一. 什么是io流?
io流本质上是 java 中用于处理设备间数据传输的 api(不止限于文件,还包括网络、内存、键盘等),可以实现对文件数据的读写,区别于file类只能操作文件本身
- 输入流(input):数据从外部设备(如文件、网络)进入程序(内存);
- 输出流(output):数据从程序(内存)发送到外部设备。file 类仅能操作文件的 “元数据”(如创建、删除、判断存在性),而 io 流负责文件内容的读写,这是两者的核心区别。
二. io流的分类
1. 字节io流:
以字节(8bit)为单位读写数据,可处理所有类型文件(文本、图片、视频等)
输入:fileinputstream() 对应的缓冲流: bufferedinputstream()
输出:fileoutputstream() 对应的缓冲流: bufferedoutputstream()
2.字符io流:
以字符(16bit,java 中char)为单位读写数据,仅适合处理文本文件
输入:filereader() 对应的缓冲流: bufferedreader()
输出:filewriter() 对应的缓冲流: bufferedwriter()
注意:为什么要记对应的缓冲流?
缓冲流(bufferedxxx)通过内置8kb 缓冲区(字节缓冲流)或字符缓冲区(字符缓冲流),减少直接与磁盘的 io 次数(磁盘 io 效率远低于内存操作),从而提升性能。
- 例如:读取文件时,缓冲流会一次性从磁盘读取 8kb 数据到缓冲区,程序从缓冲区获取数据;写入时先攒满缓冲区再一次性写入磁盘。
使用规范
处理流需 “包裹” 节点流,关闭时只需关闭外层处理流(会自动关闭内层节点流):
// 示例:缓冲流包裹节点流
try (bufferedreader br = new bufferedreader(new filereader("test.txt"))) {
string line;
while ((line = br.readline()) != null) {
// 读取数据
}
} catch (ioexception e) {
e.printstacktrace();
}其他重要补充
流的继承关系:
- 所有字节输入流继承
inputstream,字节输出流继承outputstream; - 所有字符输入流继承
reader,字符输出流继承writer(这四个是抽象基类,不能直接实例化)。
- 所有字节输入流继承
编码问题:字符流涉及编码转换,
filereader/filewriter默认使用系统编码(可能导致乱码),建议用inputstreamreader/outputstreamwriter指定编码:// 指定utf-8编码读取文本 reader reader = new inputstreamreader(new fileinputstream("test.txt"), "utf-8");jdk7 + 的 try-with-resources:流实现了
autocloseable接口,可在 try 后自动关闭,无需手动调用close(),推荐优先使用(如上述缓冲流示例)。
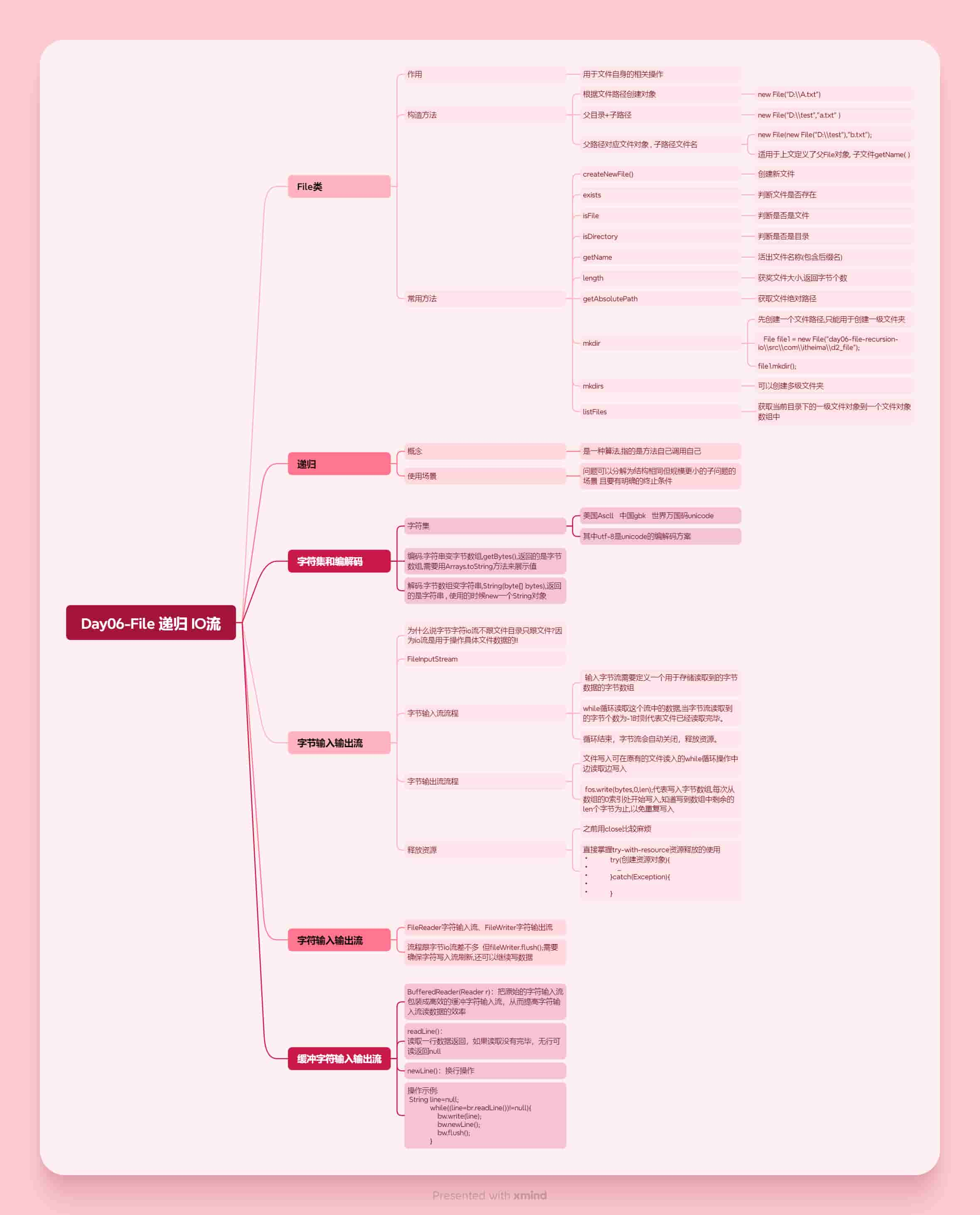
思维导图
练习一: 统计单一文件目录大小
package com.itheima.homework;
import java.io.file;
/**
* @author administrator
**需求:**
假设在`d:\itheima\`目录下有若干个文件**(只有文件没有目录)**,请编写程序统计`d:\itheima`目录的大小。
**提示:**
1. 如果没有`d:\itheima`目录,就在任意盘下创建一个`itheima`目录
2. 统计目录的大小就是统计目录中所有文件的大小之和
*/
public class work1 {
public static void main(string[] args) {
file file = new file("c:\\users\\administrator\\idea\\java-upgrade\\day06-file-recursion-io\\src\\com\\itheima\\d4_io\\d1_byteio");
file[] files = file.listfiles();
long length = 0;
for (file file1 : files) {
length+=file1.length();
}
system.out.println("总大小为"+length);
}
}练习2:统计目录若干文件大小
package com.itheima.homework;
import java.io.file;
/**
* @author administrator
