1. 文档的重要性
良好的文档是高质量软件项目的关键组成部分,它不仅帮助用户理解如何使用软件,也帮助开发者理解代码的工作原理和设计决策。
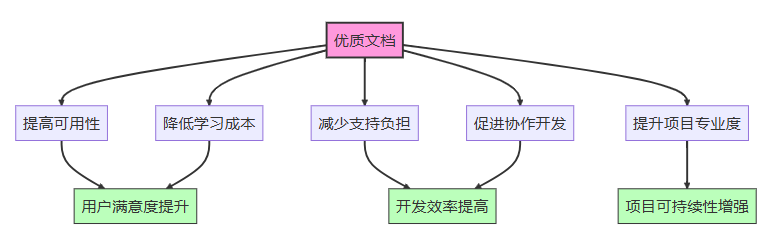
文档类型
python项目中常见的文档类型:
- 代码内文档:注释、文档字符串(docstrings)
- api文档:函数、类、模块的接口说明
- 教程和指南:帮助用户入门和掌握功能
- 示例代码:展示如何使用api的实际例子
- 架构文档:系统设计和组件交互说明
- 贡献指南:帮助其他开发者参与项目
- 变更日志:记录版本间的变化
2. python文档字符串(docstrings)
文档字符串是python中内置的代码文档机制,可以为模块、类、函数和方法提供文档。
2.1 基本语法
def calculate_area(radius):
"""
计算圆的面积。
args:
radius (float): 圆的半径
returns:
float: 圆的面积
raises:
valueerror: 当半径为负数时
"""
if radius < 0:
raise valueerror("半径不能为负数")
return 3.14159 * radius * radius
2.2 文档字符串风格
google风格
def fetch_data(url, timeout=30, retry=3):
"""获取指定url的数据。
此函数发送http get请求到指定url,并返回响应内容。
支持超时和重试机制。
args:
url (str): 要请求的url地址
timeout (int, optional): 请求超时时间,单位为秒。默认为30秒。
retry (int, optional): 失败重试次数。默认为3次。
returns:
dict: 包含响应数据的字典
raises:
connectionerror: 当网络连接失败时
timeouterror: 当请求超时时
examples:
>>> data = fetch_data('https://api.example.com/data')
>>> print(data['status'])
'success'
"""
# 函数实现...
numpy/scipy风格
def fetch_data(url, timeout=30, retry=3):
"""
获取指定url的数据。
parameters
----------
url : str
要请求的url地址
timeout : int, optional
请求超时时间,单位为秒,默认为30秒
retry : int, optional
失败重试次数,默认为3次
returns
-------
dict
包含响应数据的字典
raises
------
connectionerror
当网络连接失败时
timeouterror
当请求超时时
examples
--------
>>> data = fetch_data('https://api.example.com/data')
>>> print(data['status'])
'success'
"""
# 函数实现...
restructuredtext风格(sphinx默认)
def fetch_data(url, timeout=30, retry=3):
"""获取指定url的数据。
此函数发送http get请求到指定url,并返回响应内容。
支持超时和重试机制。
:param url: 要请求的url地址
:type url: str
:param timeout: 请求超时时间,单位为秒,默认为30秒
:type timeout: int, optional
:param retry: 失败重试次数,默认为3次
:type retry: int, optional
:return: 包含响应数据的字典
:rtype: dict
:raises connectionerror: 当网络连接失败时
:raises timeouterror: 当请求超时时
.. code-block:: python
>>> data = fetch_data('https://api.example.com/data')
>>> print(data['status'])
'success'
"""
