实际应用软件测试
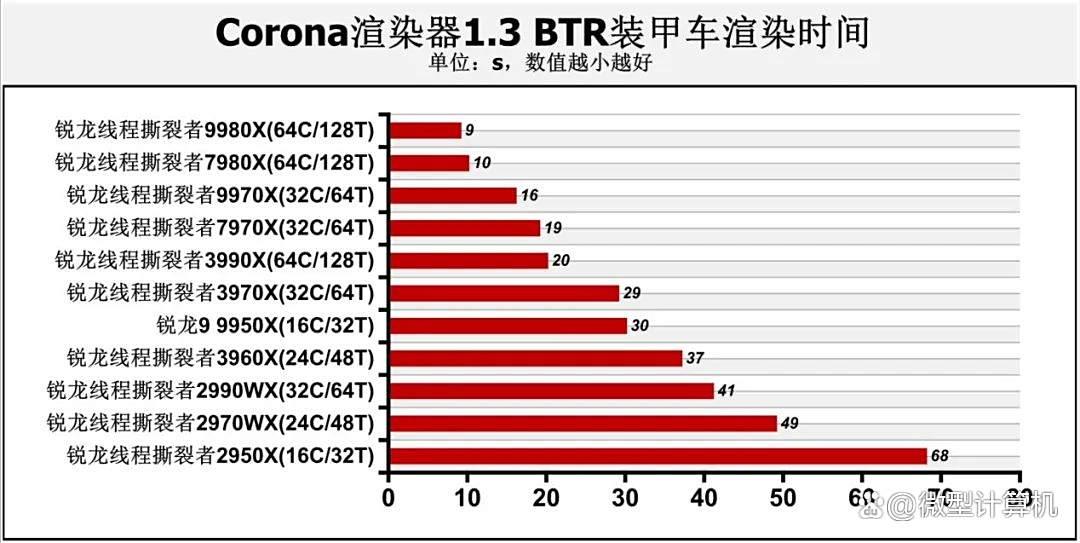
接下来我们还使用实际软件进行了测试,差距仍是清晰明了。首先从渲染性能来看,由于处理器渲染可以调用所有线程参与运算,所以锐龙线程撕裂者9980x可以轻松击败所有参测产品。在corona渲染器1.3渲染btr装甲车模型中,由于该软件也是长期没有更新,所以我们加入了以前的处理器测试数据进行对比。新一代锐龙线程撕裂者处理器的架构、核心数量优势显著。其中,锐龙线程撕裂者9980x仅需9秒就能完成任务,锐龙线程撕裂者7980x需要10秒,而锐龙线程撕裂者9970x的耗时则较锐龙线程撕裂者7970x少了3秒,仅16秒,比64核心的锐龙线程撕裂者3990x还少耗时4秒。至于锐龙9 9950x虽然耗时30秒,与锐龙线程撕裂者9000、锐龙线程撕裂者7000系列差距较大,但其成绩已经非常接近耗时29秒,采用32核心设计的锐龙线程撕裂者3970x,这也再次反映了处理器架构更新带来的大幅增益。
