开篇:从购物车到redis set
想象一下你在网上购物时,把商品加入购物车的场景。当你点击"加入购物车"按钮时,系统需要确保同一件商品不会被重复添加,同时又能快速判断某件商品是否已经在购物车中。这种场景下,redis的set数据结构就像是一个完美的购物车容器。
redis中的set是一个无序的、不重复的字符串集合,它提供了高效的添加、删除和查找操作。就像购物车能自动去重一样,set结构天然支持去重功能。在实际应用中,set常被用于存储用户标签、好友关系、投票系统等场景。今天,我们就来深入探讨redis set的使用方法和内部实现原理。
一、redis set的基本操作
理解了set的应用场景后,我们来看看redis set提供的基本操作。这些操作就像购物车的各种功能按钮,让我们能够方便地管理集合中的元素。
1.1 常用命令
// 添加元素到集合 sadd myset "item1" "item2" "item3" // 获取集合中的所有元素 smembers myset // 判断元素是否在集合中 sismember myset "item1" // 获取集合元素数量 scard myset // 随机移除并返回一个元素 spop myset // 随机返回一个元素但不移除 srandmember myset
上述代码展示了redis set的基本操作命令。sadd用于添加元素,smembers查看所有元素,sismember检查元素是否存在,scard获取元素数量,spop和srandmember用于随机操作元素。
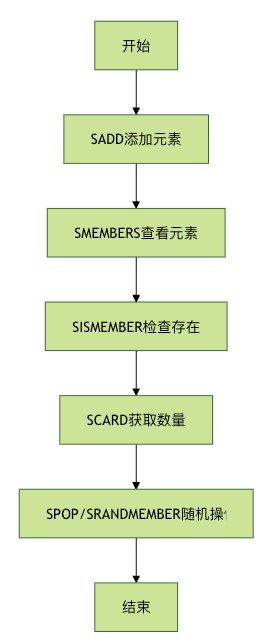
以上流程图说明了redis set的基本操作流程。从添加元素开始,到查看、检查、统计和随机操作,形成了一个完整的数据操作闭环。
1.2 集合运算
redis set还支持丰富的集合运算,这些运算在实际开发中非常有用:
// 求两个集合的差集 sdiff set1 set2 // 求两个集合的交集 sinter set1 set2 // 求两个集合的并集 sunion set1 set2 // 将差集/交集/并集结果存储到新集合 sdiffstore newset set1 set2 sinterstore newset set1 set2 sunionstore newset set1 set2
这些集合运算 命令可以用于各种数据分析场景,比如找出两个用户群的共同好友(sinter),或者找出a用户有但b用户没有的好友(sdiff)。
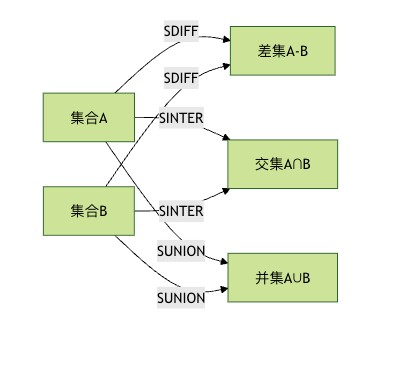
这个图展示了redis set的三种基本集合运算:差集、交集和并集。通过不同的运算,我们可以从原始集合中提取出有价值的信息。
二、redis set的内部实现
了解了基本操作后,我们来看看redis set的内部实现原理。就像了解购物车的构造能帮助我们更好地使用它一样,理解set的内部实现能让我们更高效地使用redis。
2.1 数据结构选择
redis set的底层实现有两种数据结构,根据元素数量和元素大小自动选择:
- intset(整数集合):当集合中所有元素都是整数且元素数量较少时使用
- hashtable(哈希表):当集合包含非整数元素或元素数量较多时使用
这种智能选择的设计就像我们根据购物物品的多少选择不同大小的购物车一样,既节省空间又保证效率。
这个状态图展示了redis选择set底层数据结构的过程。首先检查元素类型和数量,然后决定使用intset还是hashtable。
2.2 intset实现原理详解
intset是redis为整数集合优化设计的一种紧凑数据结构,它的核心特点包括:
2.2.1 内存布局
