一、为什么要分库分表?
随着业务量增大,单表数据量可能达到千万、甚至亿级,单机mysql的性能瓶颈逐渐暴露。分库分表可以:
- 提升性能:减少单表数据量,提升查询效率。
- 扩展容量:突破单机存储限制。
- 分散压力:多节点分担读写压力。
二、分库分表的常见方案
分库分表(sharding)
- 水平分表:按某字段(如user_id)分散到不同表。
- 水平分库:按某字段分散到不同库。
- 垂直分表/分库:按业务模块拆分(如用户库、订单库)。
分片策略
- 范围分片(range):如user_id 1~10000在库a,10001~20000在库b。
- 哈希分片(hash):如user_id % 4,分到4个库。
- 混合分片:结合多种方式。
三、mycat简介
mycat 是一个开源的分布式数据库中间件,类似于shardingsphere,支持mysql、oracle等后端。它为应用提供统一入口,自动路由sql到对应分片。
核心功能:
- 分库分表
- 分片路由
- 读写分离
- 分布式事务(xa/柔性事务)
四、mycat分库分表深度解析
1. 架构原理
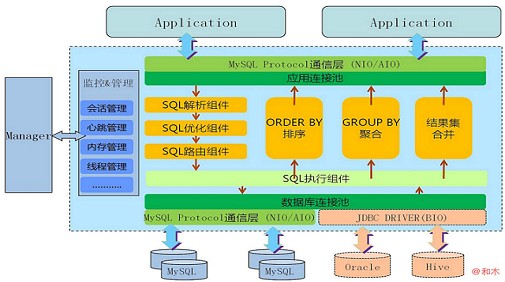
- 应用只连接mycat,mycat负责解析sql、路由、聚合结果。
- mycat与后端mysql建立连接池。
2. 分片配置
主要涉及两个文件:
- schema.xml:定义逻辑库、表、分片规则。
- rule.xml:定义分片算法。
schema.xml 示例
<schema name="userdb" checksqlschema="false" sqlmaxlimit="100">
<table name="user" primarykey="id" autoincrement="true" datanode="dn1,dn2,dn3,dn4" rule="mod_hash">
</table>
</schema>
<datanode name="dn1" datahost="localhost1" database="userdb1" />
<datanode name="dn2" datahost="localhost2" database="userdb2" />
<datanode name="dn3" datahost="localhost3" database="userdb3" />
<datanode name="dn4" datahost="localhost4" database="userdb4" />rule.xml 示例
<tablerule name="mod_hash">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tablerule>
<function name="mod-long" class="io.mycat.route.function.partitionbymod">
<property name="count">4</property>
</function>解析:
- 按照
id % 4路由到 4 个分片。 - 你可以根据业务选择不同的分片算法。
3. 路由机制
- 插入:mycat根据分片字段(如id)计算目标分片,插入到对应库表。
- 查询:mycat根据sql条件判断分片,路由到目标库表。聚合查询时会分发到所有分片,最后聚合结果。
- 分页:mycat会在各分片分别分页,然后聚合。
4. 读写分离
mycat支持主从库配置,自动将读操作路由到从库,写操作到主库。
5. 分布式事务
- xa事务:强一致性,性能较低。
- 柔性事务:业务层保证最终一致性。
五、开发与运维注意事项
分片字段选取
- 应该是高频查询条件,且能均匀分布数据。
跨分片查询
- 聚合、排序、分页等操作,mycat会全库分发,性能受限。
自增主键问题
- 各分片自增可能冲突,建议用uuid或雪花id。
分片扩容
- 新增分片需要迁移数据,提前设计好分片方案。
事务一致性
- 跨分片事务需谨慎处理,推荐业务层补偿。
六、常见问题解析
分片热点问题
- 分片字段分布不均,导致某分片压力过大。需优化分片算法。
全局唯一主键
- 多分片自增冲突,需用分布式id生成器(如雪花算法)。
分页查询慢
- mycat需要在所有分片分页,聚合后再返回,性能较差。可优化业务逻辑。
分片扩容与迁移
- 数据迁移复杂,需提前预估分片数量。
分布式事务
- 强一致性性能低,建议业务层柔性处理。
七、mycat分库分表实战建议
- 表设计:提前规划分片字段和主键生成方式。
- 分片算法:选择合适的分片策略,保证数据均匀分布。
- 监控与扩容:实时监控分片压力,预留扩容方案。
- sql优化:尽量避免跨分片复杂查询。
- 测试与演练:定期做分片扩容、数据迁移演练。
结论
mysql + mycat 分库分表是应对大数据量、高并发场景的常见方案。mycat作为中间件,极大简化了分布式数据库的开发和运维,但也带来了新的挑战。合理设计分片方案、主键策略、事务处理,是系统稳定高效的关键。
如果你有具体的应用场景或配置需求,可以补充问题,我会帮你进一步分析!