**需求:
假设在`d:\itheima\`目录下有若干个文件和目录,请编写程序统计`d:\itheima`目录的大小。
**提示:**统计目录的大小就是统计目录(及其子目录)中所有文件的大小之和
*/
public class work2 {
public static void main(string[] args) {
file file = new file("day06-file-recursion-io");
system.out.println("总大小为"+filesizecount(file));
}
public static long filesizecount(file dir){
file[] files = dir.listfiles();
long length = 0;
for (file file1 : files) {
if (file1.isfile()) {
long len = file1.length();
system.out.println(file1.getname()+"-->"+len);
length+=file1.length();
}else{
// return filesizecount(file1); 不能return直接否定了外层循环
// filesizecount(file1);
//todo 没有累加非同级目录的文件大小,结果为909,只计算了1级目录的文件大小
length +=filesizecount(file1);
//递归就应该累加文件大小,就跟阶乘类似
system.out.println("子级目录长度:"+ length);
}
}
return length;
}
}练习3: 复制单个文件到目录中
package com.itheima.homework;
import java.io.*;
/**
* @author administrator
* **需求:**
假设在`d:\itheima\`目录下有若干个文件**(只有文件没有目录)**,请编写程序将`d:\itheima`目录中的**一个文件**复制到当前模块下的`itheima`目录中,文件名不变。
* **要求:**不使用commons-io框架
*/
public class work3 {
public static void main(string[] args) throws ioexception {
copyfile();
}
public static void copyfile() {
//复制文件的思路:字节流符合视频\图片\音频\文本,更普遍使用
try(
fileinputstream fis = new fileinputstream(new file("day06-file-recursion-io\\src\\com\\itheima\\d1_file\\demo1.java"));
fileoutputstream fos = new fileoutputstream("day06-file-recursion-io\\src\\com\\itheima\\homework\\demo1.java");
) {
byte[] bytes = new byte[1024];
int lenth = 0;
while((lenth=fis.read(bytes))!=-1){
fos.write(bytes,0,lenth);
}
} catch (ioexception e) {
throw new runtimeexception(e);
}
}
}练习4:将某一目录下所有文件复制到别的目录下
package com.itheima.homework;
import java.io.*;
/**
* @author administrator
* 假设在`d:\itheima\`目录下有若干个文件**(只有文件没有目录)**,请编写程序将`d:\itheima`目录中的**所有文件**复制到当前模块下的`itheima`目录中。
*/
/*todo error: fileinputstream 只能用于读取文件,不能读取目录
* 遍历目录中的每个文件
为每个源文件创建独立的 fileinputstream
为目标文件创建 fileoutputstream
*
* 输出目录拒绝访问的原因是:
fileoutputstream 不能直接写入目录
fileoutputstream 只能用于创建或写入文件,不能直接写入目录
代码中 new fileoutputstream(outputfile) 试图将数据写入目录 work4,这是不允许的
目标路径应该是文件而不是目录
每个源文件都需要对应一个目标文件
当前代码试图将所有文件内容都写入同一个目录路径*
*使用 while((len = fis.read(bytes)) != -1) 循环读取
每次读取后立即写入目标文件
