开篇:redis list就像超市的购物车
想象一下,当我们去超市购物时,推着一辆购物车,可以随意往里面添加商品(从头部或尾部放入),也可以按照放入的顺序取出商品(从头部或尾部取出)。redis的list数据结构就像这样一个购物车,它允许我们在两端高效地添加或移除元素,这种特性使得它成为实现队列、栈等数据结构的理想选择。
在实际应用中,redis list被广泛用于消息队列、最新消息排行、记录用户操作历史等场景。比如,社交平台可以用它来存储用户的最新动态,电商平台可以用它来实现订单处理队列。今天,我们就来深入探讨redis list的使用方法和内部实现原理。
以上流程图展示了redis list与购物车的类比关系,展示了可以从头部或尾部添加和取出元素的特性。
一、redis list的基本操作
理解了redis list的基本概念后,我们来看看它的具体操作命令。redis为list提供了丰富的操作接口,让我们能够灵活地使用这个数据结构。
redis list支持从两端插入和弹出元素,也支持按照索引访问元素。这些操作的时间复杂度大多为o(1),非常高效。
下面我们通过java代码示例来演示如何使用jedis客户端操作redis list。
1.1 基本操作示例
import redis.clients.jedis.jedis;
public class redislistdemo {
public static void main(string[] args) {
// 连接redis服务器
jedis jedis = new jedis("localhost", 6379);
// 从左侧插入元素
jedis.lpush("mylist", "item1", "item2", "item3");
// 从右侧插入元素
jedis.rpush("mylist", "item4", "item5");
// 获取列表长度
system.out.println("列表长度: " + jedis.llen("mylist"));
// 获取指定范围的元素
system.out.println("列表元素: " + jedis.lrange("mylist", 0, -1));
// 从左侧弹出元素
system.out.println("左侧弹出: " + jedis.lpop("mylist"));
// 从右侧弹出元素
system.out.println("右侧弹出: " + jedis.rpop("mylist"));
// 关闭连接
jedis.close();
}
}
上述代码展示了redis list的基本操作:使用lpush从左侧插入元素,rpush从右侧插入元素,llen获取列表长度,lrange获取指定范围的元素,lpop和rpop分别从左右两侧弹出元素。
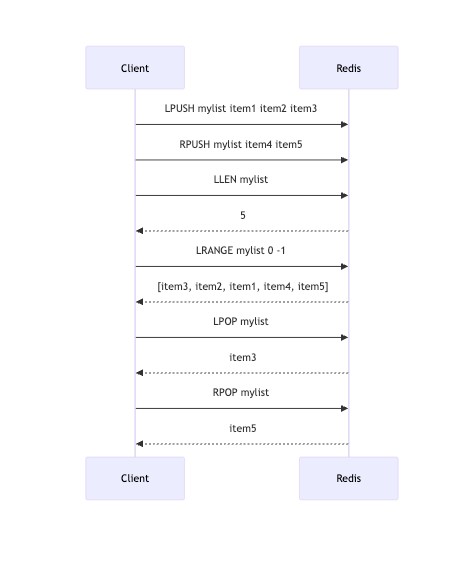
以上序列图展示了客户端与redis服务器交互的过程,清晰地展示了list操作的执行顺序和返回结果。
1.2 高级操作示例
除了基本操作外,redis list还提供了一些高级功能,如阻塞式弹出、元素修剪等。这些功能在实际开发中非常有用。
// 阻塞式弹出:如果列表为空,会阻塞等待指定时间
string item = jedis.blpop(10, "mylist");
system.out.println("阻塞式弹出: " + item);
// 修剪列表,只保留指定范围内的元素
jedis.ltrim("mylist", 0, 2);
// 在指定元素前或后插入新元素
jedis.linsert("mylist", listposition.before, "item2", "new_item");
// 移除指定数量的匹配元素
jedis.lrem("mylist", 1, "item1");
这些高级操作使得redis list能够应对更复杂的应用场景。比如blpop可以实现简单的消息队列,ltrim可以限制列表长度避免内存占用过大。