# 函数实现...
2.3 类和模块的文档字符串
"""
数据处理模块
此模块提供了一系列用于处理和转换数据的函数。
主要功能包括数据清洗、转换和验证。
examples:
>>> from mypackage import data_processing
>>> data_processing.clean_data(my_data)
"""
class dataprocessor:
"""
数据处理器类
此类提供了处理各种数据格式的方法。
attributes:
input_format (str): 输入数据格式
output_format (str): 输出数据格式
logger (logger): 日志记录器
"""
def __init__(self, input_format, output_format):
"""
初始化数据处理器
args:
input_format (str): 输入数据格式,支持'json'、'csv'、'xml'
output_format (str): 输出数据格式,支持'json'、'csv'、'xml'
"""
self.input_format = input_format
self.output_format = output_format
self.logger = self._setup_logger()
3. 自动文档生成工具
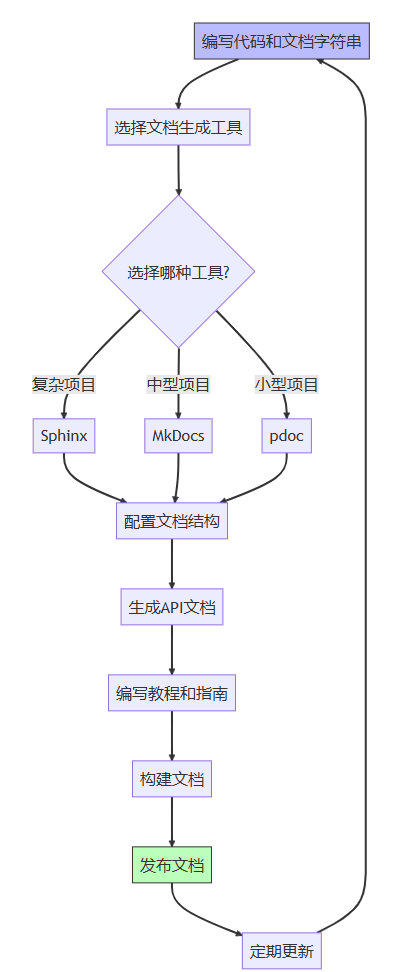
3.1 sphinx
sphinx是python生态系统中最流行的文档生成工具,可以从文档字符串生成html、pdf等格式的文档。
基本设置
# 安装sphinx pip install sphinx sphinx-rtd-theme # 创建文档项目 mkdir docs cd docs sphinx-quickstart
配置sphinx
# docs/conf.py
import os
import sys
sys.path.insert(0, os.path.abspath('..')) # 添加项目根目录到路径
# 项目信息
project = 'myproject'
copyright = '2025, your name'
author = 'your name'
release = '0.1.0'
# 扩展
extensions = [
'sphinx.ext.autodoc', # 自动从docstrings生成文档
'sphinx.ext.viewcode', # 添加源代码链接
'sphinx.ext.napoleon', # 支持google和numpy风格的docstrings
]
# 主题
html_theme = 'sphinx_rtd_theme'
创建文档
.. myproject documentation master file welcome to myproject's documentation! ===================================== .. toctree:: :maxdepth: 2 :caption: contents: installation usage api contributing indices and tables ================= * :ref:`genindex` * :ref:`modindex` * :ref:`search`
生成api文档
# 自动生成api文档 sphinx-apidoc -o docs/api mypackage # 构建html文档 cd docs make html
3.2 mkdocs
mkdocs是一个快速、简单的静态站点生成器,专注于构建项目文档。
# 安装mkdocs和主题 pip install mkdocs mkdocs-material # 创建项目 mkdocs new my-project cd my-project # 配置 # 编辑mkdocs.yml
# mkdocs.yml site_name: myproject theme: name: material nav: - home: index.md - installation: installation.md - usage: usage.md - api: api.md - contributing: contributing.md markdown_extensions: - pymdownx.highlight - pymdownx.superfences
3.3 pdoc
pdoc是一个简单的api文档生成工具,特别适合小型项目。
# 安装pdoc pip install pdoc # 生成文档 pdoc --html --output-dir docs mypackage
3.4 文档工作流
4. api设计原则
良好的api设计可以显著提高代码的可用性和可维护性。
4.1 核心原则
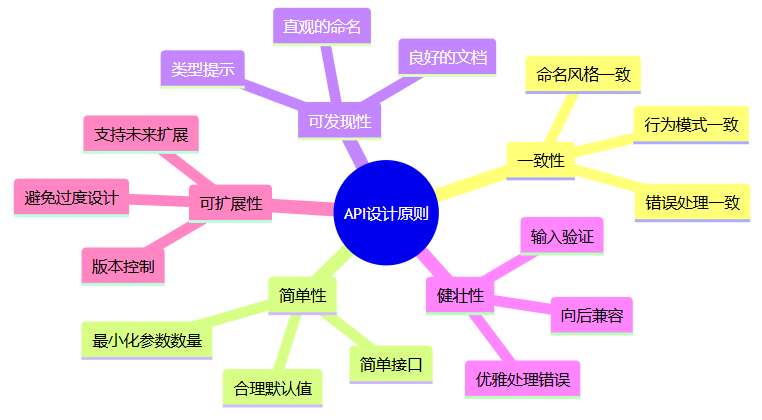
4.2 命名约定
python api设计中的命名约定:
- 模块名:简短、全小写,可使用下划线(例如:
data_processing) - 类名:驼峰命名法(例如:
dataprocessor) - 函数和方法名:小写,使用下划线分隔(例如:
process_data) - 常量:全大写,使用下划线分隔(例如:
max_retry_count) - 私有属性和方法:以单下划线开头(例如:
_private_method) - "魔术"方法:双下划线开头和结尾(例如:
__init__)
4.3 接口设计模式
参数设计
# 好的设计:使用关键字参数和合理默认值
def connect(host, port=8080, timeout=30, use_ssl=false):
