1.效果
1.1本地文件
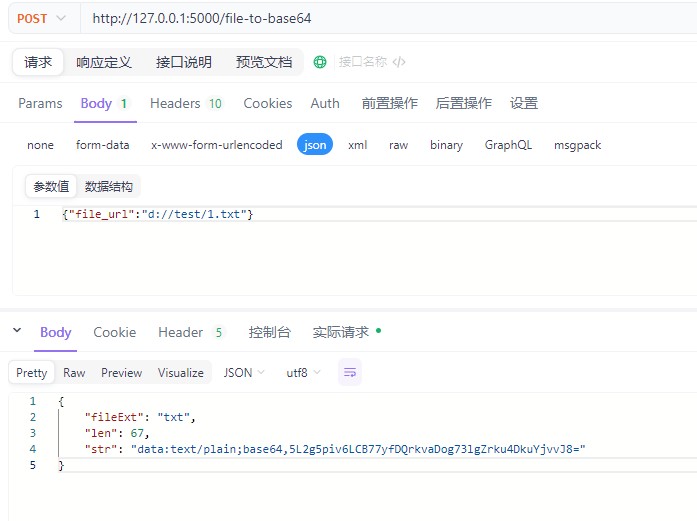
1.2网络文件
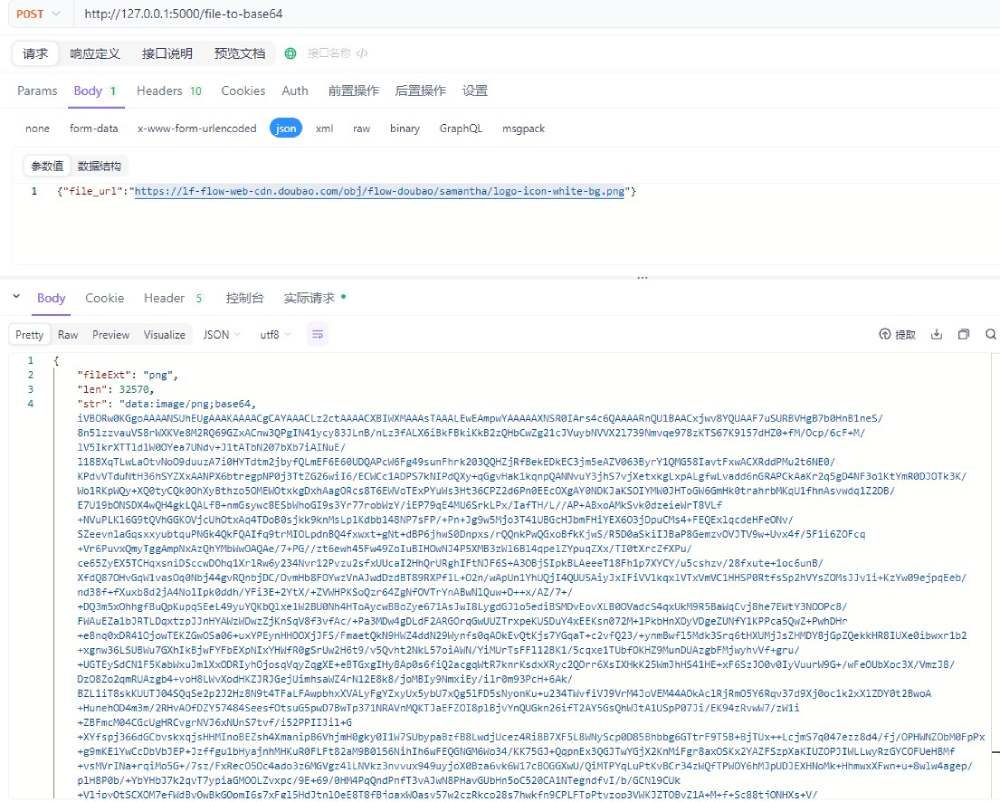
2.filetobase64.py
输出日志:/logs/file-to-base64--{当前时间}.log
开放端口:5000
2.1脚本内容
from flask import flask, request, jsonify
import requests
import base64
import logging
import os
from logging.handlers import timedrotatingfilehandler
from datetime import datetime
import mimetypes
app = flask(__name__)
# 配置日志目录
log_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'logs')
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 按年月日构建日志文件路径
current_date = datetime.now().strftime('%y%m%d')
log_file = os.path.join(log_dir, f'file-to-base64-{current_date}.log')
# 配置日志
logging.basicconfig(
level=logging.info,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.streamhandler(),
timedrotatingfilehandler(
log_file,
when='midnight',
interval=1,
backupcount=30,
encoding='utf-8'
)
]
)
# 输入:{fileurl:xxx} 输出:{fileext:文件类型,len:字符串长度,str:base64字符串}
@app.route('/file-to-base64', methods=['post'])
def file_to_base64():
"""根据文件url(本地路径或网络路径)将文件转换为base64字符串"""
# 每次请求时打印日志,分割
logging.info("-----------------------------------------------------------------------------------------------------------------")
# 1.获取请求头中的 authorization 字段(可选)
authorization = request.headers.get('authorization')
if authorization != 'dpvnrntrqhhmxdfgooea':
logging.warning(f"authorization 字段验证失败: {authorization}")
return jsonify({"error": "authorization verification failed"}), 401
# 2.获取请求参数
data = request.json
if not data or 'file_url' not in data:
logging.warning("请求参数缺失")
return jsonify({"error": "file_url is required"}), 400
# 3. 开始处理文件转换
file_url = data['file_url']
logging.info(f"开始处理文件转换,url: {file_url}")
try:
# 3.1 读取本地文件或网络文件
if file_url.startswith('file://') or os.path.exists(file_url):
# 3.1.1 处理本地文件
if file_url.startswith('file://'):
file_path = file_url[7:]
else:
file_path = file_url
with open(file_path, 'rb') as f:
file_bytes = f.read()
content_type = mimetypes.guess_type(file_path)[0] or 'application/octet-stream'
else:
# 3.1.2 处理网络文件
# 问题:httpsconnectionpool(host='xx.xx.xx.xx', port=443): max retries exceeded with url
# 解决方法:添加 verify=false 忽略证书验证
response = requests.get(file_url, verify=false)
response.raise_for_status()
file_bytes = response.content
content_type = response.headers.get('content-type', '')
# 3.2 通过content-type判断文件类型
file_extension = get_file_extension_from_content_type(content_type)
# 3.3 将文件转换为base64字符串
base64_encoded = base64.b64encode(file_bytes).decode('utf-8')
# 3.4 添加mime类型前缀返回(可选)
if content_type:
base64_encoded = f"data:{content_type};base64,{base64_encoded}"
# 3.5 记录转换结果
logging.info(f"转换成功!文件类型:{file_extension},base64字符串长度: {len(base64_encoded)}")
return jsonify({
"fileext":file_extension,
"len":len(base64_encoded),
"str": base64_encoded
})
# 4. 异常处理
except requests.requestexception as e:
