milvus 核心概念
向量数据库
- 可以把 milvus 理解成一个专门处理“向量”这种特殊数据的数据库。传统数据库(如 mysql)擅长处理数字、文字这类结构化数据,并按精确条件查询(比如 where age > 18)。而向量数据库的核心是相似性搜索,它通过计算向量之间的“距离”或“相似度”,来找到最相近的结果。
- “向量”在这里,通常是由各种 ai 模型(如 bert、resnet)从文本、图片、音频等非结构化数据中提取出的特征表示。这些向量本身是一串数字,在高维空间中代表原始数据的意义。
核心概念
- 集合 (collection) :这是 milvus 中最顶层的概念,类似于关系型数据库中的“表”。一个 collection 用来存储具有相同结构的实体。
- 字段 (field):定义了 collection 的结构,类似于表中的“列”。milvus 支持多种数据类型,但对于向量搜索,最重要的就是 floatvector 类型的字段。
- 向量维度 (dimension):这是向量的一个关键属性。它定义了向量中数字的个数。例如,一个由 bert-base 模型生成的句子向量可能是 768 维,这就意味着它是一个包含 768 个浮点数的数组。在定义向量字段时,必须指定其维度。
- 索引 (index) :为了在亿级数据中快速搜索,milvus 不会进行暴力比对,而是为向量数据构建索引。不同的索引类型在构建速度、内存占用、查询速度和精度之间有不同的权衡,常见的索引类型有:
| 索引类型 | 说明 |
|---|---|
| flat | 暴力搜索,精度100%但速度慢,适合小数据集或验证结果 |
| ivf_flat | 先通过聚类将数据分桶(nlist 参数决定桶数),搜索时只查询最近的几个桶(nprobe 参数控制),大大提升速度 |
| hnsw | 基于图论的索引,适合高精度、低延迟的搜索场景,但内存消耗较高 |
- 度量类型(metric type):定义了计算向量之间距离或相似度的方式。常见的有:
| 度量类型 | 说明 |
|---|---|
| l2 (欧氏距离) | 距离越小,向量越相似。 |
| ip (内积) | 内积越大,向量越相似。 |
| cosine (余弦相似度) | 忽略向量大小,只比较方向,相似度值越接近 1 越相似。这在自然语言处理中非常常用 |
milvus 的基本工作流程
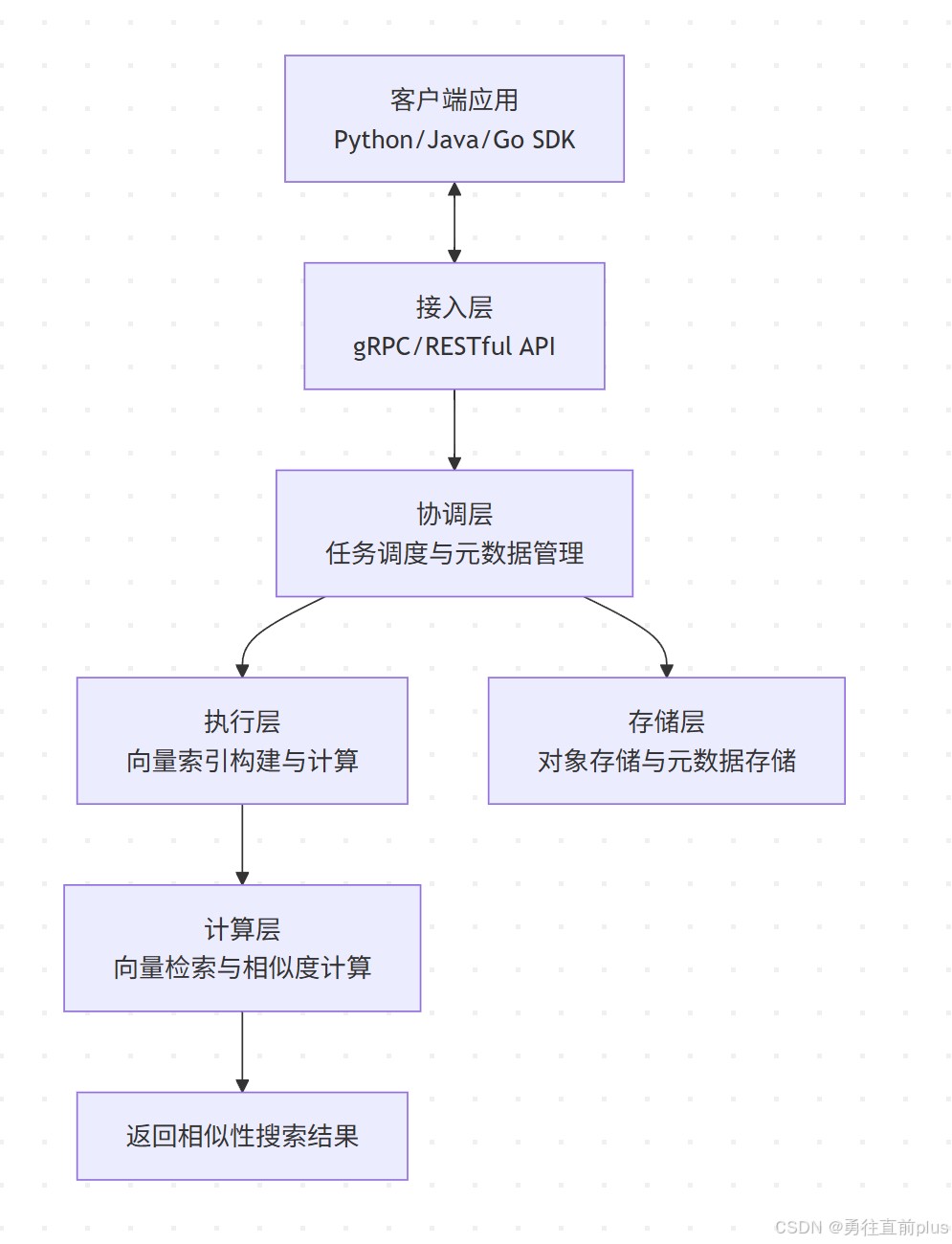
上面这个图是milvus的核心系统架构图,和mysql、pg等数据库的系统架构很像,其核心工作流程可以概括为以下几个步骤:
- 连接 milvus:你的应用程序通过 milvus 提供的 sdk(如 python 或 java sdk)连接到 milvus 服务。
- 创建集合:定义一个 collection,并指定它的字段结构(例如,一个主键字段 id ,一个向量字段 embedding和对应的原始数据字段,一般一个collection最少要包含这三个字段)。
- 插入数据:将你的数据(向量和相关的元数据,包括原始数据)插入到 collection 中。
- 创建索引:在向量字段上构建索引(例如 ivf_flat)。这一步至关重要,只有在构建索引后,才能进行高效的向量搜索。
- 加载集合:将 collection 从存储层加载到内存中,以便执行查询。
- 向量搜索:提供一个查询向量,让 milvus 在 collection 中搜索最相似的向量,并返回结果,值得注意的是,一般情况下返回的是最相似向量对应的原始数据或者自定义的元数据,而不是返回embedding
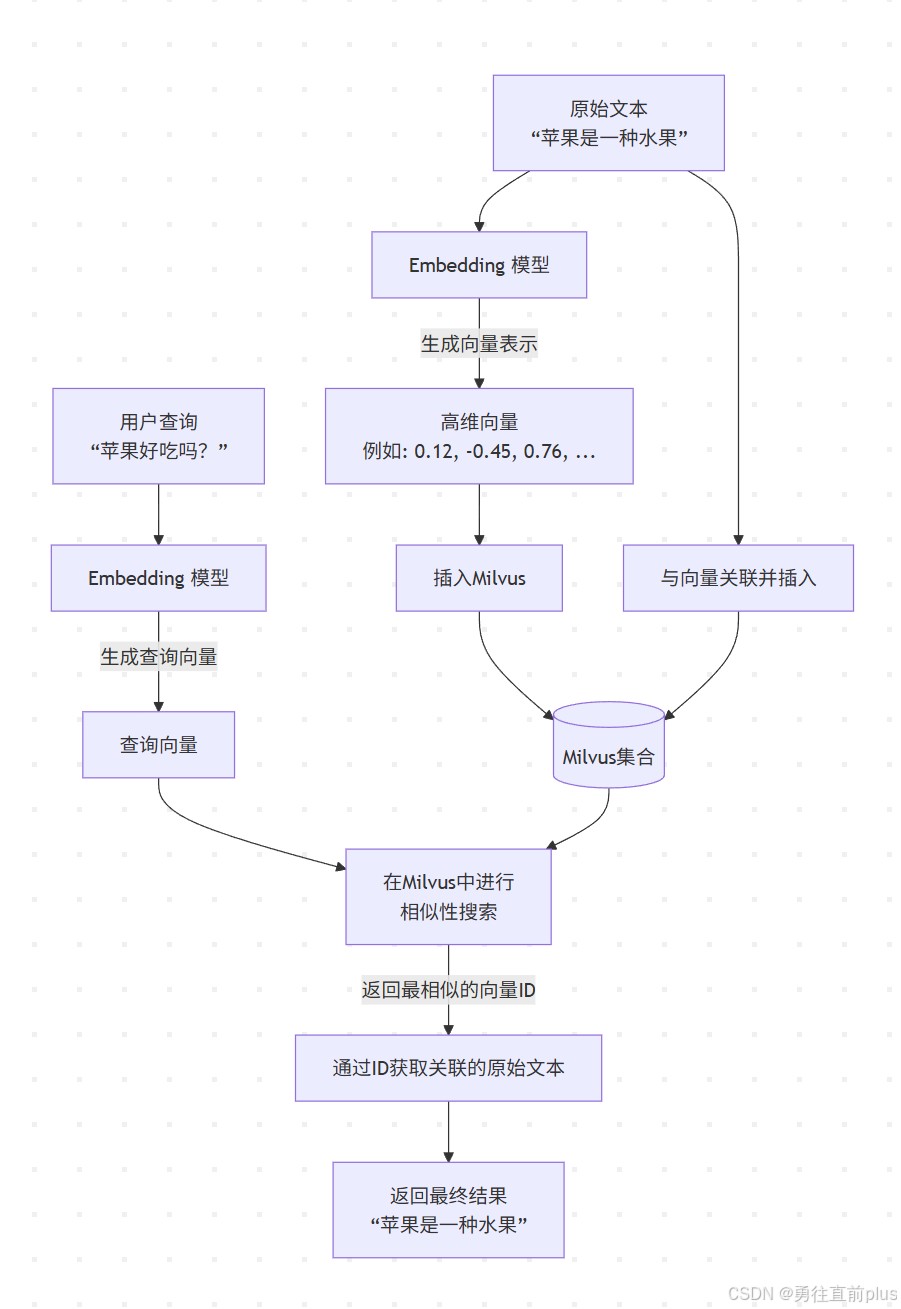
下面这个流程图是milvus 的核心工作流程图,很清晰地展示了 milvus 如何通过向量查找内容的工作过程
用 java 操作 milvus
可以总结为,在boot项目中将milvus客户端bean注入ioc容器,以便后续通过客户端对象操作milvus服务器,包括创建集合、插入数据、创建索引、搜索向量等。主要是核心代码片段,有boot项目经验的很容易掌握。
引入依赖
<dependency>
<groupid>io.milvus</groupid>
<artifactid>milvus-sdk-java</artifactid>
<version>2.5.11</version> <!-- 请查看github更新最新版本 -->
</dependency>springboot中注入milvus客户端bean
@configuration
public class milvusconfig {
@value("${milvus_uri}")
private string milvus_uri;
@bean
public milvusclientv2 milvusserviceclient() {
connectconfig connectconfig = connectconfig.builder()
.uri(milvus_uri)
.build();
return new milvusclientv2(connectconfig);
}
}创建集合
- 一般三个字段,主键字段,embedding字段,元数据(原始数据)字段
import io.milvus.v2.client.milvusclientv2;
