1. 概述
xml(extensible markup language)中文译为可扩展标记语言,它是一种简单、灵活、易扩展的文本格式,它主要关注数据内容,常用来传送、存储数据。
当通过 xml 来传送数据时,自然会涉及到 xml 的解析工作,通常 python 可以通过如下三种方式来解析 xml:
dom
dom 方式会将整个 xml 读入内存,在内存中解析成一个树,通过对树的操作来操作 xml,该方式占用内存较大,解析速度较慢。sax
sax 方式逐行扫描 xml 文档,边扫描边解析,占用内存较小,速度较快,缺点是不能像 dom 方式那样长期留驻在内存,数据不是长久的,事件过后,若没保存数据,数据会丢失。elementtree
elementtree 方式几乎兼具了 dom 方式与 sax 方式的优点,占用内存较小、速度较快、使用也较为简单。
2. 写入
首先,我们通过 python 创建一个 xml 文档并向其中写入一些数据,实现代码如下所示:
from xml.etree import elementtree as et
import xml.dom.minidom as minidom
# 创建根节点
root = et.element('school')
names = ['张三', '李四']
genders = ['男', '女']
ages = ['20', '18']
# 添加子节点
student1 = et.subelement(root, 'student')
student2 = et.subelement(root, 'student')
et.subelement(student1, 'name').text = names[0]
et.subelement(student1, 'gender').text = genders[0]
et.subelement(student1, 'age').text = ages[0]
et.subelement(student2, 'name').text = names[1]
et.subelement(student2, 'gender').text = genders[1]
et.subelement(student2, 'age').text = ages[1]
# 将根目录转化为树行结构
tree = et.elementtree(root)
rough_str = et.tostring(root, 'utf-8')
# 格式化
reparsed = minidom.parsestring(rough_str)
new_str = reparsed.toprettyxml(indent='\t')
f = open('test.xml', 'w', encoding='utf-8')
# 保存
f.write(new_str)
f.close()看一下效果:
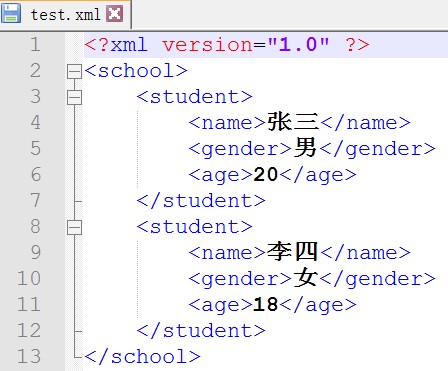
3. 解析
我们分别使用 dom、sax、elementtree 方式解析上面生成的 xml 文件。
3.1 dom 方式
看一下如何通过 dom 方式进行解析,实现代码如下所示:
from xml.dom.minidom import parse
# 读取文件
dom = parse('test.xml')
# 获取文档元素对象
elem = dom.documentelement
# 获取 student
stus = elem.getelementsbytagname('student')
for stu in stus:
# 获取标签中内容
name = stu.getelementsbytagname('name')[0].childnodes[0].nodevalue
gender = stu.getelementsbytagname('gender')[0].childnodes[0].nodevalue
age = stu.getelementsbytagname('age')[0].childnodes[0].nodevalue
print('name:', name, ', gender:', gender, ', age:', age)执行结果:
name: 张三 , gender: 男 , age: 20
name: 李四 , gender: 女 , age: 18
3.2 sax 方式
看一下如何通过 sax 方式进行解析,实现代码如下所示:
import xml.sax
class studenthandler(xml.sax.contenthandler):
def __init__(self):
self.name = ''
self.age = ''
self.gender = ''
# 元素开始调用
def startelement(self, tag, attributes):
self.currentdata = tag
# 元素结束调用
def endelement(self, tag):
if self.currentdata == 'name':
print('name:', self.name)
elif self.currentdata == 'gender':
print('gender:', self.gender)
elif self.currentdata == 'age':
print('age:', self.age)
self.currentdata = ''
# 读取字符时调用
def characters(self, content):
if self.currentdata == 'name':
self.name = content
elif self.currentdata == 'gender':
self.gender = content
elif self.currentdata == 'age':
self.age = content
if (__name__ == "__main__"):
# 创建 xmlreader
parser = xml.sax.make_parser()
# 关闭命名空间
parser.setfeature(xml.sax.handler.feature_namespaces, 0)
# 重写 contexthandler
handler = studenthandler()
parser.setcontenthandler(handler)
parser.parse('test.xml')执行结果:
name: 张三
gender: 男
age: 20
name: 李四
gender: 女
age: 18
3.3 elementtree 方式
看一下如何通过 elementtree 方式进行解析,实现代码如下所示:
import xml.etree.elementtree as et
tree = et.parse('test.xml')
# 根节点
root = tree.getroot()
for stu in root:
print('name:', stu[0].text, ', gender:', stu[1].text, ', age:', stu[2].text)执行结果:
name: 张三 , gender: 男 , age: 20
name: 李四 , gender: 女 , age: 18
到此这篇关于python xml 基本操作的文章就介绍到这了,更多相关python xml 操作内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论