1、前提条件
前提是需要安装kafka及能正常启动,正常启动后记录下kafka的ip及端口号,例如我的:127.0.0.1:9092。
由于用的kafka还是需要zookeeper的,因此之前也要安装启动好zookeeper,zookeeper的安装启动见这篇文章:
2、启动kafka
2.1 windows启动
1、到kafka安装目录下的bin目录下的windows下:
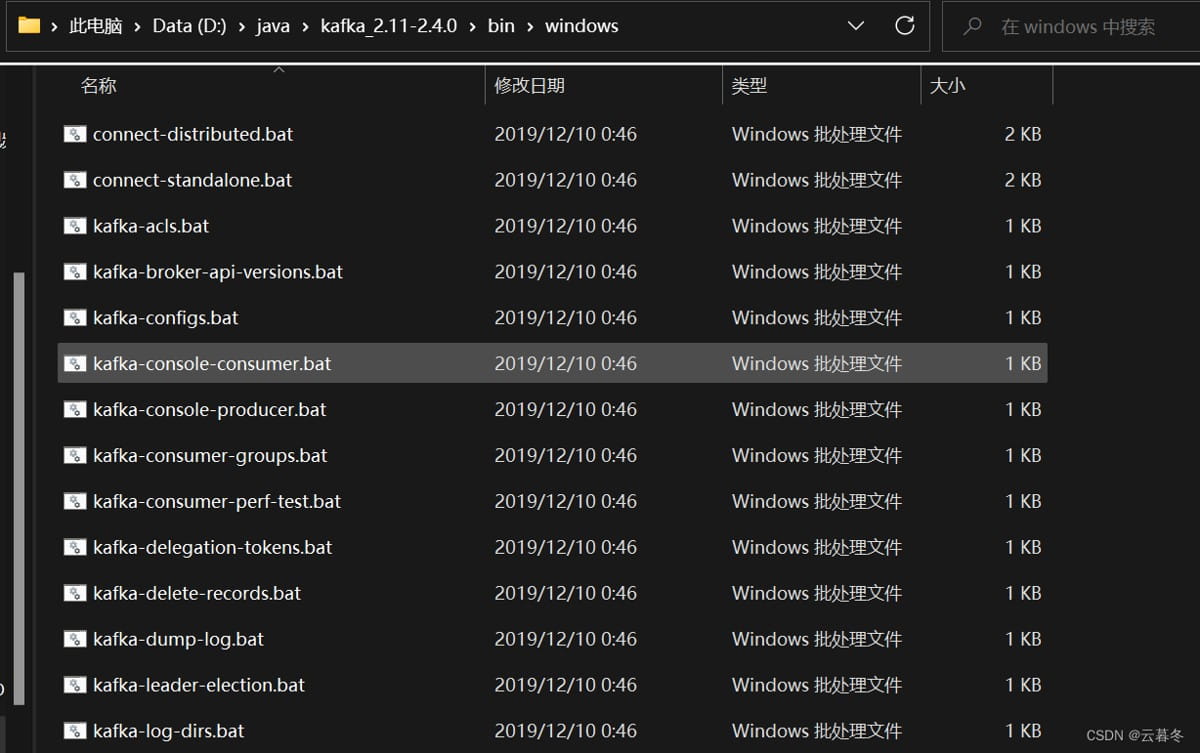
2、执行命令:kafka-server-start.bat -daemon d:\java\kafka_2.11-2.4.0\config\server.properties
2.2 linux启动
3、引入pom
这里由于我系统安装的是2.4.0版本的kafka,因此pom引入最好用相同版本的,避免出现其他问题。还有一点要注意的是,如果最新的spring boot引入这个版本zookeeper可能有问题,因此需要注意。我用的是2.3.7.release版本的spring boot。
<dependency>
<groupid>org.apache.kafka</groupid>
<artifactid>kafka-clients</artifactid>
<version>2.4.0</version>
</dependency>4、编写配置文件
这里一些相应的配置后续可以专门更新一篇文章,目前的目的是先跑起来体验一下。搭建起来。
spring:
application:
name: xuydkafka
kafka:
bootstrap-servers: 127.0.0.1:9092 #kafka地址
producer: # 生产者
retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.stringserializer
value-serializer: org.apache.kafka.common.serialization.stringserializer
consumer:
group-id: default-group
enable-auto-commit: false
auto-offset-reset: earliest # 从消息头开始poll()数据
key-deserializer: org.apache.kafka.common.serialization.stringdeserializer
value-deserializer: org.apache.kafka.common.serialization.stringdeserializer
max-poll-records: 500 # 一次poll最大的消息数量
listener:
# 当每一条记录被消费者监听器(listenerconsumer)处理之后提交
# record
# 当每一批poll()的数据被消费者监听器(listenerconsumer)处理之后提交
# batch
# 当每一批poll()的数据被消费者监听器(listenerconsumer)处理之后,距离上次提交的时间大于time时提交
# time
# 当每一批poll()的数据被消费者监听器(listenerconsumer)处理之后,被处理的record数量大于等于count时提交
# count
# time | count 有⼀个条件满⾜时提交
# count_time
# 当每⼀批poll()的数据被消费者监听器(listenerconsumer)处理之后, ⼿动调#⽤acknowledgment.acknowledge()后提交
# manual
# ⼿动调⽤acknowledgment.acknowledge()后⽴即提交,⼀般使⽤这种
# manual_immediate
ack-mode: manual_immediate
