这个是我在上网找资料的时候,发现下载资料pdf居然要付费,然后我查看网页源代码发现它网页的资料都是pdf的png格式,每一个图片都是写在一个div标签里面的,手动操作肯定比较复杂,(说明,博主我是学c++的,对python不是很懂),我知道python肯定可以实现这事,于是马上学习了一波。
一、需求分析
网页的页面源代码如下图所示,它的每一个<div>标签里面的img的url就是资料的内容,可以直接通过url来打开资料图片,然后“另存为”即可,但是手动操作太麻烦了(当然有同学说直接用爬虫,也可以哈,但是我没用),要是能自动化批量给它一个全是url的文本文件,让python帮我逐一打开然后按照顺序命好名称逐一保存到本地文件就好了。
但是网页源码是html格式的,手动提取网页源码的url也太慢了,所以我们还需要一个python函数来帮我们从给定的html的文本文件里面提取出url按行保存到指定文本文件里。

二、从html中提取可用url
1、先在项目目录下新建一个文本文件命名为html.txt。
2、将网页源码中所需要的地方复制到html.txt中。如下图所示
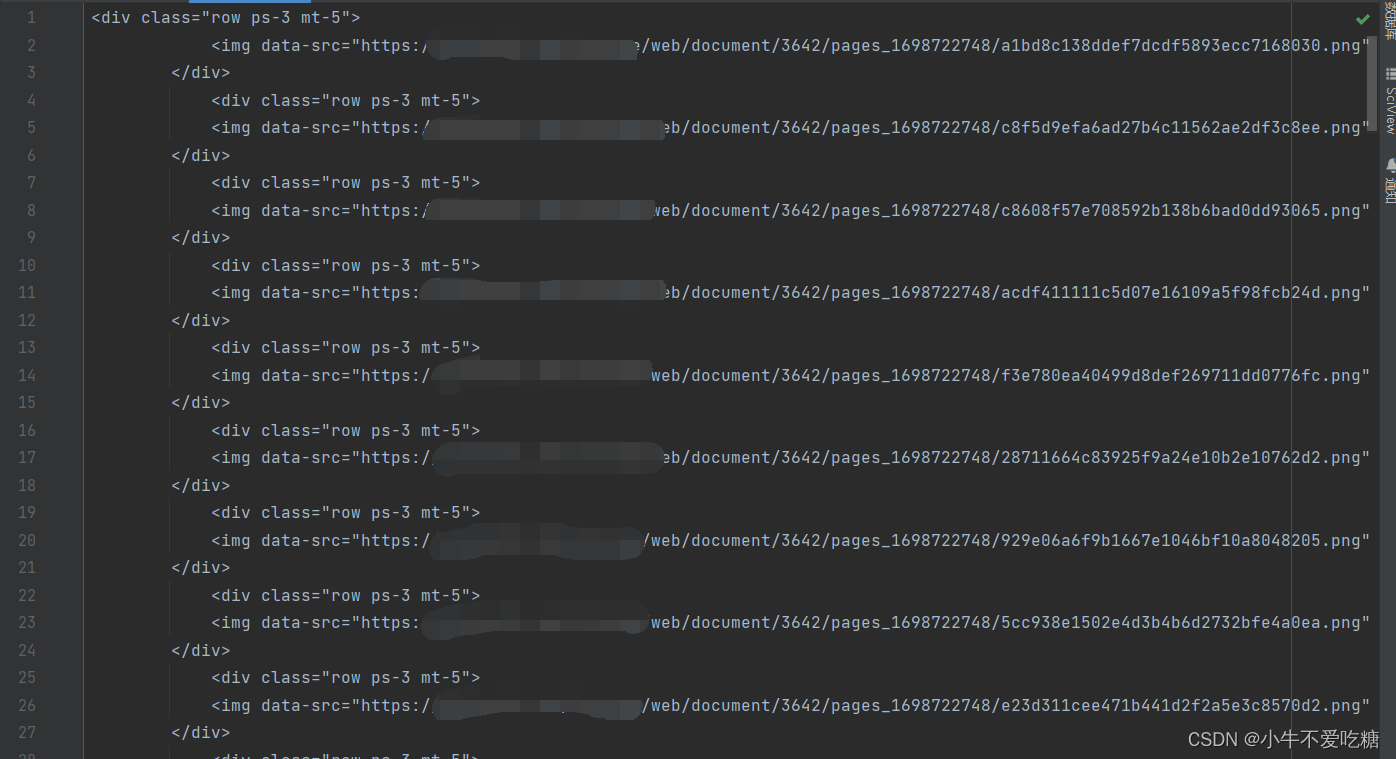
3、新建一个py文件,在里面写具体实现,通过观察发现所有目标url均以png结尾,可以使用正则表达式匹配,取出目标url 。然后保存到指定的文本文件http.txt中。代码如下:
import re
# 打开html文件
with open('html.txt', 'r') as file:
html_content = file.read()
# 使用正则表达式提取url
pattern = r'<img\s+data-src="([^"]+\.png)"'
urls = re.findall(pattern, html_content)
# 将url保存到http.txt文件中
with open('http.txt', 'w') as file:
for url in urls:
file.write(url + '\n')
4、执行完成后我们就得到了全是目标url的一个文本文件了
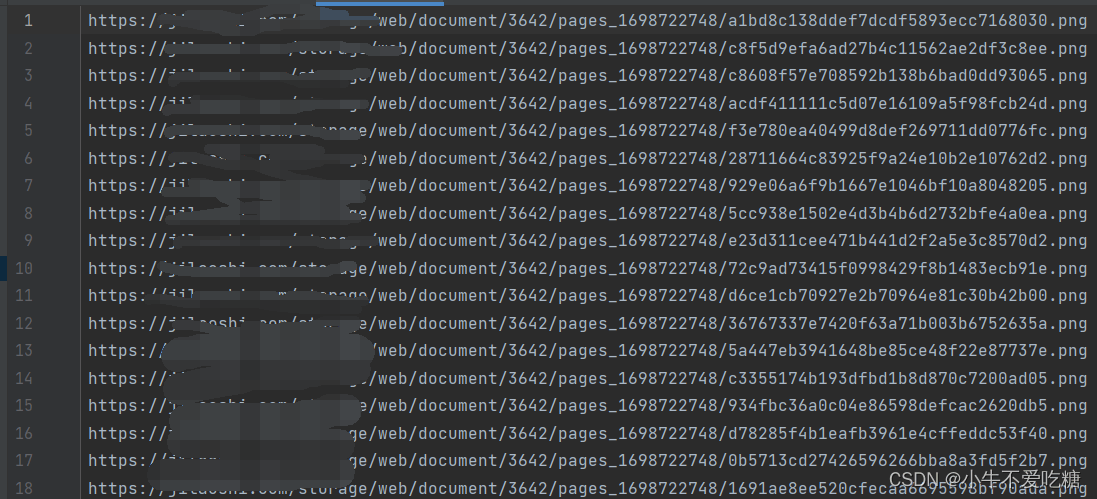
三、批量执行url按序保存到本地
1、打开http.txt文件,按行取出url,打开url判断是否能正常打开,不需要执行浏览器打开这一操作,只需要得到返回值即可。
2、需要url的顺序和保存的png一一对应,比如第一行url对应图png1,所以考虑按序命名,设置计数器。根据计算器生成png文件的名称。
3、保存到指定文件夹,且命名好。
import requests
# 创建一个计数器
count = 1
# 打开网址文件
with open('http.txt', 'r') as file:
# 逐行读取网址
for line in file:
url = line.strip() # 去除行尾的换行符和空格
# 下载图片并保存到本地
response = requests.get(url)
if response.status_code == 200:
# 生成图片文件名
filename = f'{count}.jpg'
# 保存到桌面文件夹
save_path = f'f:/桌面文件夹/tupian/{filename}'
with open(save_path, 'wb') as image_file:
image_file.write(response.content)
print(f'saved image: {save_path}')
# 增加计数器
count += 1
else:
print(f'failed to download image from {url}')
4、运行代码,查看结果。如图

到此这篇关于python批量处理url并提取内容且按序保存到本地的文章就介绍到这了,更多相关python处理url并提取内容内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论