当我们还在焦虑geforce rtx 5090 d 32gb可能也要用不上的时候,geforce rtx 5090 d v2的悄然上市给旗舰级显卡的选择带来了新的参考,不过代价是32gb显存变成了24gb。被缩减了显存geforce rtx 5090 d v2还能不能被称为旗舰级显卡的问题不仅被摆上了台面,与之对应的是显卡的实际售价其实与头部的rtx 5090 d和rtx 5090有更多的距离。
眼前的索泰geforce rtx 5090 d v2 24gb solid oc就是好例子,它的官方定价相比超频定位的rtx 5090 d差价大概在3000元左右,而如果是对比实际能购入的rtx 5090第三方平台价格,差价甚至可以再买下一块rtx 5070。

仔细一盘算,同样旗舰定位的geforce rtx 5090 d v2似乎有了性价比,那么事实是否真的如此?现在就让我们奉上索泰geforce rtx 5090 d v2 24gb solid oc评测。

代号:gb202-240-k1-a1
在短时间内对核心部分进行修改并顺利流片是不太可能的,因此geforce rtx 5090 d v2的gpu核心依然为gb202,代号gb202-240-k1-a1,与geforce rtx 5090 d与geforce rtx 5090系出同源,基于blackwell 2.0架构,因为gb100系列和blackwell 1.0是针对ai超算、数据中心和服务器设计,2.0版本则是针对消费端、游戏技术进行硬件层面的调整。

无论索泰geforce rtx 5090 d v2 24gb solid oc的gb202-240-k1-a1 gpu,还是geforce rtx 5090 founders edition的gb202-300-a1,本质上都并非gb202的完全体。一般出于产品定位、制造良率、后续升级等多方面考虑,方便可以在短时间内根据市场需求推出更具有竞争力的产品。
完整的gb202很有必要提一提。blackwell架构延续了此前ampere和ada lovelace架构理念,在一个gpu中包含若干个gpc(graphics processing clusters,图形处理集群),每个gpc下面再包含若干个tpc(texture processing clusters,纹理处理集群),每个tpc下包含若干个sm(streaming multiprocessors,流式多处理器),同时再搭配显存控制器等周边电路。
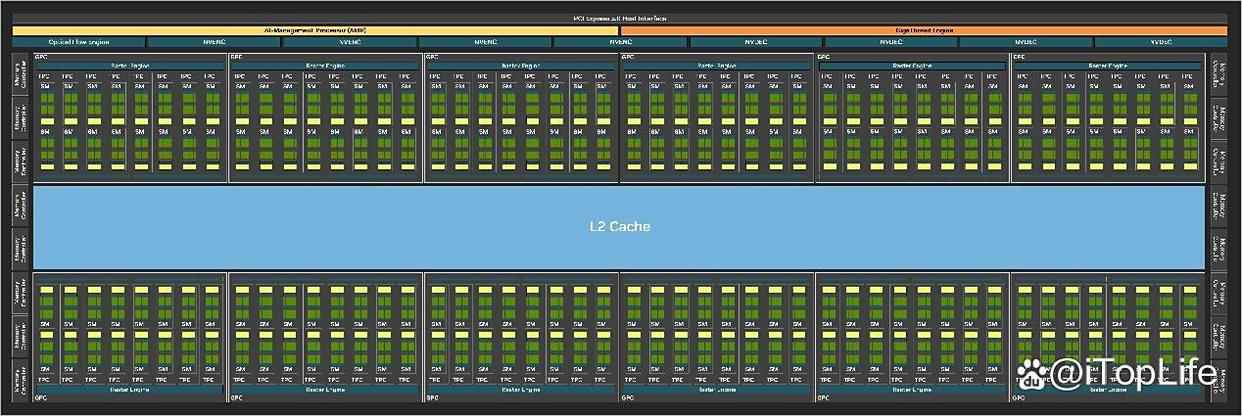
另外每个sm内部的升级也代表着当前微架构升级的关键,也是完成大规模并行任务的关键,比如cuda core,第五代tensor core,第四代rt core都包含其中。
完整的gb202 gpu包括12个gpc(graphics processing clusters,图形处理集群),96个tpc(texture processing clusters,纹理处理集群),192个sm(streaming multiprocessors,流式多处理器),以及1个512-bit内存接口,配备有16个32-bit内存控制器,用于对显存进行控制。
值得注意,gb202 gpu还包含了384个fp64核心,即每sm包含两个,fp64 tflop速率是fp32 tflop速率的1/64,对于消费端而言使用频率不高,但可以保证fp64代码可以被正确的执行。对应的,tensor core也包含了少量的fp64 tensor来确保程序的正确执行。
gpc是所有blackwell gb20x gpu最主要运算单位,每个关键图形处理单元都会摆放在gpc中,每个gpc包括一个专用的光栅引擎(raster engine),2组rop集群(raster operations,光栅操作),每个光栅操作分区包括8个独立的rop单元,8个tpc,每个tpc包含1个polymorph引擎和2个sm。