**经验分享:**
- 在实际项目中,我经常使用redis list来实现简单的消息队列。
- 相比专业的消息队列系统,redis list实现简单、性能高,适合对可靠性要求不是特别高的场景。
- 建议大家在小型项目或原型开发中可以尝试这种方案。
二、redis list的内部实现原理
了解了redis list的使用方法后,我们自然会好奇它是如何实现这些高效操作的。redis list的内部实现经历了从ziplist到linkedlist再到quicklist的演变过程,每种实现都有其适用场景和优缺点。
redis为了在内存使用和操作效率之间取得平衡,根据列表元素的数量和大小动态选择不同的底层实现。这种智能的切换对使用者是透明的,但了解其原理有助于我们更好地使用redis list。
2.1 ziplist实现
当列表元素较少且较小时,redis使用ziplist(压缩列表)作为底层实现。ziplist是一块连续的内存空间,可以高效利用内存,但修改操作效率较低。
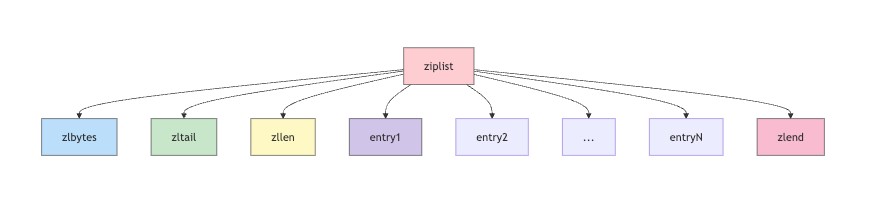
以上流程图展示了ziplist的结构:zlbytes表示总字节数,zltail是最后一个entry的偏移量,zllen是entry数量,后面跟着各个entry,最后是zlend结束标志。
ziplist的entry结构如下:
+--------+--------+--------+--------+ | prevlen | encoding | content | +--------+--------+--------+--------+
prevlen存储前一个entry的长度,encoding表示当前entry的编码方式,content是实际存储的数据。这种紧凑的结构节省了内存,但插入和删除操作可能需要重新分配内存和移动数据。
2.2 linkedlist实现
当列表元素较多或较大时,redis会切换到linkedlist(双向链表)实现。这种实现修改效率高,但内存使用不如ziplist紧凑。
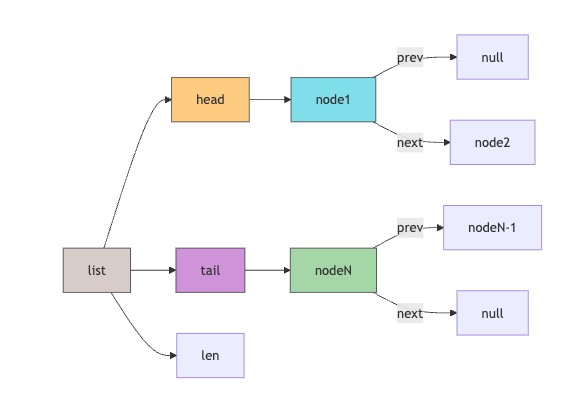
以上流程图展示了linkedlist的结构:list包含头指针、尾指针和长度计数,每个node包含指向前后节点的指针和实际存储的值。
2.3 quicklist实现
redis 3.2之后引入了quicklist作为list的默认实现,它结合了ziplist和linkedlist的优点,是一个由ziplist组成的双向链表。
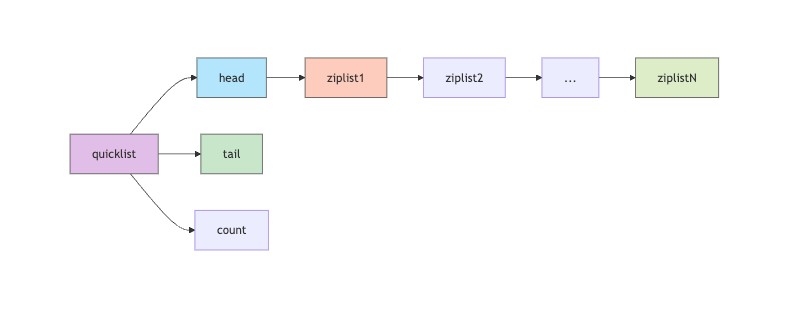
以上流程图展示了quicklist的结构:它由多个ziplist通过指针连接而成,每个ziplist可以存储多个元素。这种结构既保留了ziplist的内存效率,又通过链表结构提高了修改操作的性能。
**配置建议:**redis提供了list-max-ziplist-size和list-compress-depth参数来调整quicklist的行为。根据我的经验,对于元素大小差异较大的列表,可以适当增大list-max-ziplist-size;对于很少进行中间插入/删除操作的列表,可以增大list-compress-depth来节省更多内存。
三、redis list的应用场景
理解了redis list的实现原理后,我们来看看它的典型应用场景。根据我的项目经验,redis list特别适合以下几种场景。
3.1 消息队列
redis list的lpush和brpop组合可以实现简单的消息队列。生产者使用lpush将消息放入列表,消费者使用brpop阻塞等待消息。
// 生产者
jedis.lpush("message_queue", "message1");
// 消费者
list<string> message = jedis.brpop(0, "message_queue");
system.out.println("收到消息: " + message.get(1));
这种实现简单高效,但缺乏专业消息队列的ack机制、重试等功能,适合对可靠性要求不高的场景。
