在日常的数据处理、文本分析或自然语言处理任务中,字符串匹配是一个常见需求。然而,由于拼写错误、格式差异、缩写等原因,精确匹配(exact matching)往往无法满足实际需求。此时,模糊匹配(fuzzy matching)成为一种更灵活的选择。
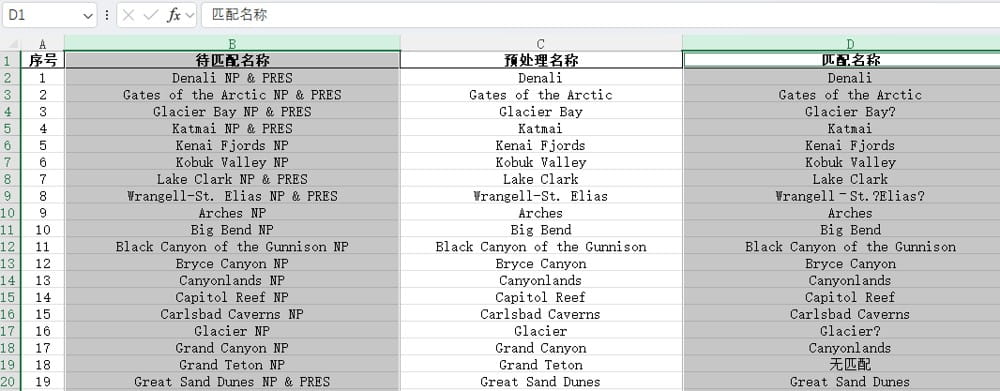
如下图:2个excel中保存了一些公园的不同数据,且只有公园名称能唯一标记一个公园。由于数据来源不同,公园的名称是不完全相同的,且不规则,难以使用正则表达式等精确匹配,此时就可将进行模糊匹配。
一、fuzzywuzzy 简介
fuzzywuzzy 由 seatgeek 公司开发并开源,其核心算法基于 levenshtein 距离(编辑距离),通过计算两个字符串之间需要经过多少次单字符编辑(增、删、改)才能变得相同,来衡量它们的相似性。fuzzywuzzy 进一步优化了这一过程,并提供了多种预定义的相似度计算方式,适用于不同场景。
主要特点:
- 灵活性强:支持部分匹配、忽略顺序匹配、模糊分词匹配等。
- 简单易用:通过封装好的函数即可快速实现复杂匹配逻辑。
- 高效性:结合
python-levenshtein库可大幅提升计算速度。
二、核心功能与 api
fuzzywuzzy 提供了多个相似度计算函数,以下是常用的几种方法:
简单匹配(ratio)
- 计算两个字符串的整体相似度,基于编辑距离。
from fuzzywuzzy import fuzz similarity = fuzz.ratio("apple", "appel") # 输出 86部分匹配(partial ratio)
- 适合比较长字符串与短字符串的匹配程度。例如,在长文本中搜索子串。
fuzz.partial_ratio("apple pie", "apple") # 输出 100
- 词序无关匹配(token sort ratio)
- 先对字符串分词并按字母排序,再计算相似度。适合忽略单词顺序的场景。
fuzz.token_sort_ratio("apple orange", "orange apple") # 输出 100
去重子集匹配(token set ratio)
- 进一步忽略重复词,专注于共有词汇的匹配。
fuzz.token_set_ratio("apple apple", "apple") # 输出 100加权匹配(wratio)
- 综合多种策略,自动选择最佳匹配方式。
fuzz.wratio("apple pie", "apple pi") # 输出 95
三、高级应用:从列表中提取最佳匹配
除了直接比较两个字符串,fuzzywuzzy 的 process 模块支持从候选列表中快速找到与目标最接近的匹配项。
from fuzzywuzzy import process
choices = ["apple", "banana", "orange", "grape"]
result = process.extractone("appel", choices, scorer=fuzz.wratio)
print(result) # 输出 ('apple', 86)
参数说明:
extractone:返回列表中相似度最高的一个结果。scorer:指定相似度计算函数(默认为wratio)。- 支持设置分数阈值(
score_cutoff),过滤低质量匹配。
四、性能优化
fuzzywuzzy 的默认实现可能较慢,尤其是在处理大规模数据时。通过以下方法可以提升性能:
安装
python-levenshtein库
该库用 c 语言实现了 levenshtein 算法,能显著加速计算:pip install python-levenshtein
预处理数据
- 去除字符串中的空格、标点符号。
- 统一转换为小写。
def preprocess(text): return text.lower().strip()限制匹配范围
根据业务逻辑缩小候选列表的范围(如按首字母分组)。
五、应用场景
- 数据清洗
合并重复记录(如用户输入的不同地址变体)。 - 搜索引擎
提升查询纠错能力(如“new yrok” → “new york”)。 - 自然语言处理
实体对齐、同义词扩展。 - 商业场景
商品名称匹配、发票信息核对。
六、优缺点分析
优点:
- 简单直观,适合快速实现模糊匹配需求。
- 支持多种匹配策略,灵活应对不同场景。
- 与 python 生态集成良好(如 pandas)。
缺点:
- 对长文本效果较差(计算复杂度高)。
- 默认依赖
python-levenshtein,可能需额外安装。 - 不直接支持非英文文本(需结合分词工具)。
替代方案
- difflib
python 标准库中的文本对比工具,功能较基础。 - rapidfuzz
性能更优的 fuzzywuzzy 替代品,api 兼容。 - jellyfish
支持更多字符串距离算法(如 jaro-winkler)。
七、完整代码示例
import pandas as pd
from fuzzywuzzy import process
# 定义需要去除的词
words_to_remove = ["np", "&", "pres", "n.m", "n.r."]
# 预处理函数:去除特定词
def preprocess_name(name):
for word in words_to_remove:
name = name.replace(word, "").strip() # 去除词并去掉多余空格
return name
# 读取excel文件
df_all_parks = pd.read_excel("all.xlsx") # 替换为你的文件名
df_some_parks = pd.read_excel("结果.xlsx") # 替换为你的文件名
# 提取公园名称列表
all_park_names = df_all_parks["英文名称"].dropna().unique().tolist() # 替换"公园名称"为实际列名
some_park_names = df_some_parks["park name"].dropna().unique().tolist()
# 模糊匹配并记录结果
results = []
i = 0
for name in some_park_names:
# 预处理名称:去除特定词
cleaned_name = preprocess_name(name)
# 获取最佳匹配(阈值可调)
match, score = process.extractone(cleaned_name, all_park_names, scorer=process.fuzz.token_sort_ratio)
if score >= 60: # 仅当相似度≥60%时处理
# 找到在df_all_parks中匹配的行
matched_rows = df_all_parks[df_all_parks["英文名称"] == match]
# 提取匹配行的distance值
distances = matched_rows["distance"].tolist() # 替换"distance"为实际列名
# 记录结果
for i, distance in enumerate(distances):
results.append({
'序号': '',
"待匹配名称": name, # 原始名称
"预处理名称": cleaned_name, # 预处理后的名称
"匹配名称": match,
"相似度": score,
"行号": matched_rows.index[i], # 记录行号
"distance": distance # 添加distance列的值
})
else:
results.append({
'序号': '',
"待匹配名称": name,
"预处理名称": cleaned_name,
"匹配名称": "无匹配",
"相似度": score,
"行号": [],
"distance": none # 无匹配时distance为空
})
# 转换为dataframe并保存结果
result_df = pd.dataframe(results)
result_df.to_excel("模糊匹配结果.xlsx", index=false)
print("匹配完成!结果已保存到 '模糊匹配结果.xlsx'")
到此这篇关于python中不规则字符串模糊匹配(fuzzywuzzy)的文章就介绍到这了,更多相关python不规则字符串模糊匹配内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论