其中polymorph引擎主要用于处理图形和计算任务中的几何变换和曲面细分,在处理复杂几何图形的时候,可以获得更高效的多任务能力。
sm是nvidia gpu架构中的核心部件,也是gpu可以完成大规模并行任务的关键,比如cuda core,tensor core,rt core都包含其中。完整的gb202包括192个sm,每个sm包括128个cuda core,1个第四代rt core,4个第五代tensor core,4个纹理单元(texture units),1个512kb寄存器文件,128kb l1共享缓存,这些缓存可以根据图形和计算工作负载需求进行重新配置。
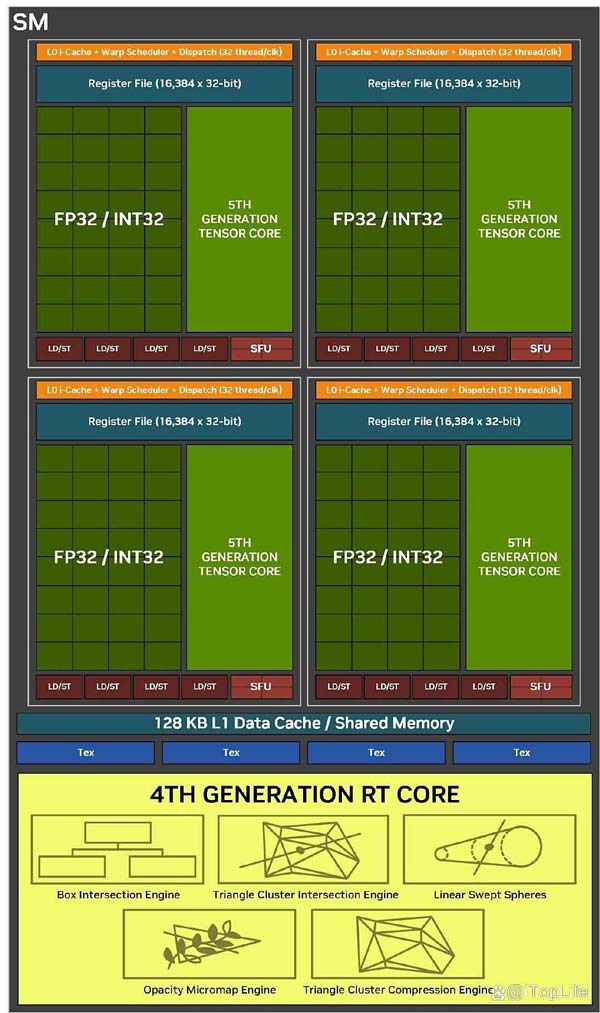
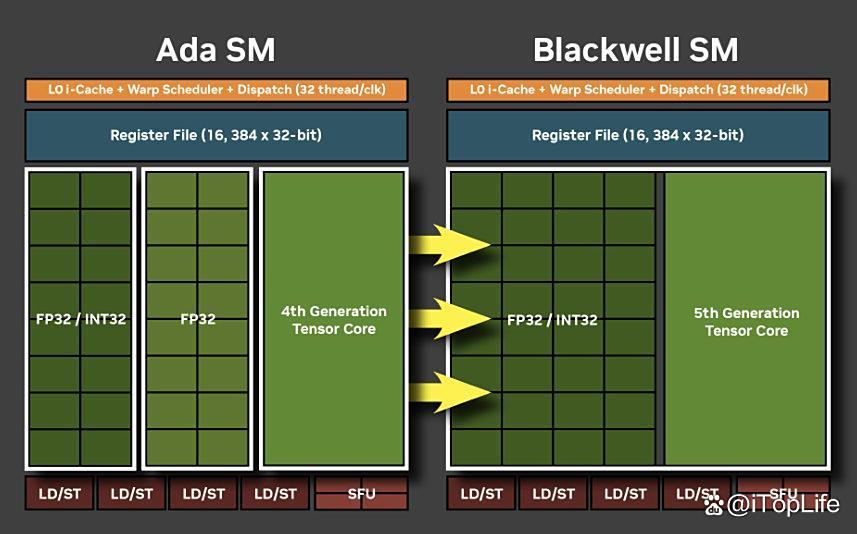
blackwell架构下,int32整数运算相比ada lovelace是翻倍的。原因是int32和fp32核心进行了完全统一,这也体现了blackwell sm针对神经网络着色器设计和优化。当然,这也意味着在同一个时钟周期内,只能进行fp32或者int32其中一个操作。
完整的gb202 gpu还包含了128mb l2缓存,geforce rtx 5090 d则包含96mb l2缓存,所有的应用在大容量高速缓存中都能受益,特别是光线追踪和路径追踪这样的复杂操作。
因此,完整的gb202 gpu包括:
- 24576 个cuda core
- 192个第四代 rt core
- 768个第五代tensor core
- 768个纹理单元(texture units)
- 索泰geforce rtx 5090 d v2 24gb solid oc的gb202-240-k1-a1上,通过对部分硬件的调整,比较关键的变化如下:
- 21760 个cuda core
- 170个第四代 rt core
- 680个第五代tensor core
- 680个纹理单元(texture units)
- 在这个基础上,gddr7显存颗粒的减少,让显存容量、带宽都与之对应的减少:
- geforce rtx 5090 / rtx 5090 d:32 gb gddr7
- geforce rtx 5090 d v2:24 gb gddr7(砍掉 8 gb)