# 实现...
pass
# 不好的设计:位置参数过多,难以记忆
def connect(host, port, timeout, use_ssl, retry_count, backoff_factor):
# 实现...
pass
使用数据类
from dataclasses import dataclass
@dataclass
class connectionconfig:
host: str
port: int = 8080
timeout: int = 30
use_ssl: bool = false
retry_count: int = 3
backoff_factor: float = 0.5
def connect(config: connectionconfig):
# 实现...
pass
# 使用方式
config = connectionconfig(host="example.com")
connect(config)
# 或者自定义更多参数
custom_config = connectionconfig(
host="example.com",
port=443,
use_ssl=true,
timeout=60
)
connect(custom_config)
链式api
# 链式api设计
class querybuilder:
def __init__(self):
self.filters = []
self.sorts = []
self.limit_value = none
def filter(self, **kwargs):
self.filters.append(kwargs)
return self # 返回self以支持链式调用
def sort_by(self, field, ascending=true):
self.sorts.append((field, ascending))
return self
def limit(self, value):
self.limit_value = value
return self
def execute(self):
# 执行查询并返回结果
pass
# 使用方式
results = querybuilder().filter(status="active").sort_by("created_at", ascending=false).limit(10).execute()
上下文管理器
class databaseconnection:
def __init__(self, connection_string):
self.connection_string = connection_string
self.connection = none
def __enter__(self):
self.connection = self._connect()
return self.connection
def __exit__(self, exc_type, exc_val, exc_tb):
if self.connection:
self.connection.close()
def _connect(self):
# 实现连接逻辑
pass
# 使用方式
with databaseconnection("postgresql://user:pass@localhost/db") as conn:
results = conn.execute("select * from users")
4.4 错误处理
异常设计
# 定义异常层次结构
class apierror(exception):
"""api错误的基类"""
pass
class connectionerror(apierror):
"""连接相关错误"""
pass
class authenticationerror(apierror):
"""认证相关错误"""
pass
class resourcenotfounderror(apierror):
"""请求的资源不存在"""
pass
# 使用异常
def get_resource(resource_id):
try:
# 尝试获取资源
if not resource_exists(resource_id):
raise resourcenotfounderror(f"resource {resource_id} not found")
return fetch_resource(resource_id)
except networkerror as e:
# 转换为api特定异常
raise connectionerror(f"failed to connect: {str(e)}") from e
返回值设计