八、mycat分库分表实际配置样例
假设有一个订单系统,需要对订单表(order)按用户id分库分表,分成2个库,每库2张表。
1. schema.xml
<schema name="orderdb" checksqlschema="false" sqlmaxlimit="100">
<table name="order" primarykey="order_id" autoincrement="true"
datanode="dn1.order_0,dn1.order_1,dn2.order_0,dn2.order_1"
rule="user_id_mod_4">
</table>
</schema>
<datanode name="dn1.order_0" datahost="mysql1" database="orderdb1" table="order_0"/>
<datanode name="dn1.order_1" datahost="mysql1" database="orderdb1" table="order_1"/>
<datanode name="dn2.order_0" datahost="mysql2" database="orderdb2" table="order_0"/>
<datanode name="dn2.order_1" datahost="mysql2" database="orderdb2" table="order_1"/>
<datahost name="mysql1" maxcon="1000" mincon="10" balance="0"
writetype="0" dbtype="mysql" dbdriver="native">
<heartbeat>select 1</heartbeat>
<writehost host="192.168.1.101" url="192.168.1.101:3306" user="root" password="123456"/>
</datahost>
<datahost name="mysql2" maxcon="1000" mincon="10" balance="0"
writetype="0" dbtype="mysql" dbdriver="native">
<heartbeat>select 1</heartbeat>
<writehost host="192.168.1.102" url="192.168.1.102:3306" user="root" password="123456"/>
</datahost>2. rule.xml
<tablerule name="user_id_mod_4">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tablerule>
<function name="mod-long" class="io.mycat.route.function.partitionbymod">
<property name="count">4</property>
</function>解释:
user_id % 4,分到4个分片(2库×2表)。- 例如,
user_id=7,7%4=3,则落在第4个分片(dn2.order_1)。
九、自定义分片算法代码(java)
如果你需要更复杂的分片,比如按某个范围或自定义规则,可以自定义分片类。
例如,按order_id的哈希后分片:
package io.mycat.route.function;
import io.mycat.route.function.abstractpartitionalgorithm;
public class partitionbyorderidhash extends abstractpartitionalgorithm {
@override
public int calculate(string columnvalue) {
int count = 4; // 分片数
int hash = columnvalue.hashcode();
return math.abs(hash) % count;
}
}配置到rule.xml:
<function name="orderid-hash" class="io.mycat.route.function.partitionbyorderidhash"/>
然后在tablerule里引用:
<tablerule name="order_id_hash">
<rule>
<columns>order_id</columns>
<algorithm>orderid-hash</algorithm>
</rule>
</tablerule>十、分片扩容与数据迁移方案
分片扩容是运维的难题,通常分为增加分片节点和数据迁移两步。
1. 扩容方案设计
假设原来有4个分片,现在扩展到8个分片。
- 原分片规则:
user_id % 4 - 新分片规则:
user_id % 8
步骤:
- 新增数据库节点和表结构。
- 修改mycat的schema.xml和rule.xml,使分片数变为8。
- 迁移原分片数据到新分片。
2. 数据迁移脚本(mysql示例)
假设原来orderdb1.order_0存储的是user_id%4=0的数据,现在新规则是user_id%8=0或4,你需要把user_id%8=4的数据迁移到新分片。
-- 假设新分片为orderdb3.order_0 insert into orderdb3.order_0 select * from orderdb1.order_0 where mod(user_id,8)=4; delete from orderdb1.order_0 where mod(user_id,8)=4;
建议:
- 迁移时做好数据校验和备份,避免丢失。
- 可以用java/python批量迁移脚本,或用etl工具。
- 迁移期间可只读,或采用双写策略,确保数据一致。
3. 迁移流程图
- 备份数据
- 新建分片库表
- 分批迁移数据
- 校验数据一致性
- 切换mycat配置
- 观察一段时间,确认无误后清理老数据
十一、补充建议
- 分片字段一旦确定,后期变更代价大,需提前规划。
- 迁移过程建议业务低峰期进行,并做好回滚预案。
- 分片扩容也可采用预留分片(空分片),后续直接启用,减少迁移难度。
到此这篇关于mycat分库分表的项目实践的文章就介绍到这了,更多相关mycat分库分表内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论