import io.milvus.v2.client.connectconfig;
import io.milvus.v2.service.collection.request.createcollectionreq;
import io.milvus.v2.service.collection.request.addfieldreq;
import io.milvus.v2.common.datatype;
public class milvuscollectioncreator {
public static void main(string[] args) {
// 1. 配置并创建 milvus 客户端
connectconfig connectconfig = connectconfig.builder()
.uri("http://localhost:19530") // milvus 服务器地址
.token("username:password") // 若启用认证,请提供;否则可省略
.build();
milvusclientv2 client = new milvusclientv2(connectconfig);
// 2. 定义集合名称
string collectionname = "my_first_collection"; // 替换为你想要的集合名
// 3. 构建集合 schema (字段定义)
createcollectionreq.collectionschema schema = client.createschema(); // 创建空schema
// 3.1 添加主键字段 (通常是int64或varchar)
schema.addfield(addfieldreq.builder()
.fieldname("id")
.datatype(datatype.int64)
.isprimarykey(true) // 设为主键
.autoid(false) // 设置为false表示插入数据时需自行提供id
.build());
// 3.2 添加标量字段 (例如存储文本名称)
schema.addfield(addfieldreq.builder()
.fieldname("name")
.datatype(datatype.varchar)
.maxlength(255) // varchar类型必须指定最大长度
.build());
// 3.3 添加向量字段 (核心部分)
int vectordimension = 768; // 必须与你后续要插入的向量维度一致!