from typing import dict, any, optional, tuple, union
# 方法1:使用异常
def process_data(data: dict[str, any]) -> dict[str, any]:
if not validate_data(data):
raise valueerror("invalid data format")
# 处理数据
return processed_data
# 方法2:返回结果和错误
def process_data(data: dict[str, any]) -> tuple[optional[dict[str, any]], optional[str]]:
if not validate_data(data):
return none, "invalid data format"
# 处理数据
return processed_data, none
# 方法3:使用result对象
class result:
def __init__(self, success: bool, value: any = none, error: str = none):
self.success = success
self.value = value
self.error = error
def process_data(data: dict[str, any]) -> result:
if not validate_data(data):
return result(success=false, error="invalid data format")
# 处理数据
return result(success=true, value=processed_data)
5. api版本控制
随着api的发展,版本控制变得至关重要,以保持向后兼容性。
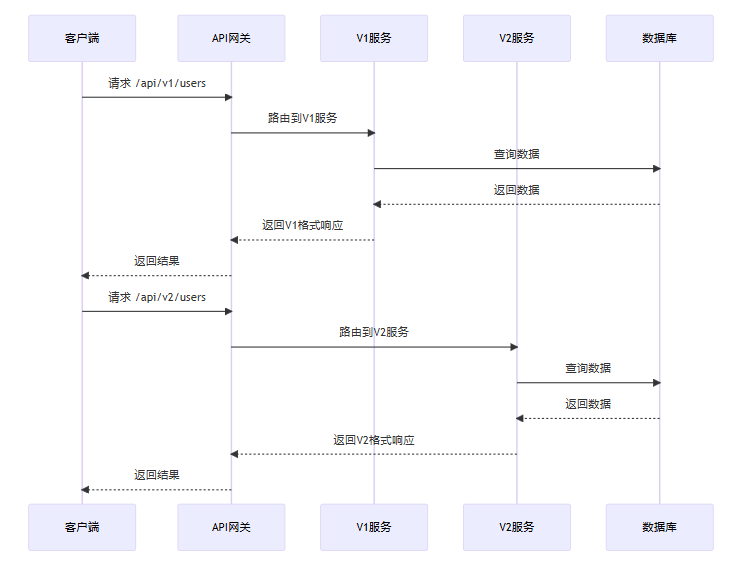
5.1 版本控制策略

5.2 python库的版本控制
# 方法1:导入时版本控制
# mylib/v1/__init__.py
def process_data(data):
# v1实现
pass
# mylib/v2/__init__.py
def process_data(data):
# v2实现,可能有不同的参数或返回值
pass
# 使用
from mylib import v1, v2
result1 = v1.process_data(data)
result2 = v2.process_data(data)
# 方法2:参数版本控制
def process_data(data, version=2):
if version == 1:
# v1实现
pass
else:
# v2实现
pass
5.3 弃用流程
import warnings
def old_function():
warnings.warn(
"old_function() is deprecated and will be removed in version 2.0. "
"use new_function() instead.",
deprecationwarning,
stacklevel=2
)
# 实现...
def new_function():
# 新实现...
pass
6. api文档最佳实践
6.1 文档结构
一个完整的api文档应包含:
- 概述:api的目的和主要功能
- 安装指南:如何安装和设置
- 快速入门:简单的示例代码
- 教程:详细的使用指南
- api参考:所有公共接口的详细说明
- 高级主题:深入的概念和技术
- 常见问题:faq和故障排除
- 变更日志:版本历史和变更记录
6.2 示例驱动文档
示例驱动文档是一种通过实际代码示例来说明api用法的方法。
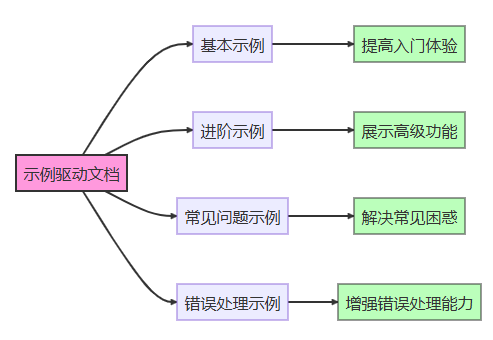
# 数据处理模块
##此模块提供了处理csv数据的函数。
## 基本用法
from mylib import process_csv
# 处理csv文件
result = process_csv('data.csv', delimiter=',')
print(f"处理了 {result['rows']} 行数据")
高级用法
from mylib import process_csv, dataprocessor
# 自定义处理器
processor = dataprocessor(skip_headers=true)
result = process_csv('data.csv', processor=processor)
6.3 交互式文档
使用jupyter notebook或google colab创建交互式文档:
# 安装nbsphinx扩展
pip install nbsphinx
# 在sphinx配置中添加
# conf.py
extensions = [
# ...
'nbsphinx',
]
7. 实用api设计模式
7.1 工厂模式
class parser:
def parse(self, data):
raise notimplementederror
class jsonparser(parser):
def parse(self, data):
import json
return json.loads(data)
class xmlparser(parser):
def parse(self, data):
import xml.etree.elementtree as et
return et.fromstring(data)
class csvparser(parser):
def parse(self, data):
import csv
import io
return list(csv.reader(io.stringio(data)))
class parserfactory:
@staticmethod
def get_parser(format_type):
if format_type == 'json':
return jsonparser()
elif format_type == 'xml':
return xmlparser()
elif format_type == 'csv':
return csvparser()
else:
raise valueerror(f"unsupported format: {format_type}")
# 使用
parser = parserfactory.get_parser('json')
result = parser.parse('{"name": "john", "age": 30}')
7.2 策略模式
from abc import abc, abstractmethod
class compressionstrategy(abc):
@abstractmethod
def compress(self, data):
pass
@abstractmethod
def decompress(self, data):
pass
class gzipcompression(compressionstrategy):
def compress(self, data):
import gzip
return gzip.compress(data)
def decompress(self, data):
import gzip
return gzip.decompress(data)
class zlibcompression(compressionstrategy):
def compress(self, data):
import zlib
return zlib.compress(data)
def decompress(self, data):
import zlib
return zlib.decompress(data)
class datahandler:
def __init__(self, compression_strategy=none):
self.compression_strategy = compression_strategy
def set_compression_strategy(self, compression_strategy):
self.compression_strategy = compression_strategy
def save_data(self, data, filename):
if self.compression_strategy:
data = self.compression_strategy.compress(data)
with open(filename, 'wb') as f:
f.write(data)
def load_data(self, filename):
with open(filename, 'rb') as f:
data = f.read()
if self.compression_strategy:
data = self.compression_strategy.decompress(data)
return data
# 使用
handler = datahandler()
handler.set_compression_strategy(gzipcompression())
handler.save_data(b"hello world", "data.gz")
7.3 构建器模式
构建器模式是一种创建型设计模式,它允许您逐步构建复杂对象,而不需要一次性提供所有参数。
