mybatis 作为一款灵活的持久层框架,除了基础的 crud 操作,还提供了连接池管理、动态 sql 以及多表关联查询等高级特性。本文将从连接池原理出发,深入讲解动态 sql 的常用标签,并通过实例演示一对多、多对多等复杂关联查询的实现,帮助你掌握 mybatis 的进阶用法。
一、mybatis 连接池:提升数据库交互性能
连接池是存储数据库连接的容器,它的核心作用是避免频繁创建和关闭连接,从而减少资源消耗、提高程序响应速度。在 mybatis 中,连接池的配置通过datasource标签的type属性实现,支持三种类型的连接池:
1. 连接池类型详解
pooled:使用 mybatis 内置的连接池
mybatis 会维护一个连接池,当需要连接时从池中获取,使用完毕后归还给池,避免频繁创建连接。适用于高并发场景,是开发中最常用的类型。配置示例:
<datasource type="pooled">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</datasource>unpooled:不使用连接池
每次执行 sql 时都会创建新的连接,使用后直接关闭。适用于低并发场景,性能较差,一般仅用于简单测试。
配置示例:
<datasource type="unpooled">
<!-- 同pooled的属性配置 -->
</datasource>jndi:依赖容器的连接池
由 web 容器(如 tomcat)提供连接池管理,mybatis 仅负责从容器中获取连接。适用于java ee 环境,需在容器中提前配置连接池。配置示例:
<datasource type="jndi">
<property name="data_source" value="java:comp/env/jdbc/mybatis_db"/>
</datasource>2. 连接池的优势
- 资源复用:连接池中的连接可重复使用,减少创建连接的开销;
- 响应速度:提前创建连接,避免 sql 执行时的连接创建延迟;
- 并发控制:通过最大连接数限制,防止数据库因连接过多而崩溃。
二、动态 sql:灵活拼接 sql 语句
在实际开发中,查询条件往往是动态变化的(如多条件筛选、批量操作等)。mybatis 的动态 sql 标签可以优雅地解决 sql 语句拼接问题,避免手动拼接导致的语法错误和 sql 注入风险。
1. <if>标签:条件判断
<if>标签用于根据参数值动态生成 sql 片段,常用来处理多条件查询。
示例场景:根据用户名和性别查询用户(参数非空时才添加条件)。
usermapper 接口:
public interface usermapper {
// 条件查询用户
list<user> findbywhere(user user);
}usermapper.xml 配置:
<select id="findbywhere" parametertype="user" resulttype="user">
select * from user
<where>
<!-- 当username非空且非空字符串时,添加条件 -->
<if test="username != null and username != ''">
and username like #{username}
</if>
<!-- 当sex非空且非空字符串时,添加条件 -->
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
</where>
</select>测试代码:
@test
public void testfindbywhere() {
user user = new user();
user.setusername("%zz%"); // 模糊查询包含"zz"的用户名
user.setsex("m");
list<user> list = usermapper.findbywhere(user);
// 遍历结果...