intset的内存布局非常紧凑,由三部分组成:
struct intset {
uint32_t encoding; // 编码方式:intset_enc_int16/32/64
uint32_t length; // 元素数量
int8_t contents[]; // 实际存储数组
};
这个结构体展示了intset的内存布局。encoding表示元素使用的位数(16/32/64),length是元素数量,contents是柔性数组,实际存储元素数据。
2.2.2 编码升级机制
intset有一个独特的特性:当插入的元素超过当前编码范围时,会自动升级编码:
- 初始创建时默认使用16位(intset_enc_int16)编码
- 当插入32位整数时,升级为32位编码(intset_enc_int32)
- 当插入64位整数时,升级为64位编码(intset_enc_int64)
升级过程需要重新分配内存并转换所有现有元素,这是一个o(n)操作。
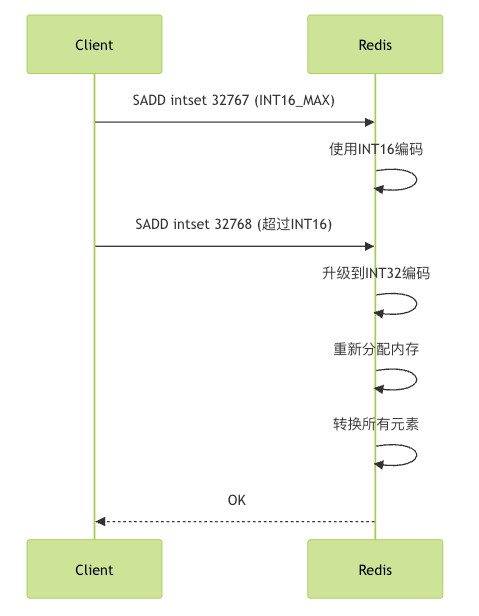
这个序列图展示了intset编码升级的过程。当插入超过当前编码范围的数值时,redis会自动升级编码并转换所有现有元素。
2.2.3 查找与插入
intset使用二分查找来定位元素,保证o(logn)的查找复杂度:
// 伪代码展示intset查找过程
int search(intset *is, int64_t value) {
int low = 0, high = is->length-1;
while(low <= high) {
int mid = (low + high)/2;
int64_t midval = _intsetget(is, mid);
if (value < midval) high = mid - 1;
else if (value > midval) low = mid + 1;
else return mid; // 找到
}
return -1; // 未找到
}
这段伪代码展示了intset的二分查找实现。由于元素是有序存储的,可以使用二分查找快速定位元素位置。
2.3 hashtable实现原理详解
当set使用hashtable实现时,实际上与redis的hash类型使用相同的字典结构,只是value被设置为null。让我们深入分析其实现细节:
2.3.1 字典结构
redis字典的核心结构如下:
typedef struct dict {
dicttype *type; // 类型特定函数
void *privdata; // 私有数据
dictht ht[2]; // 哈希表(两个用于rehash)
long rehashidx; // rehash进度,-1表示未进行
unsigned long iterators; // 正在运行的迭代器数量
} dict;
typedef struct dictht {
dictentry **table; // 哈希表数组
unsigned long size; // 表大小
unsigned long sizemask; // 大小掩码,用于计算索引值
unsigned long used; // 已使用节点数量
} dictht;
typedef struct dictentry {
void *key; // 键
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v; // 值(set中为null)
struct dictentry *next; // 指向下个哈希表节点,形成链表
} dictentry;