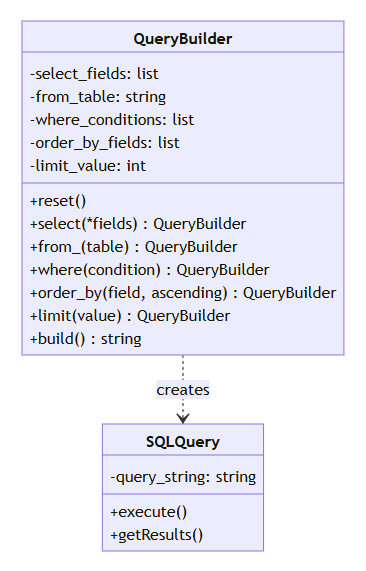
class querybuilder:
def __init__(self):
self.reset()
def reset(self):
self.select_fields = []
self.from_table = none
self.where_conditions = []
self.order_by_fields = []
self.limit_value = none
def select(self, *fields):
self.select_fields = fields
return self
def from_(self, table):
self.from_table = table
return self
def where(self, condition):
self.where_conditions.append(condition)
return self
def order_by(self, field, ascending=true):
self.order_by_fields.append((field, ascending))
return self
def limit(self, value):
self.limit_value = value
return self
def build(self):
if not self.select_fields:
raise valueerror("select clause is required")
if not self.from_table:
raise valueerror("from clause is required")
query = f"select {', '.join(self.select_fields)} from {self.from_table}"
if self.where_conditions:
query += f" where {' and '.join(self.where_conditions)}"
if self.order_by_fields:
order_clauses = []
for field, ascending in self.order_by_fields:
direction = "asc" if ascending else "desc"
order_clauses.append(f"{field} {direction}")
query += f" order by {', '.join(order_clauses)}"
if self.limit_value is not none:
query += f" limit {self.limit_value}"
return query
# 使用
query = querybuilder().select("id", "name").from_("users").where("age > 18").order_by("name").limit(10).build()
构建器模式的优点:
- 允许逐步构建对象
- 支持方法链式调用
- 隐藏复杂的构建过程
- 提高代码可读性
8. 练习:api设计与文档
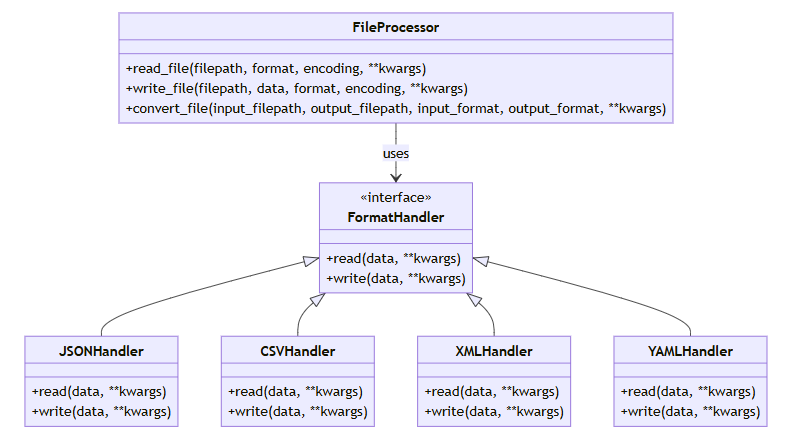
练习1:设计一个文件处理api
设计一个简单但灵活的文件处理api,支持读取、写入和转换不同格式的文件。
| 格式 | 读取支持 | 写入支持 | 所需依赖 | 特点 |
|---|---|---|---|---|
| json | ✅ | ✅ | 内置json模块 | 结构化数据,易读易写 |
| csv | ✅ | ✅ | 内置csv模块 | 表格数据,兼容电子表格 |
| xml | ✅ | ✅ | 内置xml模块 | 复杂结构,支持命名空间 |
| yaml | ✅ | ✅ | pyyaml | 人类可读,支持复杂结构 |
| toml | ✅ | ✅ | tomli/tomli-w | 配置文件格式,易读易写 |
| excel | ✅ | ✅ | openpyxl | 电子表格,支持多工作表 |
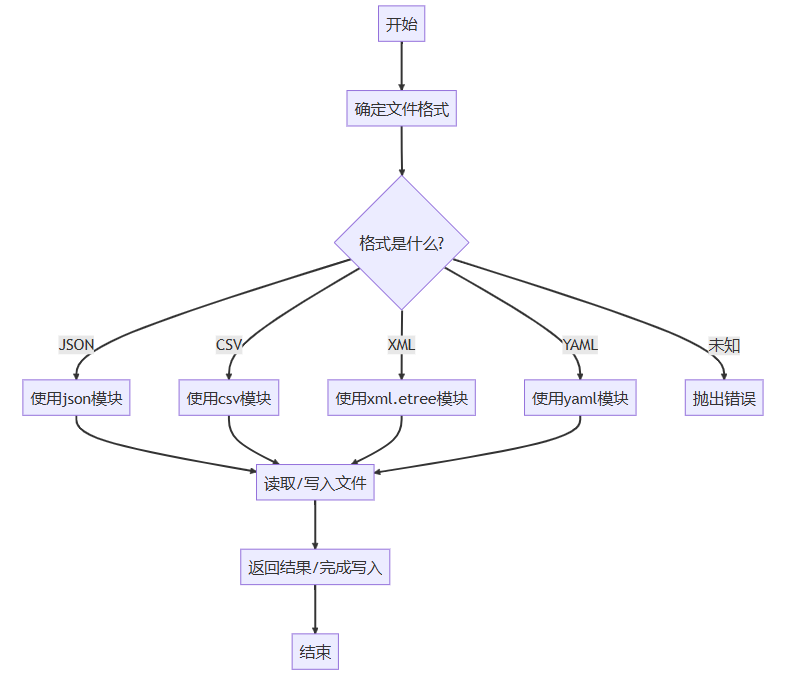
文件处理模块
此模块提供了处理各种文件格式的功能,包括读取、写入和转换。
examples:
from file_processor import read_file, write_file, convert_file
data = read_file('data.json')
write_file('data.csv', data, format='csv')
convert_file('data.json', 'data.xml')
以上就是python自动设计与生成api文档的详细内容,更多关于python生成api文档的资料请关注代码网其它相关文章!






发表评论