}说明:test属性中的表达式用于判断参数是否有效,where标签会自动处理多余的and或or,避免 sql 语法错误。

2. <foreach>标签:遍历集合
<foreach>标签用于遍历集合或数组,常用来处理in查询或批量操作。
场景 1:查询 id 在指定集合中的用户(in查询)
user 实体类:添加存储 id 集合的属性
public class user {
private list<integer> ids; // 存储多个id
// 省略getter、setter
}usermapper 接口:
list<user> findbyids(user user);
usermapper.xml 配置:
<select id="findbyids" parametertype="user" resulttype="user">
select * from user
<where>
<!--
collection:集合属性名(此处为ids)
open:sql片段开头
close:sql片段结尾
separator:元素分隔符
item:遍历的元素别名
-->
<foreach collection="ids" open="id in (" separator="," close=")" item="id">
#{id}
</foreach>
</where>
</select>测试代码:
@test
public void testfindbyids() {
user user = new user();
list<integer> ids = new arraylist<>();
ids.add(1);
ids.add(2);
ids.add(3);
user.setids(ids);
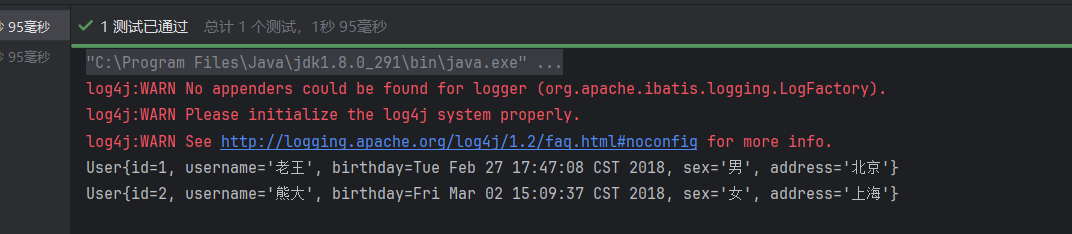
list<user> list = usermapper.findbyids(user); // 查询id为1、2、3的用户
}
场景 2:批量查询(or条件)
如需生成id = 1 or id = 2 or id = 3形式的 sql,只需调整<foreach>的open和separator:
<foreach collection="ids" open="id = " separator="or id = " item="id">
#{id}
</foreach>3. <sql>与<include>标签:sql 片段复用
对于频繁使用的 sql 片段(如查询字段、表名等),可以用<sql>标签定义,再通过<include>标签引用,减少代码冗余。
示例:复用查询用户的 sql 片段。
- usermapper.xml 配置:
<!-- 定义sql片段 -->
<sql id="usercolumns">
id, username, birthday, sex, address
</sql>
<!-- 引用sql片段 -->
<select id="findall" resulttype="user">
select <include refid="usercolumns"/> from user
</select>说明:id为片段唯一标识,refid指定要引用的片段 id,适用于多表查询中重复的字段列表。
三、一对多查询:用户与账户的关联
在实际业务中,表之间往往存在关联关系(如用户与账户:一个用户可以有多个账户)。mybatis 通过<collection>标签处理一对多关联查询。
1. 表结构与实体类设计
- 用户表(user):存储用户基本信息(id、username 等);
- 账户表(account):存储账户信息,通过
uid关联用户表(多对一关系)。
实体类设计:
account 类(多对一:一个账户属于一个用户):
public class account implements serializable {
private integer id;
private integer uid; // 关联用户id
private double money;
// 关联的用户对象
private user user;
// 省略getter、setter
}user 类(一对多:一个用户有多个账户):
public class user implements serializable {
private integer id;
private string username;
// 关联的账户列表
private list<account> accounts;
// 省略getter、setter
}2. 多对一查询(账户关联用户)
查询所有账户,并关联查询所属用户的信息。
accountmapper 接口:
public interface accountmapper {
list<account> findall();
}accountmapper.xml 配置:
<select id="findall" resultmap="accountmap">
<!-- 关联查询账户和用户 -->
select a.*, u.username, u.address
from account a
left join user u on a.uid = u.id
</select>
<!-- 定义结果映射 -->
<resultmap id="accountmap" type="account">
<id property="id" column="id"/>
<result property="uid" column="uid"/>
<result property="money" column="money"/>
<!-- 关联用户对象(多对一) -->
<association property="user" javatype="user">
<result property="username" column="username"/>
<result property="address" column="address"/>
</association>
</resultmap>说明:<association>标签用于映射关联的单个对象,javatype指定对象类型。
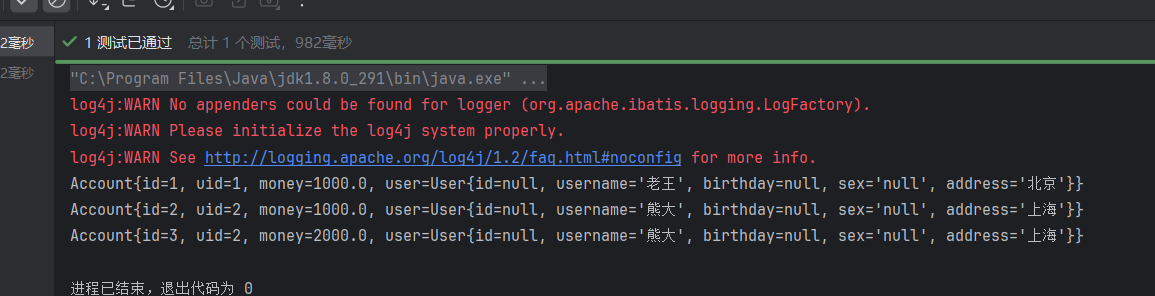
3. 一对多查询(用户关联账户)
查询所有用户,并关联查询其名下的所有账户。
usermapper 接口:
public interface usermapper {
// 查询用户及关联的账户
list<user> findonetomany();
}usermapper.xml 配置:
<select id="findonetomany" resultmap="useraccountmap">
select u.*, a.id as aid, a.money
from user u
left join account a on u.id = a.uid
</select>
<resultmap id="useraccountmap" type="user">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!-- 关联账户列表(一对多) -->
<collection property="accounts" oftype="account">
<id property="id" column="aid"/> <!-- 注意别名避免与用户id冲突 -->
<result property="money" column="money"/>
</collection>
</resultmap>说明:<collection>标签用于映射关联的集合对象,oftype指定集合中元素的类型。

四、多对多查询:用户与角色的关联
多对多关系需要通过中间表实现(如用户与角色:一个用户可拥有多个角色,一个角色可分配给多个用户,通过user_role表关联)。
1. 表结构与实体类设计
- 角色表(role):存储角色信息(id、role_name 等);
- 中间表(user_role):通过
uid和rid关联用户表和角色表。
实体类设计:
account 类(多对一:一个账户属于一个用户):
public class account implements serializable {
private integer id;
private integer uid; // 关联用户id
private double money;
// 关联的用户对象
private user user;
// 省略getter、setter
}- role 类(多对多:一个角色包含多个用户):
public class user implements serializable {
private integer id;
private string username;
// 关联的账户列表
private list<account> accounts;
// 省略getter、setter
}2. 多对多查询实现
查询所有角色,并关联查询拥有该角色的用户信息。
roledao 接口:
public interface roledao {
list<role> findall();
}roledao.xml 配置:
<select id="findall" resultmap="rolemap">
select r.*, u.id as user_id, u.username
from role r
join user_role ur on r.id = ur.rid
join user u on u.id = ur.uid
</select>
<resultmap type="role" id="rolemap">