logging.error(f"请求url: {file_url}时出错: {e}")
return jsonify({"error": str(e)}), 500
except exception as e:
logging.error(f"请求url: {file_url}转换发生未知错误: {e}")
return jsonify({"error": "internal server error"}), 500
def get_file_extension_from_content_type(content_type):
"""根据content-type获取文件扩展名"""
# 去除字符集信息,只保留mime类型部分
mime_type = content_type.split(';')[0].strip().lower()
mime_to_extension = {
# 图片类型
'image/jpeg': 'jpg',
'image/png': 'png',
'image/gif': 'gif',
'image/bmp': 'bmp',
'image/webp': 'webp',
'image/svg+xml': 'svg',
# 音频类型
'audio/wav': 'wav',
'audio/mpeg': 'mp3',
'audio/ogg': 'ogg',
'audio/webm': 'weba',
# 视频类型
'video/mp4': 'mp4',
'video/webm': 'webm',
'video/ogg': 'ogv',
# 文档类型
'application/pdf': 'pdf',
'application/msword': 'doc',
'application/vnd.openxmlformats-officedocument.wordprocessingml.document': 'docx',
'application/vnd.ms-excel': 'xls',
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet': 'xlsx',
'application/vnd.ms-powerpoint': 'ppt',
'application/vnd.openxmlformats-officedocument.presentationml.presentation': 'pptx',
# 文本类型
'text/plain': 'txt',
'text/html': 'html',
'text/css': 'css',
'text/javascript': 'js',
'application/javascript': 'js',
'application/json': 'json',
'application/xml': 'xml',
# 压缩文件
'application/zip': 'zip',
'application/x-rar-compressed': 'rar',
'application/x-tar': 'tar',
'application/x-gzip': 'gz',
# 其他常见类型
'application/octet-stream': 'bin',
'application/x-shockwave-flash': 'swf',
'application/x-font-ttf': 'ttf',
'application/x-font-woff': 'woff',
'application/x-font-woff2': 'woff2'
}
return mime_to_extension.get(mime_type, 'unknown')
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)2.2启动查询服务
cd /usr/ai/codes/fileutil # 运行 python3 filetobase64.py # 后台运行 nohup python3 filetobase64.py > /dev/null 2>&1 & # 查看进程 ps -ef | grep filetobase64.py
2.3访问
注意header中authorization=dpvnrntrqhhmxdfgooea目前是写死的。
curl --location --request post 'http://127.0.0.1:5000/file-to-base64' \
--header 'authorization: dpvnrntrqhhmxdfgooea' \
--header 'content-type: application/json' \
--data-raw '{"file_url":"https://lf-flow-web-cdn.doubao.com/obj/flow-doubao/samantha/logo-icon-white-bg.png"}'file_url:必填,需要转换的文件地址(公网http地址,或服务器所在文件的绝对路径)
举例:
{"file_url":"https://lf-flow-web-cdn.doubao.com/obj/flow-doubao/samantha/logo-icon-white-bg.png"}
{"file_url":"/usr/ai/codes/fileutil/readme1.0.0.txt"}
json输出:
{
"fileext": "txt",
"len": 131,
"str": "data:text/plain;base64,5lil6l295zyw5z2a77yadqpodhrwczovl2nvzgvsb2fklmdpdgh1yi5jb20vbgfuz2dlbml1cy9kawz5l3ppcc9yzwzzl2hlywrzl21haw4="
}异常json输出示例:
{
"error": "file_url is required"
}
{
"errmsg": "invalid url 'none': no scheme supplied. perhaps you meant https://none?"
}到此这篇关于python根据文件url将文件转为base64字符串的文章就介绍到这了,更多相关python文件转base64内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论