需求:
一次性处理24个文档的页码。
文档详情:
1、每个word文档包含800页左右,每一页包含一个标题和一张图片。
2、由于图片有横排也有竖排,因此,每页文档都进行了分节处理。
3、但每一节的页码格式不统一,并且没有连续编号。
要求:
1、所有页面的页码必须连续编号。
2、所有页面的页码格式必须统一(字体、字号相同)。
如果手工处理工作量很大,因为无法全部选中页脚。使用python语言程序来处理上述文档,程序代码如下:
from docx import document
from docx.oxml.shared import qn
from docx.oxml import parse_xml
def process_word_document(doc_path, output_path):
# 打开word文档
doc = document(doc_path)
# 获取文档中的所有节
sections = doc.sections
print(f"文档共有 {len(sections)} 个节")
# 处理第一节(特殊处理,不链接到前一节)
first_section = sections[0]
first_footer = first_section.footer
# 清除第一节页脚内容
for paragraph in list(first_footer.paragraphs):
p = paragraph._element
p.getparent().remove(p)
for table in list(first_footer.tables):
t = table._element
t.getparent().remove(t)
print("已处理第1节")
# 处理其他节
for i, section in enumerate(sections[1:], 1):
footer = section.footer
# 清除页脚内容
for paragraph in list(footer.paragraphs):
p = paragraph._element
p.getparent().remove(p)
for table in list(footer.tables):
t = table._element
t.getparent().remove(t)
# 设置页脚链接到前一节
footer.is_linked_to_previous = true
# 设置页码为续前节
sectpr = section._sectpr
pgnumtype = sectpr.find(qn('w:pgnumtype'))
if pgnumtype is none:
pgnumtype = parse_xml(r'<w:pgnumtype xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"/>')
sectpr.append(pgnumtype)
# 移除start属性以确保续前节
start_attr = qn('w:start')
if pgnumtype.get(start_attr) is not none:
pgnumtype.attrib.pop(start_attr, none)
# 每处理100节打印一次进度
if (i + 1) % 100 == 0:
print(f"已处理 {i + 1} 个节")
# 保存文档
doc.save(output_path)
print(f"处理完成! 共处理了 {len(sections)} 个节")
print("所有节的页脚已清除,设置为链接到前一节,且页码设置为续前节")
# 使用示例
if __name__ == "__main__":
input_file = r"d:\wgx\ok\a619.docx" # 输入文件路径
output_file = r"d:\wgx\ok\a6190.docx" # 输出文件路径
process_word_document(input_file, output_file)
由于程序代码调用了第三方库(python-docx),因此需要先安装python-docx库才能运行上述代码。
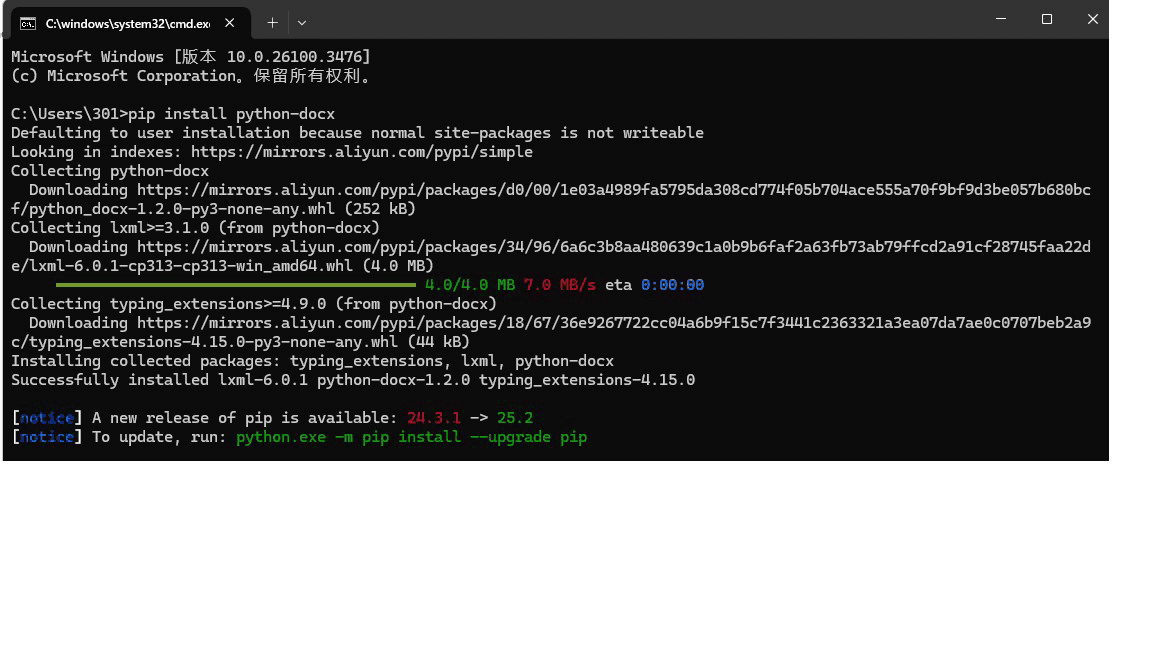
打开windows命令行窗口,执行如下命令:
pip install python-docx
执行结果如下图所示:
打开python集成环境,执行上面的程序代码。结果如下:
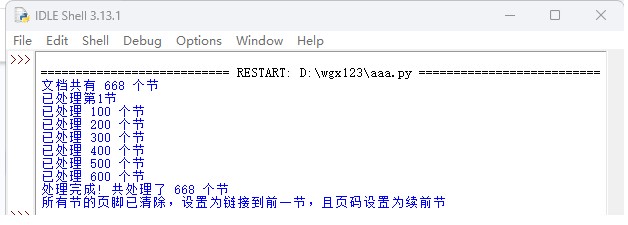
该程序的功能是:
1、清除所有节中页脚的内容(包括页码)。
2、设置每一节【链接到前一节】属性。
3、设置每一节的页码为【续前节】。
执行完毕后,在文档的任意一节中手工插入页码,设置页码的格式即可。则整个文档的页码格式保持一致,并且每一节连续编号。
总结
到此这篇关于利用python操作word文档页码的文章就介绍到这了,更多相关python操作word文档页码内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论