<id property="id" column="id"/>
<result property="role_name" column="role_name"/>
<result property="role_desc" column="role_desc"/>
<!-- 关联用户列表(多对多) -->
<collection property="users" oftype="user">
<id property="id" column="user_id"/> <!-- 别名避免与角色id冲突 -->
<result property="username" column="username"/>
</collection>
</resultmap>测试代码:
@test
public void testfindallroles() {
list<role> roles = roledao.findall();
for (role role : roles) {
system.out.println("角色:" + role.getrole_name());
system.out.println("关联用户:" + role.getusers());
}
}说明:多对多查询本质是双向的一对多查询,通过中间表建立关联,同样使用<collection>标签映射集合对象。

五、mybatis 延迟加载策略
1. 延迟加载的概念
延迟加载(lazy loading)是一种数据库查询优化策略,其核心思想是:仅在需要使用关联数据时才进行实际查询。与立即加载(eager loading)相比,延迟加载避免了不必要的数据库访问,提高了系统性能。
对比示例(一对多关系):
- 立即加载:查询用户时,同时加载该用户的所有账户信息(即使后续可能不使用账户数据)。
- 延迟加载:查询用户时,仅加载用户基本信息;当程序调用
user.getaccounts()时,才会触发账户数据的查询。
2. 应用场景选择
| 场景 | 加载策略 | 示例 |
|---|---|---|
| 多对一关系 | 立即加载 | 查询账户时,同时加载所属用户 |
| 一对多 / 多对多 | 延迟加载 | 查询用户时,暂不加载账户信息 |
3. 多对一延迟加载实现
(1)配置文件示例
<!-- accountmapper.xml -->
<resultmap type="account" id="accountmap">
<id column="id" property="id"/>
<result column="uid" property="uid"/>
<result column="money" property="money"/>
<!-- 配置延迟加载:通过select属性指定关联查询方法 -->
<association property="user" javatype="user"
select="com.qcbyjy.mapper.usermapper.findbyid"
column="uid">
<id column="id" property="id"/>
<result column="username" property="username"/>
</association>
</resultmap>(2)核心配置参数
<!-- sqlmapconfig.xml -->
<settings>
<!-- 开启延迟加载功能 -->
<setting name="lazyloadingenabled" value="true"/>
<!-- 禁用积极加载(默认false,按需加载) -->
<setting name="aggressivelazyloading" value="false"/>
</settings>测试方法
@test
public void testfindall1() throws ioexception {
// 先加载主配置文件,加载到输入流中
inputstream inputstream = resources.getresourceasstream("sqlmapconfig.xml");
// 创建sqlsessionfactory对象,创建sqlsession对象
sqlsessionfactory factory = new sqlsessionfactorybuilder().build(inputstream);
// 创建sqlsession对象
sqlsession session = factory.opensession();
// 获取代理对象
accountmapper mapper = session.getmapper(accountmapper.class);
// 1. 查询主对象(账户)
list<account> accounts = mapper.findall();
system.out.println("===== 主查询已执行 =====");