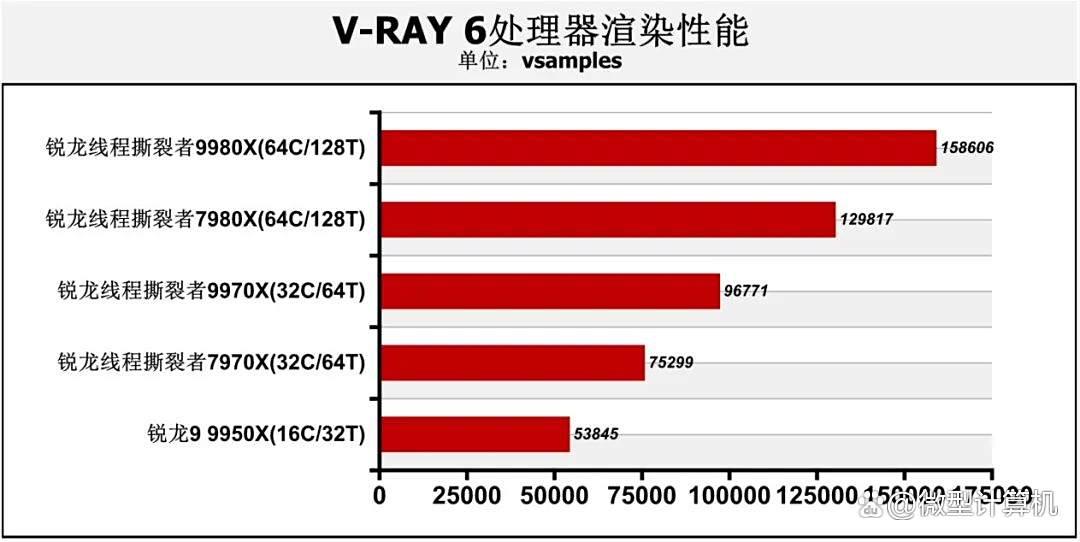
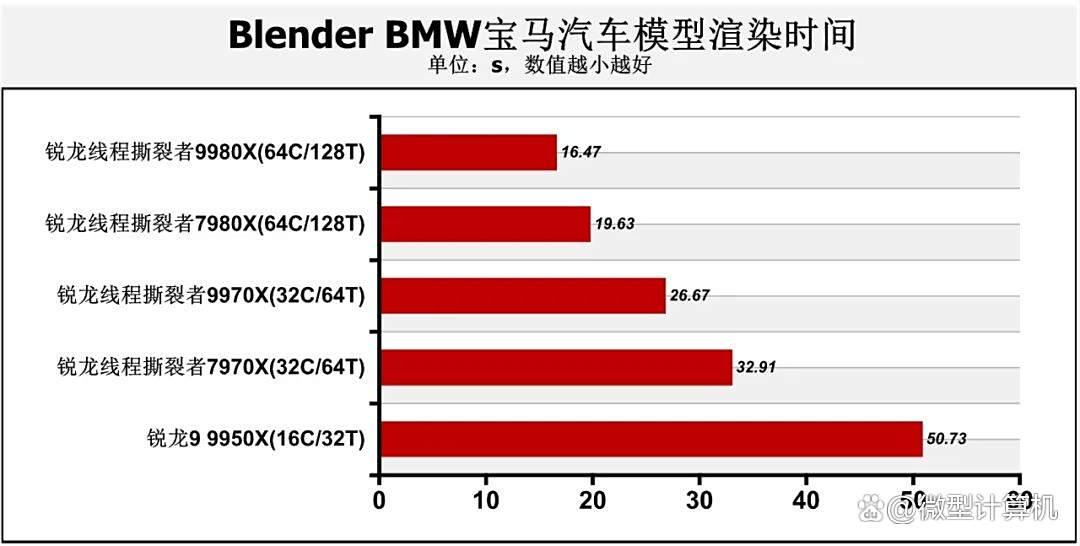
在v-ray渲染器测试中也有类似结果,锐龙线程撕裂者9980x的处理器渲染性能高达158606vsamples,比锐龙线程撕裂者7980x领先22.2%,而锐龙线程撕裂者9970x借助zen 5架构优势,其渲染性能相对锐龙线程撕裂者7970x也有多达28.5%的优势。在blender bmw宝马汽车模型渲染测试中,锐龙线程撕裂者9980x仅需16.47秒就能完成渲染任务,锐龙线程撕裂者7980x的耗时多了19.2%,锐龙线程撕裂者7970x的耗时也较线程撕裂者9970x多了23.4%,至于锐龙9 9950x,它比锐龙线程撕裂者7970x的耗时都多了54.1%,因此要想高效地完成渲染任务,用户只能选择锐龙线程撕裂者9000系列。
