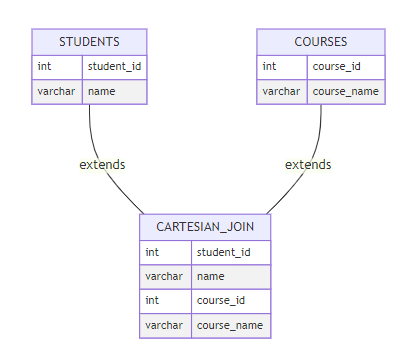
一、笛卡尔积的数学本质
笛卡尔积(cartesian product)是集合论中的基本概念,当我们将表a(m行)和表b(n行)进行笛卡尔积运算时,理论上会生成m×n行的结果集。在关系型数据库中,该运算会产生所有可能的行组合。
数学表达式:a × b = {(a,b) | a ∈ a ∧ b ∈ b}
二、mysql中的实现机制
1. 显式语法
select * from table1 cross join table2;
2. 隐式语法
select * from table1, table2;
3. 执行原理(以nested loop为例)
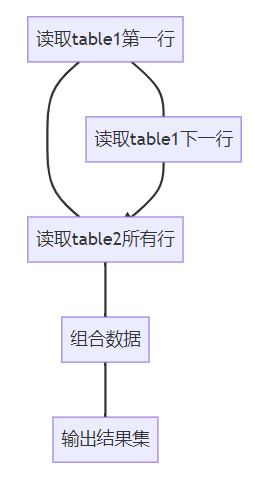
三、性能特征深度分析
假设两个表的行数分别为m和n:
- 时间复杂度:o(m*n)
- 空间复杂度:o(mnrow_size)
- buffer pool影响:可能挤出缓存中的热数据
- 磁盘io成本:全表扫描时产生随机io
示例实验数据:
| 表大小 | 执行时间 | 内存占用 | |--------|-----------|----------| | 100x100| 0.02s | 800kb | | 1000x1000| 2.1s | 80mb | | 10000x10000| 超时 | 8gb |
四、执行计划解析
通过explain查看:
explain select * from employees cross join departments;
典型输出:
+----+-------------+------------+------+---------------+------+---------+------+------+---------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra | +----+-------------+------------+------+---------------+------+---------+------+------+---------------------------------------+ | 1 | simple | employees | all | null | null | null | null | 3000 | using join buffer (block nested loop) | | 1 | simple | departments| all | null | null | null | null | 10 | | +----+-------------+------------+------+---------------+------+---------+------+------+---------------------------------------+
关键指标解读:
- block nested loop:mysql优化后的连接算法
- rows列乘积:3000*10=30000(预期结果行数)
- using join buffer:使用内存缓冲机制
五、实用场景与优化
1. 合理使用场景
- 数据矩阵生成
- 全组合需求(如商品颜色尺寸组合)
- 测试数据构造
2. 优化策略
-- 添加伪连接条件强制使用索引 select * from table1 cross join table2 where 1=1 order by (select 1);
3. 分块处理技巧
select *
from (
select * from table1 limit 1000
) t1
cross join (
select * from table2 limit 1000
) t2;
六、灾难性案例警示
某电商平台误操作:
select * from user_logs -- 2亿行 cross join activity_types; -- 50行
结果:
- 产生100亿条临时数据
- 导致数据库实例oom崩溃
- 恢复时间超过6小时
七、引擎差异对比
| 特性 | innodb | myisam |
|---|---|---|
| 临时表存储 | 磁盘 | 内存(如果足够) |
| 事务支持 | 支持 | 不支持 |
| 行锁机制 | 支持 | 表锁 |
| 崩溃恢复 | 自动 | 需手动修复 |
八、高级应用:条件笛卡尔积
select * from products p cross join variants v where p.category_id = v.category_id and (p.price * v.coefficient) > 100;
执行计划优化路径:

九、监控与防护
- 设置预警阈值:
set global max_join_size=1000000;
- 慢查询监控配置:
# my.cnf配置 long_query_time=2 log_queries_not_using_indexes=1
- explain验证:
explain format=json select * from large_table1 cross join large_table2;
十、新版优化特性(mysql 8.0+)
- hash join优化:
| id | select_type | table | type | possible_keys | key | extra | |----|-------------|-------|------|---------------|------|-------------| | 1 | simple | t1 | all | null | null | | | 1 | simple | t2 | all | null | null | using hash |
- cte materialization:
with cte1 as (select * from table1),
cte2 as (select * from table2)
select * from cte1 cross join cte2;
结语
笛卡尔积查询就像数据库操作中的链锯——在专业场景下是强大工具,但使用不当会造成灾难。建议开发者:
- 显式使用cross join提高可读性
- 查询前进行结果集规模预估
- 生产环境添加保护限制
- 定期审查慢查询日志
最终遵循的原则应该是:如无必要,勿增笛卡尔积。
到此这篇关于mysql连表查询之笛卡尔积查询的文章就介绍到这了,更多相关mysql笛卡尔积查询内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论