// 2. 遍历账户,但不访问关联的用户
for (account account : accounts) {
system.out.println("账户id:" + account.getid() + ",金额:" + account.getmoney());
}
system.out.println("===== 未访问关联对象 =====");
// 3. 首次访问关联的用户
for (account account : accounts) {
system.out.println("===== 开始访问用户 =====");
system.out.println("用户名:" + account.getuser().getusername()); // 触发懒加载
system.out.println("===== 访问用户结束 =====");
}
// 关闭资源
session.close();
inputstream.close();
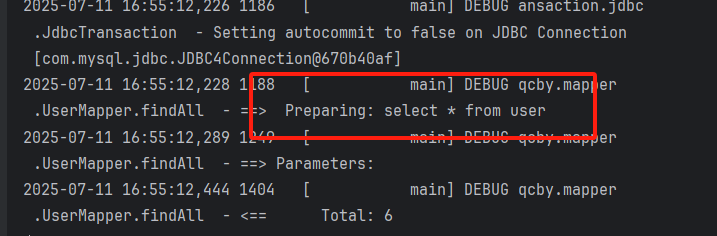
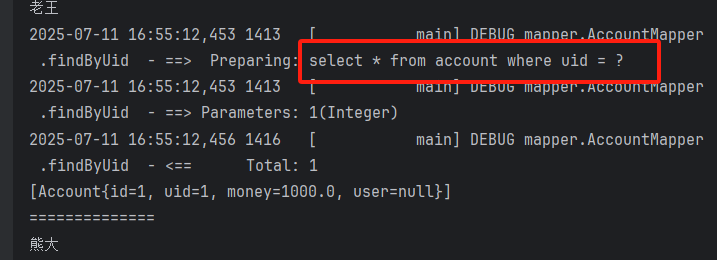
}执行findall()时,日志仅输出账户表的查询 sql 。遍历账户但不访问用户时,无新的 sql 输出:
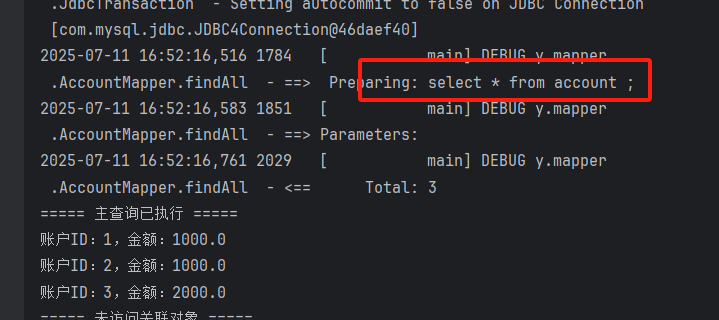
首次访问account.getuser()时,日志输出用户表的查询 sql(按需加载)
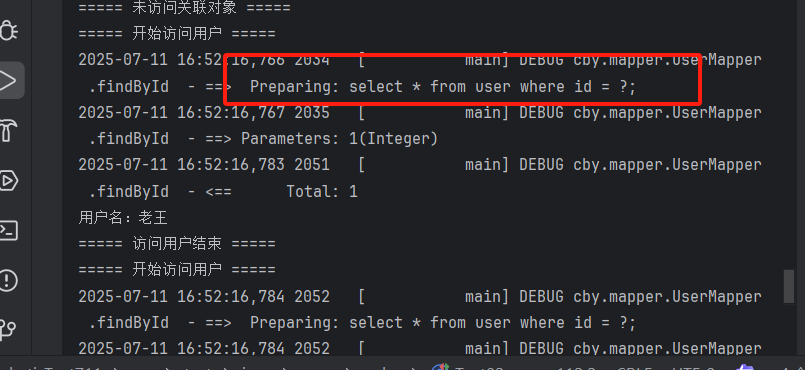
(3)工作原理
当执行account.getuser()时,mybatis 会:
- 检查
lazyloadingenabled是否为true; - 通过
select属性调用usermapper.findbyid(uid)方法; - 将结果封装到
account.user属性中。
4. 一对多延迟加载实现
(1)配置文件示例
<!-- usermapper.xml -->
<resultmap type="user" id="usermap">
<id column="id" property="id"/>
<result column="username" property="username"/>
<!-- 配置延迟加载:集合属性 -->
<collection property="accounts" oftype="account"
select="com.qcbyjy.mapper.accountmapper.findbyuid"
column="id">
<id column="id" property="id"/>
<result column="money" property="money"/>
</collection>
</resultmap>(2)延迟加载触发时机
list<user> users = usermapper.findall();
for (user user : users) {
// 调用getaccounts()时触发延迟查询
system.out.println(user.getaccounts());
}测试代码:
@test
public void testfindallq() throws exception {
// 调用方法
list<user> list = mapper.findall();
for (user user : list) {
system.out.println(user.getusername());
system.out.println(user.getaccounts());
system.out.println("==============");
}
}
5. 延迟加载注意事项
- n+1 查询问题:延迟加载可能导致 n+1 查询(主查询 1 次,关联查询 n 次),需结合二级缓存优化。
- session 生命周期:延迟加载需确保关联查询时
sqlsession未关闭(可通过opensession(true)保持会话)。 - 序列化问题:延迟加载的对象在序列化时可能丢失代理状态,需通过
<setting name="serializationfactory" value="..."/>配置。
七、mybatis 缓存机制
1. 缓存的基本概念
缓存是一种内存临时存储技术,用于减少数据库访问次数,提高系统响应速度。适合缓存的数据特点:
- 频繁查询但很少修改;
- 数据一致性要求不高;
- 数据量适中且访问频率高。
2. 一级缓存(sqlsession 级缓存)
(1)缓存原理
- 作用域:每个
sqlsession独享一个缓存实例; - 存储结构:底层使用
perpetualcache(基于hashmap实现); - 生命周期:与
sqlsession一致,session.close()后缓存销毁。