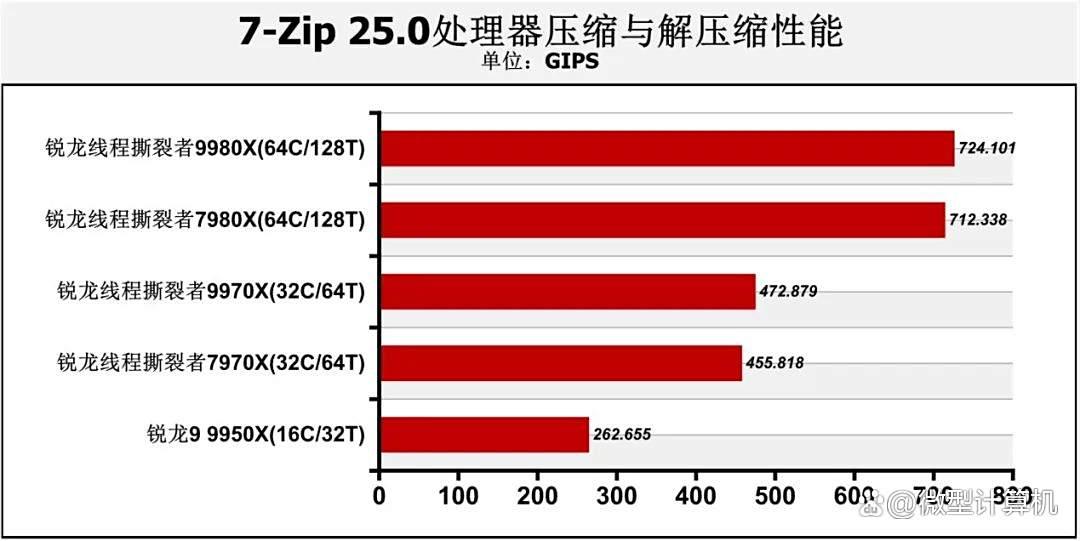
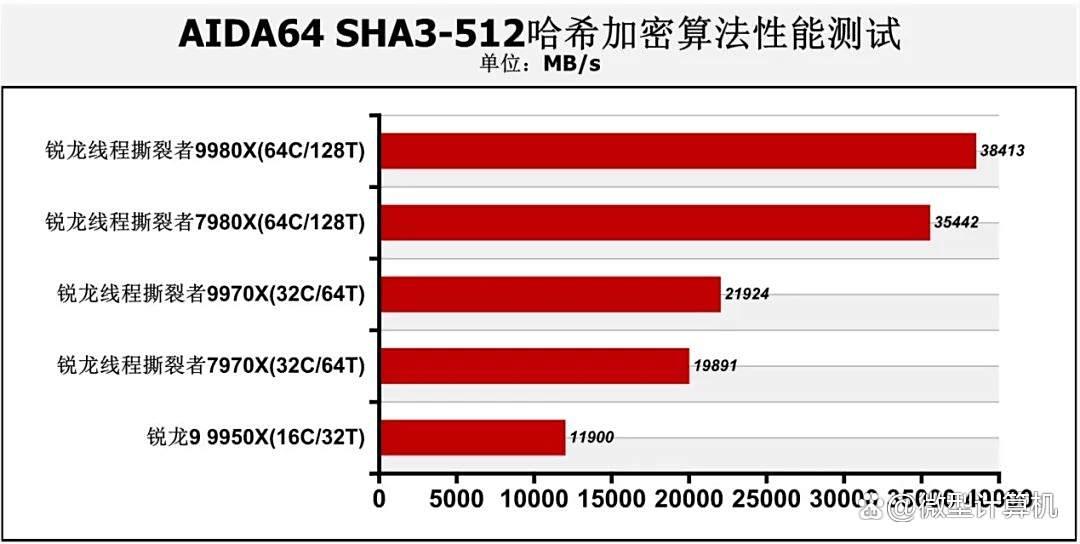
同时在7-zip 25.0处理器压缩与解压缩性能、aida64 fp64光线追踪性能与aida64 sha3-512哈希加密算法性能测试中也有类似结果。核心数量越多,架构越先进的处理器更具优势。因此锐龙线程撕裂者9980x、锐龙线程撕裂者9970x都轻松战胜了各自的对手,更适合完成以上类型的工作负载。

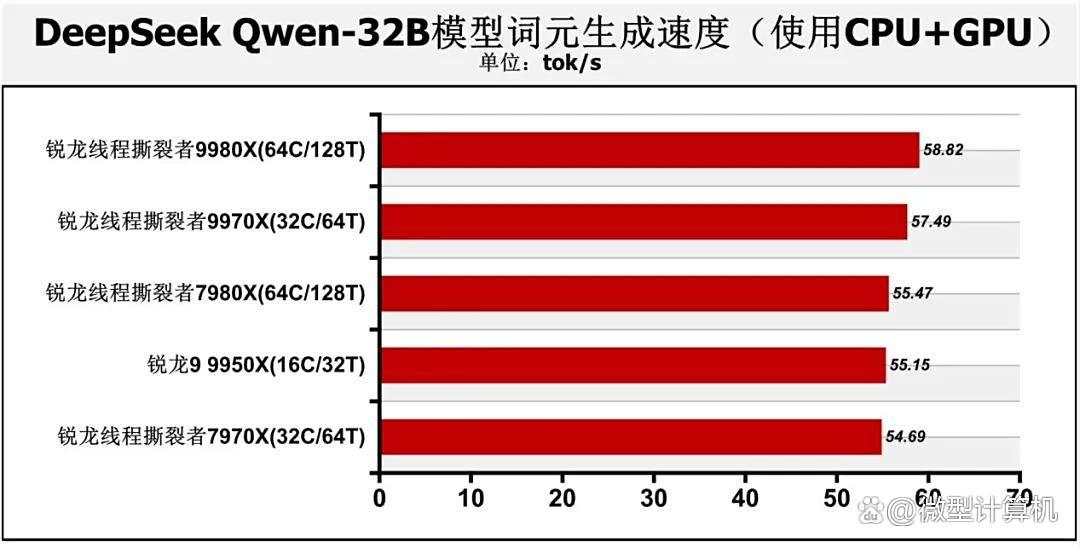
在deepseek qwen-32b模型ai大语言模型应用测试中,我们向ai提出了写一首14行英文诗的要求,我们将考察使用不同处理器时的词元生成速度,首个词元生成耗时。结果与specworkstation 4.0的ai与机器学习性能测试类似,锐龙线程撕裂者9980x、锐龙线程撕裂者9970x仍在测试中领先,不过两款处理器的区别不大。