3.2 最新消息排行
社交平台常用redis list存储用户的最新动态,结合lpush和ltrim实现固定长度的最新消息列表。
// 添加新动态
jedis.lpush("user:123:activities", "点赞了文章");
// 保持只保留最新50条动态
jedis.ltrim("user:123:activities", 0, 49);
// 获取最新10条动态
list<string> activities = jedis.lrange("user:123:activities", 0, 9);
3.3 历史记录
电商网站可以用redis list存储用户的浏览历史,结合lpush和lrem确保不重复记录。
// 添加浏览记录前先移除已存在的相同记录
jedis.lrem("user:123:history", 0, "product:456");
jedis.lpush("user:123:history", "product:456");
// 限制历史记录长度
jedis.ltrim("user:123:history", 0, 99);
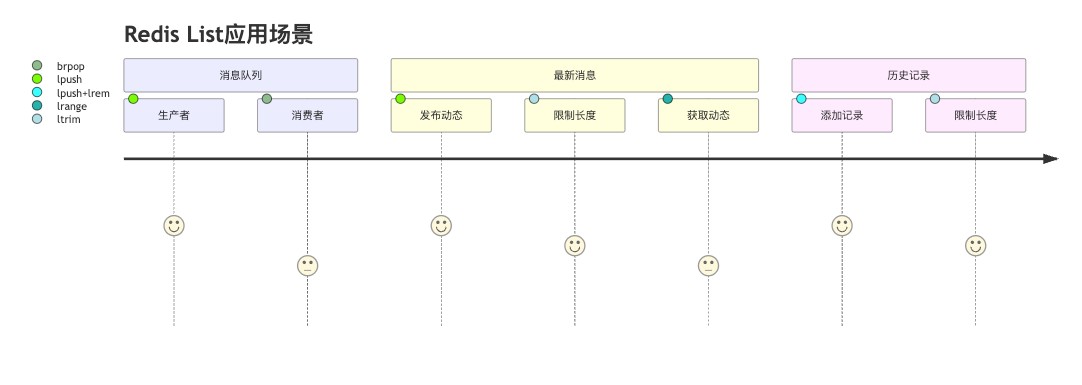
以上用户旅程图展示了redis list在不同应用场景中的典型操作流程和使用频率。
**注意事项:**
- 虽然redis list在很多场景下非常有用,但它并不适合存储非常大的列表(如百万级元素)。
- 对于大数据集,建议考虑其他数据结构或数据库。
- 在我的项目中,当列表长度超过1万时,就会考虑是否应该使用其他解决方案。
四、性能优化与最佳实践
掌握了redis list的基本使用和原理后,我们来看看如何优化其性能和使用效率。根据我的经验,以下几点特别值得注意。
4.1 合理设置ziplist配置
redis的list-max-ziplist-size参数控制quicklist中每个ziplist的最大大小。设置过大可能导致ziplist操作变慢,设置过小会增加内存开销。
# redis.conf配置示例 list-max-ziplist-size -2 # 负数表示按照元素个数限制,正数表示按照字节数限制
-2是默认值,表示每个ziplist最多8kb。对于元素较大的列表,可以适当减小这个值。
4.2 使用批量操作
redis的pipeline机制可以显著提高批量操作的性能,特别是在网络延迟较高的情况下。
pipeline pipeline = jedis.pipelined();
for (int i = 0; i < 100; i++) {
pipeline.lpush("mylist", "item" + i);
}
pipeline.sync();
4.3 避免大列表操作
lrange、ltrim等操作在列表很大时性能较差,应尽量避免对大列表进行全量操作。
**经验分享:**在我的一个项目中,曾经因为使用lrange 0 -1获取一个包含10万元素的列表而导致redis短暂阻塞。后来改为分批获取和游标式遍历,性能得到了显著提升。建议大家对于可能变大的列表,从一开始就设计好分批处理的方案。
五、总结
通过今天的探讨,我们全面了解了redis list的使用方法和内部实现原理。让我们回顾一下主要内容:
- 基本操作:lpush/rpush添加元素,lpop/rpop弹出元素,lrange获取范围元素等
- 内部实现:从ziplist到linkedlist再到quicklist的演变
- 应用场景:消息队列、最新消息排行、历史记录等
- 性能优化:合理配置、批量操作、避免大列表等
redis list是一个简单但强大的数据结构,正确使用它可以为我们的应用带来显著的性能提升。希望通过今天的分享,能帮助大家更好地理解和应用redis list。
在实际项目中,我建议大家可以多尝试不同的使用方式,结合具体场景选择最合适的方案。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论