(2)缓存验证示例
@test
public void testfirstlevelcache() {
try (sqlsession session = sqlsessionfactory.opensession()) {
usermapper mapper = session.getmapper(usermapper.class);
// 第一次查询:触发sql
user user1 = mapper.findbyid(1);
// 第二次查询:命中缓存
user user2 = mapper.findbyid(1);
system.out.println(user1 == user2); // 输出true(同一对象)
}
}

(3)缓存失效场景
以下操作会导致一级缓存清空:
session.clearcache():手动清空缓存;session.commit()/session.rollback():事务提交或回滚;- 执行
insert/update/delete操作(任何数据变更)。
3. 一级缓存源码分析
核心源码位于baseexecutor类:
// baseexecutor.java
@override
public <e> list<e> query(mappedstatement ms, object parameter, rowbounds rowbounds, resulthandler resulthandler) throws sqlexception {
boundsql boundsql = ms.getboundsql(parameter);
// 1. 创建缓存key
cachekey key = createcachekey(ms, parameter, rowbounds, boundsql);
// 2. 查询一级缓存
return query(ms, parameter, rowbounds, resulthandler, key, boundsql);
}
@override
public <e> list<e> query(mappedstatement ms, object parameter, rowbounds rowbounds, resulthandler resulthandler, cachekey key, boundsql boundsql) throws sqlexception {
// 从本地缓存中获取
list<e> list = localcache.getobject(key);
if (list != null) {
// 缓存命中
handlelocallycachedoutputparameters(ms, key, parameter, boundsql);
return list;
} else {
// 缓存未命中,查询数据库
return queryfromdatabase(ms, parameter, rowbounds, resulthandler, key, boundsql);
}
}4. 一级缓存的应用建议
- 优势:无需额外配置,自动生效,适用于单次会话内的重复查询;
- 局限:无法跨
sqlsession共享,对长事务可能导致数据不一致; - 最佳实践:
- 避免在同一
sqlsession内进行重复查询; - 及时提交事务或关闭
sqlsession以释放缓存资源。
- 避免在同一
八、延迟加载与一级缓存的协同工作
当延迟加载与一级缓存结合时,需注意:
- 关联查询缓存:延迟加载的关联对象(如
user.getaccounts())会被存入一级缓存; - 会话隔离:不同
sqlsession的延迟加载结果相互独立; - 数据一致性:若主对象已缓存,关联对象的变更可能无法实时反映。
mysql缓存存的是语句,稍有修改就会更新缓存。一级缓存,输出的对象是同一个,二级缓存输出不同是因为通过序列化组装了两
一、一级缓存(sqlsession 级缓存)—— 同一个对象实例
1. 缓存本质与作用范围
一级缓存是 sqlsession 私有 的本地缓存,mybatis 默认开启。在同一个 sqlsession 内,只要查询条件、sql 语句相同,mybatis 会直接从缓存取结果,不会重复访问数据库。
2. “输出对象是同一个” 的原因
- 当执行查询时,mybatis 会先检查一级缓存:若命中缓存,直接返回 缓存中存储的对象引用 。
- 也就是说,多次查询拿到的是同一个 java 对象实例(jvm 中同一个内存地址的对象 )。例如:
try (sqlsession session = sqlsessionfactory.opensession()) {
usermapper mapper = session.getmapper(usermapper.class);
// 第一次查询,从数据库加载,存入一级缓存
user user1 = mapper.getuserbyid(1);
