
ddl操作涉及对数据库表结构的修改,例如添加/删除列、修改列定义、添加/删除索引等。在以往的版本中,执行这些ddl操作时需要锁定整个表,对数据库的可用性产生了负面影响。因此,实现在线ddl成为了提高系统灵活性和性能的重要需求。
五、mysql 5.7的在线ddl功能特点
mysql 5.7通过innodb存储引擎实现了在线ddl功能的改进。以下是该功能的主要特点:
- 支持添加辅助索引:可以在运行中的表上添加辅助索引,而不会对整个表进行锁定。
- 支持修改列定义:可以在线修改列的数据类型、长度等定义。
- 支持修改字符集和排序规则:可以在线修改表的字符集和排序规则设置。
- 支持重命名列:可以在不影响正在进行的读写操作的情况下,对表中的列进行重命名。
六、实现原理和优化
在线ddl功能的实现涉及以下关键步骤和优化:
- 1 创建临时表:通过创建临时表来存储将要进行的ddl操作所需的新结构。这样,旧表仍然可用于读写操作。
- 2 数据复制和同步:将旧表中的数据逐步复制到临时表中,并保持旧表数据与临时表数据的同步。这一过程确保了数据在ddl操作期间的完整性和一致性。
- 3 变更捕获和重放:通过使用日志和重做日志等机制,捕获在执行ddl操作期间发生的数据变更,并将其重放到临时表中。这确保了ddl操作完成后数据的一致性。
- 4 最终切换:当ddl操作完成时,数据库引擎将在适当的时机切换到临时表,使其成为新的表结构,并且对新表进行后续的读写操作。
七、使用限制和注意事项
尽管mysql 5.7的在线ddl功能提供了一种近似在线的体验,但仍然有一些限制和注意事项:
- 并非所有ddl操作都支持在线执行,某些操作仍然需要锁定整个表。
- 在进行ddl操作期间,可能会占用较多的系统资源,因此在高负载时应谨慎使用。
- 进行在线ddl操作时,需要对操作进行充分的评估和测试,以确保数据的完整性和一致性。
八、各版本支持的详细情况
本文数据全部来自 mysql 官方文档,此处进行一个集中的整理和总结:
https://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl-operations.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html
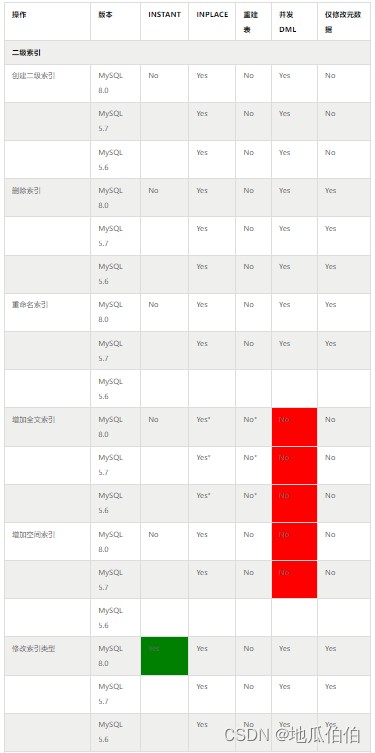
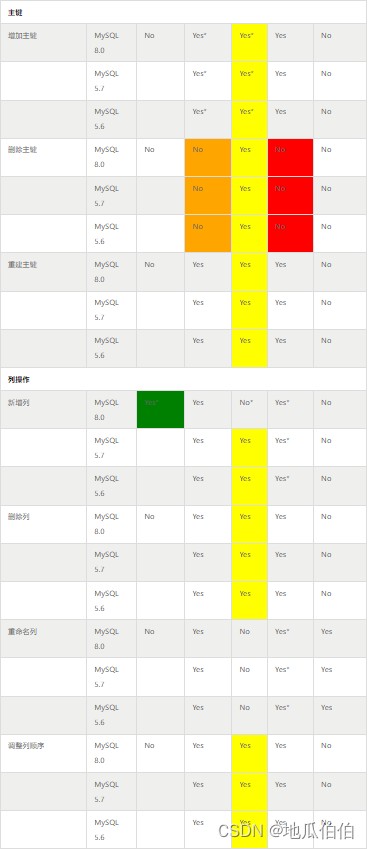
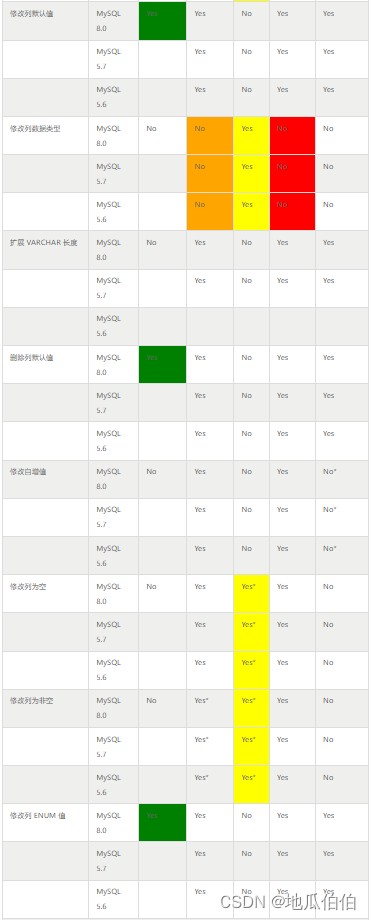
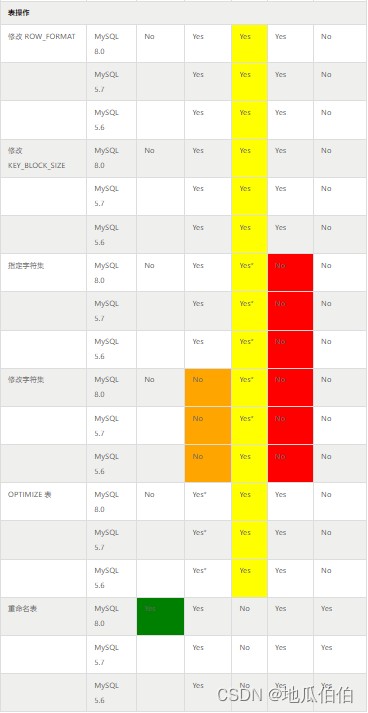
九、 ddl 的执行模式
结合上面的表格,对 mysql 当前 ddl 的执行模式总结如下:
1. instant ddl 是 mysql 8.0 引入的新功能,当前支持的范围较小,包括:
- 修改二级索引类型
- 新增列
- 修改列默认值
- 修改列 enum 值
- 重命名表
2. 在执行 ddl 操作时,mysql 内部对于 algorithm 的选择策略:
如果用户显式指定了 algorithm,那么使用用户指定的选项;
如果用户未指定,那么如果该操作支持 inplace 则优先选择 inplace,否则选择 copy;
当前不支持 inplace 的操作主要有:
- 删除主键
- 修改列数据类型
- 修改表字符集
3. 我们常说的 online ddl,其实是从 dml 操作的角度描述的,如果 ddl 操作不阻塞 dml 操作,那么这个 ddl 就是 online 的。当前非 online 的 ddl 其实已经比较少了,主要有:
- 新增全文索引
- 新增空间索引
- 删除主键
- 修改列数据类型
- 指定表字符集
- 修改表字符集