直到 read() 返回 -1(文件结束)才停止
这样就能完整复制整个文件内容,而不是只复制前1024字节。*/
public class work4 {
public static void main(string[] args) throws ioexception {
file inputfile = new file("day06-file-recursion-io\\src\\com\\itheima\\d4_io\\d1_byteio");
file outputfile = new file("day06-file-recursion-io\\src\\com\\itheima\\homework\\work4");
copyfiles(inputfile,outputfile);
}
public static void copyfiles(file dir,file outputfile) throws ioexception {
//创建字节输入输出流
//这里的都是目录
//读取输入流目录的子级
file[] files = dir.listfiles();
for (file file : files) {
//遍历父级目录下的文件是否是文件
if (file.isfile()) {
try ( fileinputstream fis = new fileinputstream(file);
//todo 此时字节输入流已经拿到了文件
fileoutputstream fos = new fileoutputstream(new file(outputfile, file.getname()));
//todo 为输出字节流的目标文件指定具体文件名,父目录+子文件名
){
byte[] bytes = new byte[1024];
int len = 0;
while ((len=fis.read(bytes))!=-1){
fos.write(bytes,0,len);
}
} catch (ioexception e) {
throw new runtimeexception(e);
}
}else{
copyfiles(file, new file(outputfile, file.getname()));
}
}
//读入和输出
//关闭流
}
}练习5:符缓冲流读取数据并封装对象
package com.itheima.homework;
import java.io.*;
import java.util.arraylist;
import java.util.arrays;
import java.util.list;
/**
* @author administrator
* - 使用字符缓冲流读取”students.txt”文件,将每行数据封装为一个student对象,并将student对象存储到一个集合
*
* - 遍历并打印集合的所有student信息
*/
public class work5 {
public static void main(string[] args) throws ioexception {
reader file = new filereader("day06-file-recursion-io\\student.txt");
bufferedreader br = new bufferedreader(file);
//读取行
string line = null;
list<student> studentarraylist = new arraylist<>();
while((line=br.readline())!=null){
string s = new string(line);
string[] split = s.split(",");
// system.out.println(arrays.tostring( split));
student student = new student(split[0], integer.parseint(split[1]));
studentarraylist.add(student);
/*//todo 而不是“每行都重复 3 次”,根本原因是:
//你把 new arraylist<>() 写在了 while 循环里
//→ 每读一行就 new 一个新的空集合 → 只装当前这一个 student → 打印完就弃用 → 下一行再 new 一个新的空集合……*/
}
br.close();
system.out.println(studentarraylist);
}
}总结
到此这篇关于如何使用io流实现文件数据的读写及文件复制的文章就介绍到这了,更多相关io流实现文件数据读写及文件复制内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论