链接提取, 正则神器, 批量文本, 小白脚本
故事开场
周一上午,老板甩给你一个 200 页的会议记录 txt:“把里面所有网址整理成 excel,午饭前给我!”
你打开文档一看,密密麻麻全是文字,网址藏在各个角落,复制粘贴能点到手抽筋。
这时,你从抽屉掏出“小白瑞士军刀”——links_extractor.py。
把它拖到 txt 文件上,双击,三秒后自动生成 xxx_links.txt,所有网址排队站好。
你直接复制进 excel,泡杯咖啡的功夫就交差。痛点解决:再也不用肉眼找链接,省时 99%。
代码解析
功能块 1:把文件读进来
像翻书一样,先把整本 txt 读进内存,后面才好找东西。
def read_text_file(file_path):
with open(file_path, encoding='utf-8') as f:
return f.read()
加 encoding='utf-8' 防止中文乱码,小白也能放心用。
功能块 2:用“网址捕手”抓链接
正则表达式就像一张渔网,http 开头或 www 开头都能一网打尽。
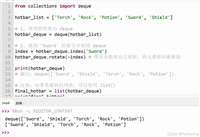
import re
def extract_urls(text):
pattern = r"(?:(?:https?|ftp):\/\/)?[\w/\-?=%.]+\.[\w/\-?=%.]+"
return re.findall(pattern, text)
re.findall 一次性把所有匹配结果装进列表,方便后面输出。
功能块 3:把结果写成新文件
抓到的链接按行写进 原文件名_links.txt,清爽不覆盖原文件。
def export_urls(urls, file_path):
with open(file_path.replace(".txt", "_links.txt"), "w", encoding='utf-8') as f:
f.write("\n".join(urls))
一行一个链接,excel 直接粘贴即可。
功能块 4:一键启动入口
把上面三块拼起来,双击脚本就能跑。
if __name__ == "__main__":
import sys
get_urls(sys.argv[1])
运行方式:
python links_extractor.py 会议记录.txt
如果还想更厉害
扩展点子 1:批量扫描整个文件夹
一次性抓完目录里所有 txt,结果合并到一张表。
import glob, os
all_urls = []
for txt_file in glob.glob("*.txt"):
all_urls.extend(extract_urls(read_text_file(txt_file)))
with open("all_links.txt", "w", encoding='utf-8') as f:
f.write("\n".join(set(all_urls))) # set 去重
双击后,整个文件夹的网址全进 all_links.txt。
扩展点子 2:加个迷你窗口,拖文件就能跑
用 tkinter 做 gui,小白再也不用敲命令。
import tkinter as tk
from tkinter.filedialog import askopenfilename
root = tk.tk()
root.withdraw() # 隐藏主窗口
file = askopenfilename(filetypes=[("text files", "*.txt")])
if file:
get_urls(file)
tk.messagebox.showinfo("完成", f"已生成 {file}_links.txt")
双击脚本→弹窗选文件→秒出结果,全程鼠标操作。
方法补充
使用python一次性批量下载网页内所有链接
完整代码
import os
import requests
from bs4 import beautifulsoup
# 目标网页的url
url = "https://" # 请将此处替换为实际的网页url
# 指定下载文件的文件夹路径
# 使用原始字符串
download_folder = r"d:\"
# 或者使用双反斜杠
# download_folder = "d:\\ascholarfolder\\"
# 创建下载文件夹(如果不存在)
if not os.path.exists(download_folder):
os.makedirs(download_folder)
# 获取网页内容
response = requests.get(url)
if response.status_code == 200:
soup = beautifulsoup(response.text, 'html.parser')
# 找到所有的 <a> 标签
for a_tag in soup.find_all('a'):
href = a_tag.get('href')
if href:
# 下载文件
file_name = href.split('/')[-1]
file_path = os.path.join(download_folder, file_name)
try:
file_response = requests.get(href)
if file_response.status_code == 200:
with open(file_path, 'wb') as file:
file.write(file_response.content)
print(f"已下载: {file_name}")
else:
print(f"下载失败: {href}")
except:
print(f"下载失败: {href}")
else:
print(f"无法获取网页内容: {url}")总结
links_extractor.py 这把 30 行瑞士军刀,用三招“读文本、抓链接、写文件”帮你把散落各处的网址瞬间归队。
再加批量扫描或迷你窗口,它就从命令行小工具升级为效率神器。
下次老板再甩 txt,你只需双击脚本,喝杯水的功夫就交卷!
到此这篇关于python实现一键提取页面所有链接的文章就介绍到这了,更多相关python提取页面链接内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论