更多详细的示例请参考上面的官方文档的地址。
十、探讨几个问题
最后讨论几个非常容易混淆的问题:
- online ddl 不会锁表,可以随意的执行。
- 支持 inplace 算法的 ddl 一定是 online 的。
- 对于支持 inplace 算法的 ddl,ddl 操作是原地修改数据,不需要额外的数据空间。
q1: online ddl 会不会锁表
online ddl 会不会锁表?要回答这个问题,首先要明确“锁表”的含义。很多 mysql 用户经常在表无法正常的进行 dml 时就觉得是锁表了,这种说法其实过于宽泛,实际上能够影响 dml 操作的锁至少包括以下几种(默认为 innodb 表):
mdl 锁
表锁
行锁
gap 锁
其中除了 mdl 锁是在 server 层加的之外,其它三种都是在 innodb 层加的。具体的加锁逻辑不在此进行展开,但是需要明确一点:所有的操作(不管是 ddl 还是 dml 还是查询语句)都需要先拿 server 层的 mdl 锁,然后再去拿 innodb 层的某个需要的锁。
一个 ddl 的基本过程是这样的:
- 首选,在开始进行 ddl 时,需要拿到对应表的 mdl x 锁,然后进行一系列的准备工作;
- 然后将 mdl x 锁降级为 mdl s 锁,进行真正的 ddl 操作;
- 最后再次将 mdl s 锁升级为 mdl x 锁,完成 ddl 操作,释放 mdl 锁;
所以在真正执行 ddl 操作期间,确实是不会“锁表”的,但是如果在第一阶段拿 mdl x 锁时无法正常获取,那就可能真的会“锁表了”。一个简单的例子如下:
# session 1 select sleep(500) from mytest.t1; # session 2 optimize table mytest.t1; # session 3 select * from mytest.t1;
session 1 模拟了一个慢查询,然后 session 2 开始进行 ddl 操作,无法拿到 mdl x 锁,处于等到中。此时 session 3 需要执行一个查询,发现无法执行。实际上,在 session 1 结束前,表 t1 的所有操作都无法进行了,也可以说表 t1 “锁表”了。mysql 5.7/8.0 可以在开启 performance_schema 的情况下直接查询 metadata_locks 表。阿里云 rds 5.6 版本新增了 i_s.mdl_info 表,提供 mdl 的查询。
mysql [performance_schema]> select * from metadata_locks where object_name = 't1'; +-------------+---------------+-------------+-------------+-----------------------+----------------------+---------------+-------------+-------------------+-----------------+----------------+ | object_type | object_schema | object_name | column_name | object_instance_begin | lock_type | lock_duration | lock_status | source | owner_thread_id | owner_event_id | +-------------+---------------+-------------+-------------+-----------------------+----------------------+---------------+-------------+-------------------+-----------------+----------------+ | table | mytest | t1 | null | 140730442220576 | shared_read | transaction | granted | sql_parse.cc:5916 | 1083 | 24 | | table | mytest | t1 | null | 140730576178368 | shared_no_read_write | transaction | pending | sql_parse.cc:5916 | 1091 | 3 | | table | mytest | t1 | null | 140730374843168 | shared_read | transaction | pending | sql_parse.cc:5916 | 1092 | 3 | +-------------+---------------+-------------+-------------+-----------------------+----------------------+---------------+-------------+-------------------+-----------------+----------------+ 3 rows in set (0.00 sec)
明确了上面的概念之后,再回到我们的问题,online ddl 是不是不锁表?如果非要回答,那么只能说,online ddl 并不是绝对安全,更不是可以随意的执行。线上操作还是需要在业务低峰期谨慎操作。
q2: 支持 inplace 算法的 ddl 一定是 online 的
从概念上来说,inplace 和 online 是两个不同维度的事情。copy 和 inplace 指的是 ddl 内部的执行逻辑,可以简单的理解成:copy 是在 server 层的操作,inplace 是在 innodb 层的操作。而用户更加关心 online 与否,通常只与一个问题有关:是否允许并发 dml。
两个基本结论:
- copy 算法执行的 ddl 肯定不是 online 的;
- inplace 算法执行的 ddl 不一定是 online 的;
q3: inplace ddl 需不需要额外的数据空间
前面我们提到过,mysql 内部对于 ddl 的 algorithm 有两种选择:inplace 和 copy(8.0 新增了 instant,但是使用范围较小)。copy 算法理解起来相对简单一点:创建一张临时表,然后将原表的数据拷贝到临时表中,最后再用临时表替换原表。对于上面的步骤,由于需要将原表的数据拷贝到临时表中,所以肯定需要消耗额外的数据空间。
那么对于支持 inplace 算法的 ddl,是不是不需要额外的数据空间?
答案是:需要。其实之所以会问这个问题,还是因为对 inplace 本身的理解出现了偏差。简单来说:inplace 描述的是表,而不是数据文件。只要不创建临时表,那么都是 inplace 的。
实际上,很多 inplace ddl 都会重建表(会创建临时数据文件),所以都会需要额外的数据空间,例如:
- 增加主键
- 重建主键
- 新增列(8.0 支持 instant ddl,不需要)
- 删除列
- 调整列顺序
- 删除列默认值
- 增加列默认值
- 修改表的 row_format
- optimize 表
到此这篇关于mysql online ddl详解:从历史演进到原理及使用的文章就介绍到这了,更多相关mysql online ddl使用内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论