// 第二次查询,命中一级缓存,直接返回 user1 的引用
user user2 = mapper.getuserbyid(1);
system.out.println(user1 == user2); // 输出 true,是同一个对象实例
}
3. 缓存失效场景
当执行 update、insert、delete、commit、close 等操作时,一级缓存会被清空 。后续查询会重新从数据库加载数据,存入新的对象实例到缓存。
二、二级缓存(mapper 级缓存)—— 不同对象实例(因序列化 / 反序列化)
1. 缓存本质与作用范围
二级缓存是 mapper 作用域 的缓存,需手动开启(在 mapper xml 或注解中配置 )。它可以在多个 sqlsession 间共享,底层通常依赖序列化 / 反序列化机制存储数据 。
2. “输出不同对象” 的原因
- 二级缓存存储的是 对象的序列化数据 (如 java 对象先序列化为字节流,再存入缓存 )。
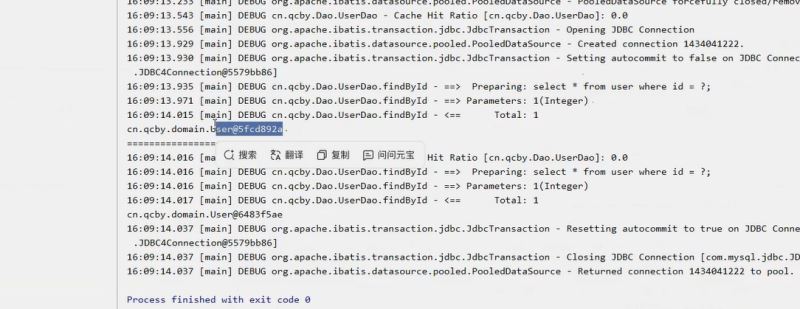
- 当不同 sqlsession 查询命中二级缓存时,mybatis 会 反序列化 缓存中的字节流,重新生成一个新的 java 对象实例 。例如:
// 开启二级缓存后,不同 sqlsession 测试
try (sqlsession session1 = sqlsessionfactory.opensession()) {
usermapper mapper1 = session1.getmapper(usermapper.class);
user user1 = mapper1.getuserbyid(1);
session1.commit(); // 提交后,数据可能同步到二级缓存(取决于配置)
}
try (sqlsession session2 = sqlsessionfactory.opensession()) {
usermapper mapper2 = session2.getmapper(usermapper.class);
user user2 = mapper2.getuserbyid(1); // 命中二级缓存,反序列化生成新对象
system.out.println(user1 == user2); // 输出 false,是不同对象实例
}
3. 二级缓存的核心特点
- 跨 sqlsession 共享:多个 sqlsession 可共用 mapper 级的缓存数据;
- 序列化存储:缓存数据需实现
serializable接口,存储和读取时会经历序列化 / 反序列化,因此每次命中缓存会生成新对象; - 缓存策略灵活:可配置
eviction(回收策略,如 lru、fifo )、flushinterval(刷新间隔 )、readonly(是否只读 )等。
三、一、二级缓存的核心差异对比
| 对比项 | 一级缓存 | 二级缓存 |
|---|---|---|
| 作用范围 | sqlsession 私有 | mapper 作用域(跨 sqlsession 共享) |
| 对象实例 | 同一对象引用 | 反序列化生成新对象 |
| 开启方式 | 默认开启 | 需手动配置(<cache> 标签或注解) |
| 存储机制 | 直接存对象引用 | 存序列化后的字节流 |
| 数据一致性 | 依赖 sqlsession 内操作,易维护 | 需注意多表关联、更新同步问题 |
四、实际开发中的注意事项
一级缓存的 “隐式风险”:
若在同一个 sqlsession 内,先查询再更新数据,由于一级缓存未及时清理(需手动 commit/close 触发 ),可能拿到旧数据。建议在增删改后,及时 commit 或 close sqlsession,保证缓存与数据库一致。二级缓存的 “使用前提”:
启用二级缓存时,实体类必须实现serializable接口(否则序列化报错 );同时,若涉及多表关联查询,需注意缓存的更新策略(比如某张表数据变化后,关联的 mapper 缓存需及时刷新 )。缓存的合理选择:
- 一级缓存适合短生命周期的 sqlsession(如单次请求内的多次查询 );
- 二级缓存适合查询频率高、数据变化少的场景(如系统字典表 ),但需谨慎处理数据更新后的缓存同步。
简单来说,一级缓存是 “同一个对象复用”,二级缓存是 “序列化后重新组装对象”,这种差异由它们的作用范围和存储机制决定。开发中根据业务场景合理利用缓存,既能提升性能,又能避免数据一致性问题~ 若你在实际配置或调试缓存时遇到具体问题(比如二级缓存不生效、序列化报错 ),可以接着展开说场景帮你分析 。
到此这篇关于mybatis连接池、动态 sql 与多表关联查询的文章就介绍到这了,更多相关mybatis多表关联查询内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论