引言
在日常工作中,我们经常需要处理图片文件并将其整理成pdf文档。本文将详细分析一个使用python wxpython框架开发的桌面应用程序,该程序可以解压zip文件中的图片,提供预览功能,并将选定的图片生成pdf文档。通过这个实例,我们将深入了解wxpython gui开发、文件处理、图像处理以及pdf生成的核心技术。
项目概述
这个程序实现了以下核心功能:
- zip文件解压与中文编码处理
- 图片文件自动扫描与分类
- 实时图片预览
- 图片选择与管理
- pdf批量生成
技术栈分析
依赖库解析
import wx # gui框架 import os # 操作系统接口 import zipfile # zip文件处理 import tempfile, shutil # 临时文件和文件操作 import sys # 系统相关参数 from pil import image # 图像处理 from reportlab.pdfgen import canvas # pdf生成 from reportlab.lib.pagesizes import a4 # pdf页面规格 import locale # 本地化支持
每个库都有其特定用途:
- wxpython:提供跨平台的gui开发能力
- pil (pillow):强大的图像处理库,支持多种格式
- reportlab:专业的pdf生成工具
- zipfile:python标准库,处理压缩文件
核心架构设计
类结构分析
程序采用面向对象设计,主要包含两个类:
class imagepdfframe(wx.frame): # 主窗口类 class imagepdfapp(wx.app): # 应用程序类
这种设计遵循了wxpython的标准模式,将界面逻辑与应用程序逻辑分离。
界面布局设计
程序使用了复杂的嵌套布局管理器:
main_sizer = wx.boxsizer(wx.vertical) # 主垂直布局 file_sizer = wx.staticboxsizer(...) # 文件操作区域 work_sizer = wx.boxsizer(wx.horizontal) # 工作区域水平布局
布局结构分析:
1.顶部文件操作区:zip选择、解压路径设置
2.中部工作区:三列布局
- 左列:图片列表 + 预览区
- 中列:操作按钮
- 右列:选中列表 + pdf设置
3.底部状态区:日志显示
关键功能实现详解
1. 中文编码处理机制
这是程序的一个技术亮点,解决了zip文件中文文件名乱码问题:
def on_extract_zip(self, event):
with zipfile.zipfile(self.zip_path, 'r') as zip_ref:
for member in zip_ref.infolist():
try:
# 多层编码尝试机制
member.filename = member.filename.encode('cp437').decode('utf-8')
except:
try:
member.filename = member.filename.encode('cp437').decode('gbk')
except:
pass # 保持原文件名
zip_ref.extract(member, extract_dir)
技术原理:
- zip文件默认使用cp437编码
- 先尝试utf-8解码(现代标准)
- 失败后尝试gbk解码(中文windows常用)
- 多重异常处理确保程序稳定性
2. 图片预览系统
预览功能展示了图像处理的核心技术:
def preview_image(self, image_path):
pil_image = image.open(image_path)
# 智能缩放算法
preview_size = (300, 300)
pil_image.thumbnail(preview_size, image.resampling.lanczos)
# 格式转换链
wx_image = wx.image(pil_image.size[0], pil_image.size[1])
wx_image.setdata(pil_image.convert('rgb').tobytes())
# 显示更新
bitmap = wx.bitmap(wx_image)
self.image_preview.setbitmap(bitmap)
技术要点:
- lanczos重采样:高质量图像缩放算法
- 格式转换:pil → wxpython 格式转换
- 内存管理:避免大图片内存溢出
3. pdf生成引擎
pdf生成是程序的核心功能之一:
def on_generate_pdf(self, event):
c = canvas.canvas(pdf_path, pagesize=a4)
page_width, page_height = a4
for i in range(self.selected_listbox.getcount()):
pil_image = image.open(image_path)
img_width, img_height = pil_image.size
# 智能缩放计算
margin = 50
max_width = page_width - 2 * margin
max_height = page_height - 2 * margin
scale_w = max_width / img_width
scale_h = max_height / img_height
scale = min(scale_w, scale_h, 1.0) # 不放大原则
# 居中对齐计算
new_width = img_width * scale
new_height = img_height * scale
x = (page_width - new_width) / 2
y = (page_height - new_height) / 2
c.drawimage(image_path, x, y, width=new_width, height=new_height)
c.showpage() # 新页面
c.save()
算法亮点:
- 等比缩放:保持图片宽高比
- 不放大原则:避免图片质量损失
- 智能居中:自动计算最佳位置
- 页面管理:每张图片独立页面
事件驱动编程模式
wxpython使用事件驱动模式,程序中大量使用了事件绑定:
self.select_zip_btn.bind(wx.evt_button, self.on_select_zip) self.image_listbox.bind(wx.evt_listbox, self.on_image_select)
事件处理特点:
- 解耦设计:界面与逻辑分离
- 响应式:用户交互即时响应
- 状态管理:基于用户操作更新程序状态
错误处理与用户体验
异常处理策略
程序采用多层异常处理:
try:
# 核心操作
pil_image = image.open(image_path)
except exception as e:
self.log(f"预览图片失败: {str(e)}")
# 优雅降级,不影响主流程
用户反馈机制
def log(self, message):
if isinstance(message, bytes):
message = message.decode('utf-8', errors='ignore')
self.status_text.appendtext(f"{message}\n")
实时状态日志让用户了解程序运行状态。
内存管理与性能优化
临时文件管理
def __del__(self):
if hasattr(self, 'temp_dir') and self.temp_dir:
try:
shutil.rmtree(self.temp_dir)
except:
pass
程序结束时自动清理临时文件,防止磁盘空间浪费。
图片处理优化
- 缩略图生成:避免加载完整大图
- 按需加载:只在预览时加载图片
- 格式转换:统一使用rgb格式
跨平台兼容性
编码处理
if sys.version_info[0] >= 3:
import locale
encoding = locale.getpreferredencoding() if hasattr(locale, 'getpreferredencoding') else 'utf-8'
路径处理
使用os.path.join()确保路径分隔符跨平台兼容。
运行结果
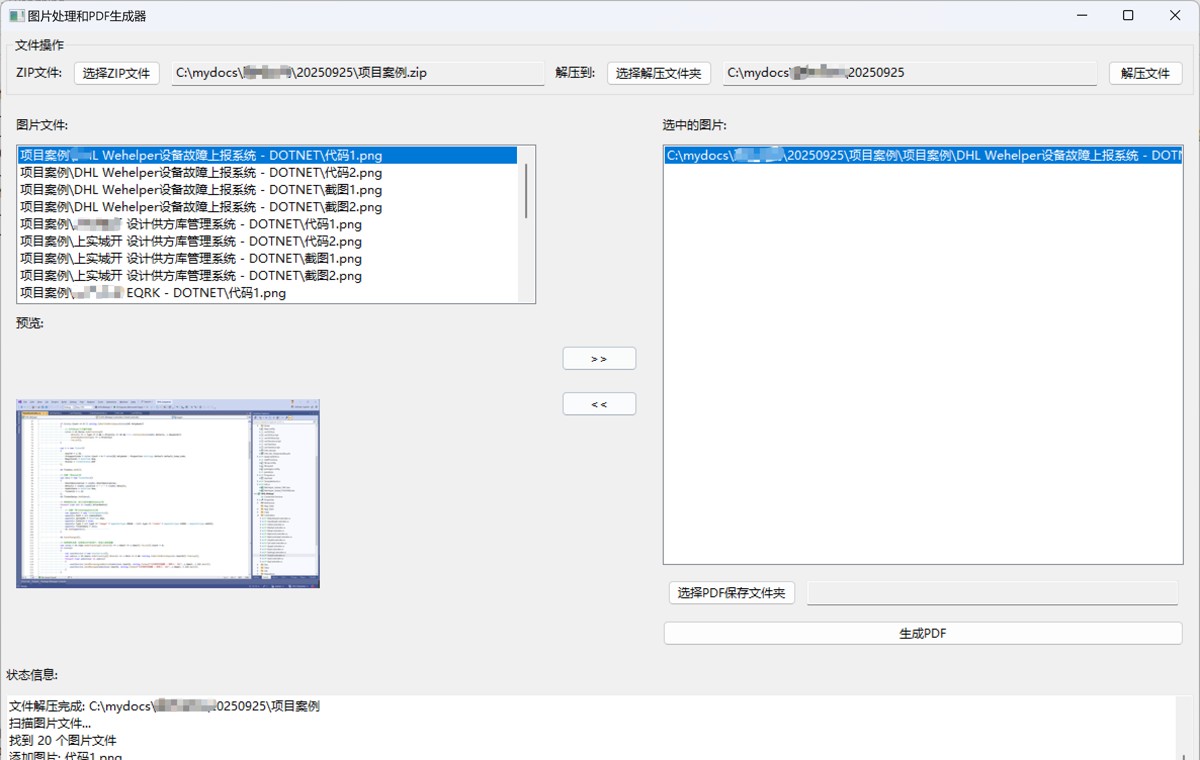
到此这篇关于基于python实现图片处理与pdf生成小程序的文章就介绍到这了,更多相关python图片处理与pdf生成内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论