redis:
host: 127.0.0.1
server:
port: 90005、编写消息生产者代码
package com.xuyd.kafka.controller;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.kafka.core.kafkatemplate;
import org.springframework.web.bind.annotation.requestmapping;
import org.springframework.web.bind.annotation.restcontroller;
@restcontroller
@requestmapping("/msg")
public class kafkacontroller {
private final static string topic_name = "my-replicated-topic";
@autowired
private kafkatemplate<string, string> kafkatemplate;
@requestmapping("/send")
public string sendmessage(){
kafkatemplate.send(topic_name, 0, "key", "this is a message");
return "send success";
}
}6、编写消息消费者相关代码
需要注意的是,一般生产者和消费者不会在同一个项目。这里只是体验,所以临时这么处理。
package com.xuyd.kafka.consumer;
import org.apache.kafka.clients.consumer.consumerrecord;
import org.springframework.kafka.annotation.kafkalistener;
import org.springframework.kafka.support.acknowledgment;
import org.springframework.stereotype.component;
@component
public class myconsumer {
@kafkalistener(topics = "my-replicated-topic", groupid = "mygroup1")
public void listengroup(consumerrecord<string, string> record, acknowledgment ack) {
string value = record.value();
system.out.println(value);
system.out.println(record);
// 由于配置的提交方式是manual_immediate 因此这里需要手动提交代码
ack.acknowledge();
}
}7、启动并发送消息
这里启动时候可能会遇到各种问题,99%是因为springcloud或者springboot与kafka的版本不匹配造成的,大家先临时委曲求全一下,用我的版本跑起来再去完善吧~~
消息生产者发生消息。
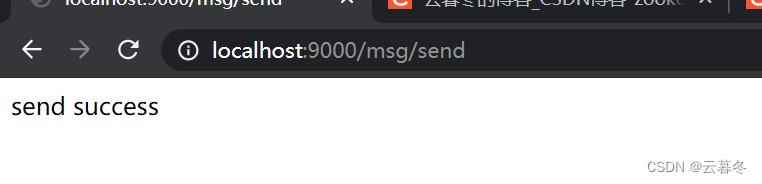
消费者收到消息打印:

到此这篇关于springboot集成kafka2.4.0的全过程的文章就介绍到这了,更多相关springboot集成kafka内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论