这还是因为在进行ai负载运算时,处理器不会调用太多cpu线程参与运算,因此锐龙线程撕裂者9980x与锐龙线程撕裂者9970x之间拉不开差距,锐龙线程撕裂者9980x只获得了小幅领先。另外在使用geforce rtx 5090 d显卡与处理器共同生成14行诗时,由于参与运算的主要是显卡,因此参测的5款处理器之间也不会拉开很大的差距,其词元生成速度最低也有54.69tok/s,锐龙线程撕裂者9980x的速度虽然最高,但其相对于最低速度的领先幅度只有7.55%。
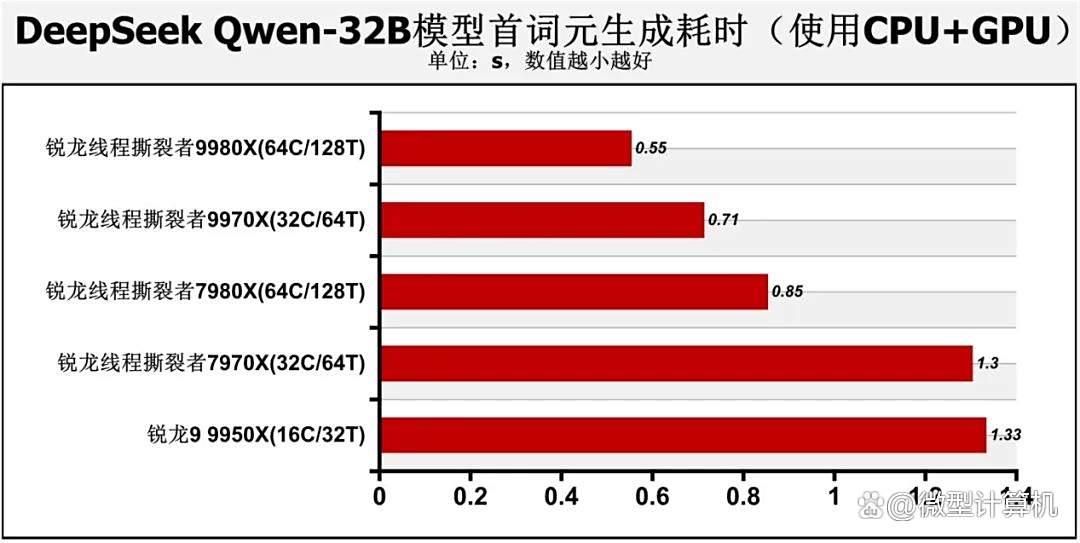
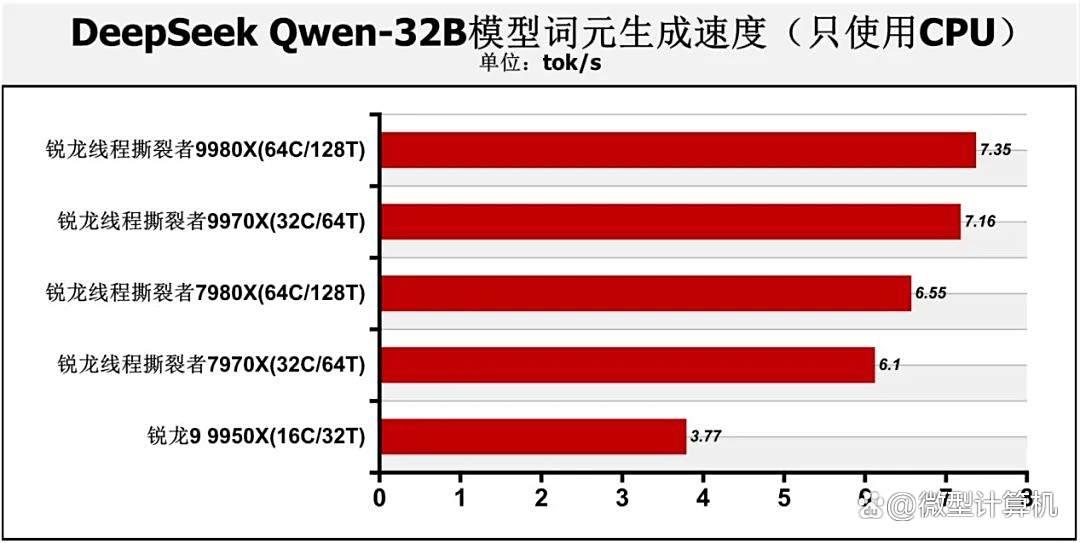
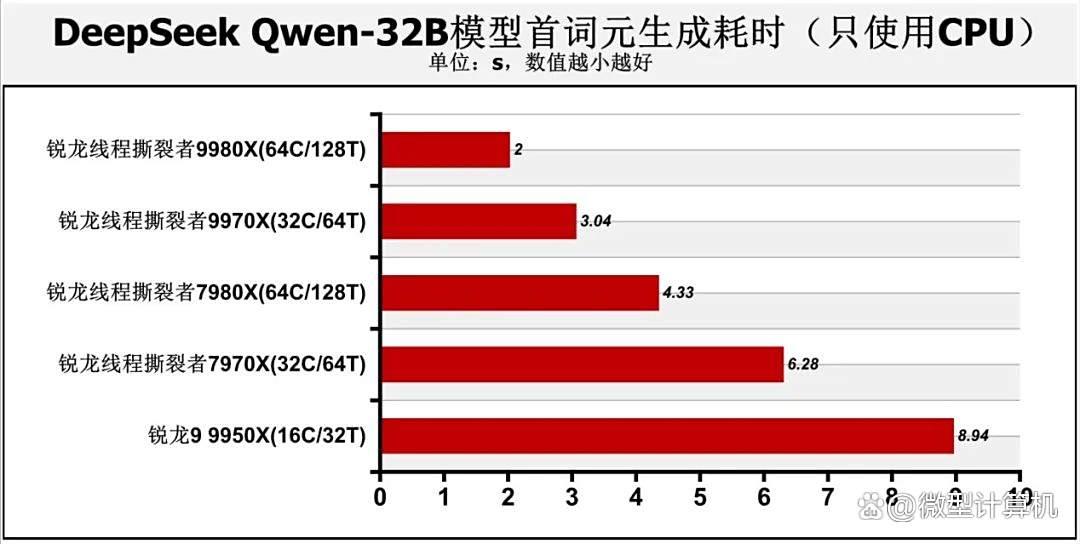