- geforce rtx 5090 / rtx 5090 d:512-bit,1792 gb/s
- geforce rtx 5090 d v2:384-bit,1344 gb/s(带宽减少25%)
因此得出如下对比参数表格作为参考:
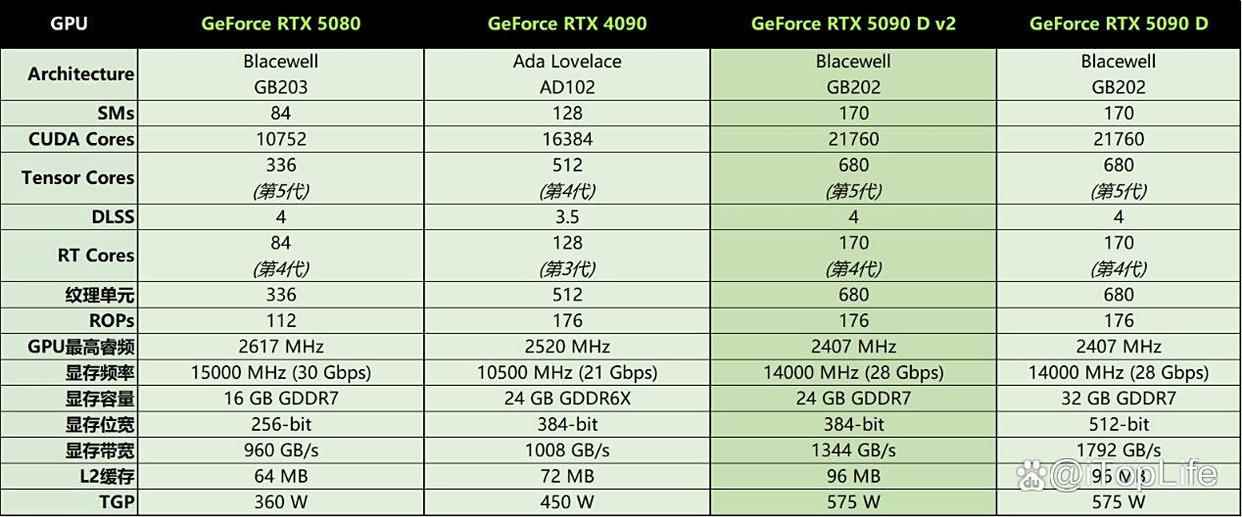
通过对比可以看到,geforce rtx 5090 d v2基础光栅性能仍然非常能打,比如纹理单元(texture units)由geforce rtx 4090的512个增加到了680个。纹理单元负责处理纹理映射操作,包括从纹理中获取纹理元素(texels),应用纹理过滤以及纹理坐标处理等等。其中纹理元素(texels)代表纹理信息、颜色、图案,这些信息被应用于3d表面,定义了物体表面纹理外观。
solid oc装甲
索泰geforce rtx 50 solid系列放在一众旗舰级非公版显卡中相当能打,长时间霸占旗舰级显卡散热的第一梯队。事实上geforce rtx 5090 d到geforce rtx 5090 d v2在散热、供电布局上差别不大,geforce rtx 5090 d上那一套优秀的散热模组完全无缝转移到了索泰geforce rtx 5090 d v2 24gb solid oc上。

因此索泰geforce rtx 5090 d v2 24gb solid oc延续了solid系列的极简工业风格,通过银灰配色搭配纵横栅让整张显卡显得大气十足,同时通过显卡边缘的暗金点缀让显卡气场拉满。

solid系列没有做过多的rgb灯效设计,所有rgb效果都放在尾部的zotac gaming和logo的1600万色rgb内,整张显卡再无其他rgb点缀,对于追求低调的游戏玩家而言非常理想。

与此同时,geforce rtx 5090 d v2 24gb solid oc提供了独立的5v argb同步接口,方便与整机rgb实现光效同步。

在散热模组中,索泰geforce rtx 5090 d v2 24gb solid oc使用了一套面积更大vc均热板,对比上一代增加了34%的覆盖面积,一次性覆盖了gpu和gddr7显存的所有位置,并且显存位置还独立提供了导热垫,确保散热效率。

发表评论