这些结构体定义了redis字典的核心实现。dict是顶层结构,包含两个dictht用于渐进式rehash,dictentry是实际的键值对节点。
2.3.2 哈希算法与冲突解决
redis使用murmurhash2算法计算键的哈希值,然后通过取模确定索引位置:
// 计算键的哈希值 hash = dict->type->hashfunction(key); // 计算索引位置 index = hash & dict->ht[0].sizemask;
当发生哈希冲突时,redis使用链地址法解决冲突,即在同一个索引位置形成链表。
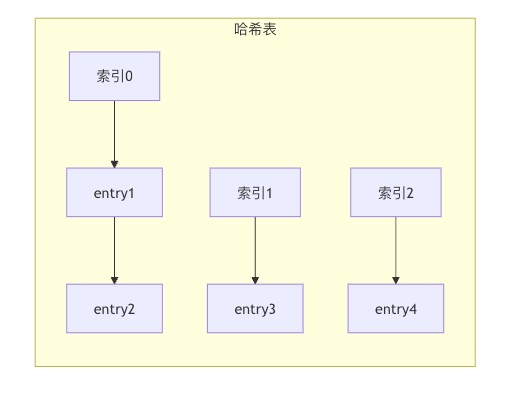
这个图展示了redis哈希表的链式冲突解决方法。相同索引位置的元素通过链表连接起来。
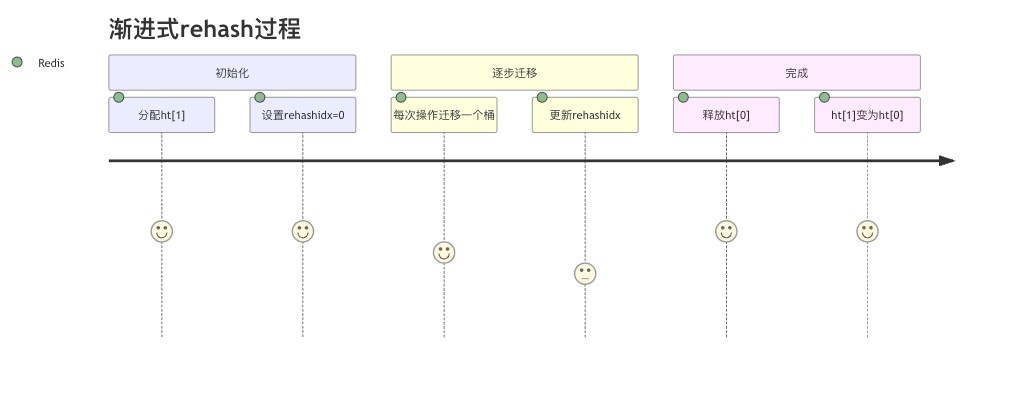
2.3.3 渐进式rehash
当哈希表需要扩容时,redis使用渐进式rehash策略:
- 为ht[1]分配更大的空间(通常是原大小的2倍)
- 设置rehashidx=0,开始rehash
- 每次对字典执行操作时,顺带将ht[0]中的一个索引上的所有键值对rehash到ht[1]
- 当所有键值对都迁移完成后,释放ht[0],将ht[1]设置为ht[0]
这种策略避免了集中式rehash带来的性能问题。
这个用户旅程图展示了渐进式rehash的完整过程。从初始化到逐步迁移,最后完成整个rehash操作。
三、set的应用场景与最佳实践
掌握了set的基本操作和实现原理后,我们来看看它在实际开发中的应用场景和使用技巧。
3.1 典型应用场景
redis set在实际项目中有许多经典应用:
- 用户标签系统:每个用户的标签存储为一个set
- 社交关系:用户的好友、关注列表可以用set存储
- 抽奖系统:使用spop实现随机抽奖
- 共同好友/兴趣:使用sinter计算用户间的共同点
- 黑白名单:使用set实现高效的存在性检查
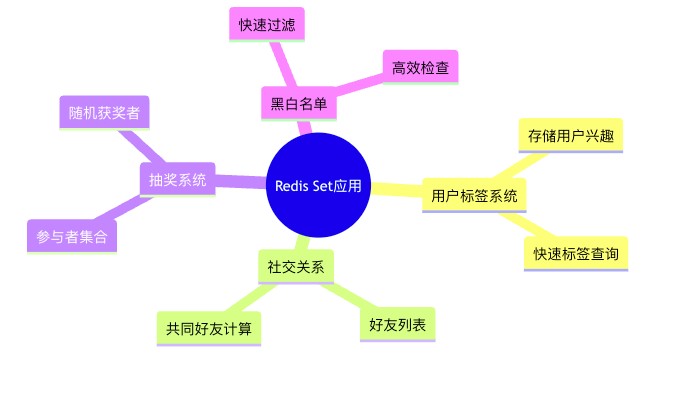
这个思维导图总结了redis set的主要应用场景。从用户标签到社交关系,从抽奖系统到黑白名单,set都能发挥重要作用。
3.2 性能优化建议
为了充分发挥redis set的性能,我有以下建议:
- 对于小型集合(元素少且都是整数),尽量保持使用intset
- 大型集合操作(sinter/sunion等)可能会阻塞redis,考虑在从节点执行
- 频繁的spop操作可以考虑结合管道(pipeline)批量执行
- 超大集合(百万级以上)的smembers操作要谨慎,可能消耗大量内存
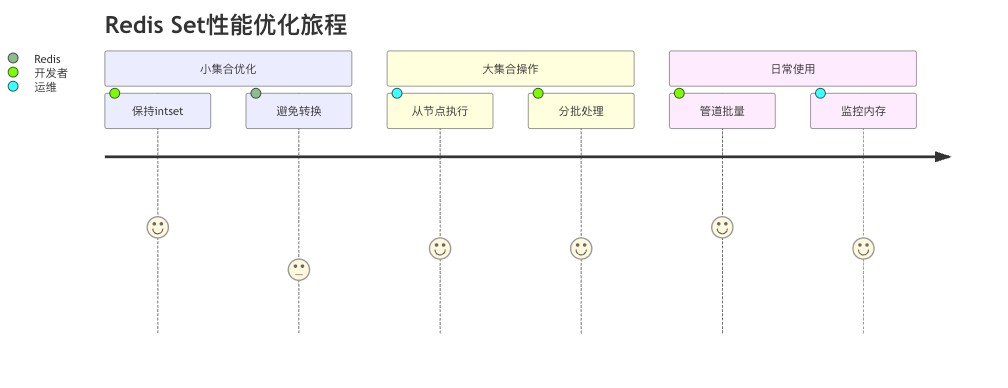
这个用户旅程图展示了redis set性能优化的关键点。从小集合处理到大集合操作,再到日常使用习惯,每个环节都有相应的优化策略。
四、总结
通过今天的讨论,我们对redis set有了全面的认识。让我们总结一下本文的主要内容:
- 基本操作:sadd/smembers/sismember等命令的使用
- 集合运算:sdiff/sinter/sunion等集合操作
- 内部实现:intset的内存布局和编码升级机制,hashtable的字典结构和渐进式rehash
- 应用场景:标签系统、社交关系、抽奖等典型应用
- 性能优化:大小集合的不同处理策略和日常优化建议
redis set是一个功能强大且高效的数据结构,正确使用它可以极大地简化我们的开发工作。
希望这篇文章能帮助大家更好地理解和应用redis set。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。





发表评论