不过一旦关闭显卡加速,假设用户没有性能强劲的显卡,那么差距就能体现,锐龙线程撕裂者9980x与锐龙线程撕裂者9970x的处理器词元生成速度均可以达到7.1tok/s以上,首个词元生成时间只有2s~3.04s,而锐龙线程撕裂者7980x与锐龙线程撕裂者7970x的词元生成速度分别只有6.55、6.1tok/s,首个词元生成时间分别需耗时4.33s、6.28s。锐龙线程撕裂者9980x的词元生成速度相对于锐龙线程撕裂者7980x的词元生成速度领先了12.2%,锐龙线程撕裂者9970x的词元生成速度则领先锐龙线程撕裂者7970x达17.4%。至于锐龙9 9950x的处理器词元生成速度则只有3.77tok/s,首个词元生成耗时需8.94s,差距显著。因此用户如需要处理器算力参与ai运算,那么锐龙线程撕裂者9000系列处理器就是更好的选择。
在测试中,锐龙线程撕裂者9980x未能夺冠的唯一例外就是handbrake 4k h.264视频转1080p h.265视频测试。在这个测试中,锐龙线程撕裂者9970x的耗时最少,表现最佳。从任务管理器中我们可以找到答案,在这个测试中,软件甚至无法使64条cpu线程达到满载,因此工作频率更高的锐龙线程撕裂者9970x在测试中更有优势也就理所当然。当然,凭借zen 5架构优势,锐龙线程撕裂者9980x还是能轻松击败锐龙线程撕裂者7980x与锐龙线程撕裂者7970x两款上一代产品。

我们还在handbrake转码测试中对比了开启avx-512指令集加速后的转码速度。三款基于zen 5架构的处理器都获得了明显的加速效果,开启后,锐龙线程撕裂者9980x的转码耗时较未开启前少了8秒,锐龙线程撕裂者9970x的耗时少了7秒,锐龙9 9950x的耗时更大幅降低12秒。而锐龙线程撕裂者7980x、锐龙线程撕裂者7970x的avx-512指令集加速效果就明显要差一些,只减少了4秒,以至于在avx-512指令集加速状态下,锐龙线程撕裂者7970x的耗时比锐龙9 9950x还要多3秒。这也充分说明,zen 5处理器架构的avx-512指令集运算效率的确明显优于zen 4架构。

发表评论