schema.addfield(addfieldreq.builder()
.fieldname("vector_embedding") // 字段名
.datatype(datatype.floatvector) // 数据类型为浮点向量
.dimension(vectordimension) // 必须指定向量维度
.build());
// 4. 构建创建集合的请求
createcollectionreq createcollectionreq = createcollectionreq.builder()
.collectionname(collectionname)
.collectionschema(schema) // 设置定义好的schema
// .shardsnum(1) // (可选) 设置分片数,默认为1
// .enabledynamicfield(true) // (可选) 是否启用动态字段以存储未定义的字段
.build();
// 5. 执行创建操作
client.createcollection(createcollectionreq);
system.out.println("集合 '" + collectionname + "' 创建成功!");
}
}插入数据
插入数据包含主键字段、向量数组、和对应的原始文本数组,并确保它们的顺序一致,这样每条向量就与它对应的文本通过相同的数组索引关联起来了
/**
* 插入单条数据到milvus集合
* @param id 记录的唯一id
* @param text 原始文本或其他标量数据
* @param vector 文本对应的向量(float列表)
* @return 插入结果信息
*/
public string insertsingledata(long id, string text, list<float> vector) {
try {
// 1. 构建一个 jsonobject 代表一条记录
jsonobject entity = new jsonobject();
entity.addproperty("id", id); // 主键字段 (需与集合schema定义匹配)
entity.addproperty("content", text); // 标量字段 (例如存储原始文本)
// 将向量列表转换为jsonarray并添加到实体中
entity.add("vector", gson.tojsontree(vector)); // 向量字段 (字段名需与schema匹配)
// 2. 将单条数据放入列表
list<jsonobject> datalist = collections.singletonlist(entity);
// 3. 构建插入请求
insertreq insertreq = insertreq.builder()
.collectionname(collection_name)
.data(datalist)
.build();
// 4. 执行插入
insertresp insertresp = milvusclientv2.insert(insertreq);
return "成功插入 " + insertresp.getinsertcnt() + " 条数据。";
} catch (exception e) {
throw new runtimeexception("插入数据失败: " + e.getmessage(), e);
}
}创建索引
import io.milvus.param.index.createindexparam;
import io.milvus.param.index.indextype;
import io.milvus.param.index.metrictype;
createindexparam createindexparam = createindexparam.newbuilder()
.withcollectionname("my_book_collection")
.withfieldname("embedding") // 在哪个向量字段上建索引
.withindextype(indextype.ivf_flat) // 选择索引类型
.withmetrictype(metrictype.cosine) // 选择度量类型
.withextraparam("{\"nlist\":1024}") // 索引参数,nlist是聚类中心数
.build();
milvusclient.createindex(createindexparam);
system.out.println("index created successfully!");检索并获取原始数据
public map<string, string> query(list<float> embedding) {
// key:原始文本,value:drug_code
map<string, string> res = new hashmap<>();
//设置查询参数
map<string, object> searchparamsmap = new hashmap<>();
searchparamsmap.put("nprobe", 10); // 设置搜索的桶数量,影响精度和性能
// 设置返回的field
list<string> returnfields = arrays.aslist("original_text", "drug_code");
floatvec floatvec = new floatvec(embedding);
searchreq searchreq = searchreq.builder()
.collectionname(drug_wes_collection_name)
.data(collections.singletonlist(floatvec))
.topk(tok_k)
.outputfields(returnfields)
.searchparams(searchparamsmap)
.build();
searchresp searchresp = milvusserviceclient.search(searchreq);
//获取查询向量检索出的数据
list<searchresp.searchresult> searchresult = searchresp.getsearchresults().get(0);
for (searchresp.searchresult sr : searchresult) {
map<string, object> entity = sr.getentity();
string originaltext = (string) entity.get("original_text");
string drugcode = (string) entity.get("drug_code");
res.put(originaltext,drugcode);
}
return res;
}工程建议
- 索引选择:如果你的数据量巨大(十亿级)且对查询速度要求极高,可以考虑 hnsw 索引。如果对内存敏感,可以考虑量化索引如 ivf_pq
- 参数调优:nprobe(对于 ivf 系列索引)和 ef(对于 hnsw 索引)等参数对搜索性能和精度有直接影响。通常需要在你的数据集上进行实验,找到平衡点
- 硬件加速:milvus 支持 gpu 加速索引构建和查询,如果你的环境有 gpu,可以显著提升性能
- 官方文档 https://milvus.io/docs
到此这篇关于milvus快速入门及用java操作milvus的全过程的文章就介绍到这了,更多相关java milvus操作内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论