前言
作为java开发者,日常开发中经常会遇到数据拷贝的需求。最近在面试中也有被问到一次大文件拷贝,抽空专门总结一下,从基础概念到实战技巧,配合流程图,让原理和流程一目了然~
一、浅拷贝vs深拷贝
一开始做spring项目时,就被浅拷贝坑过。当时想复制一个对象,结果改了新对象的属性,老对象也跟着变了。后来才知道,这就是浅拷贝的“锅”。
浅拷贝就像拍证件照,照片上的人看着和你一模一样,但本质上还是两张纸。java里的浅拷贝只会复制对象的基本属性,遇到引用类型(比如自定义类),就直接把地址抄过来。所以你改新对象里的引用属性,老对象也会跟着遭殃。
深拷贝就靠谱多了,它会把对象里里外外都复制一遍,就像克隆人,新对象和老对象完全独立。虽然麻烦点,但胜在安全,适合处理复杂对象。
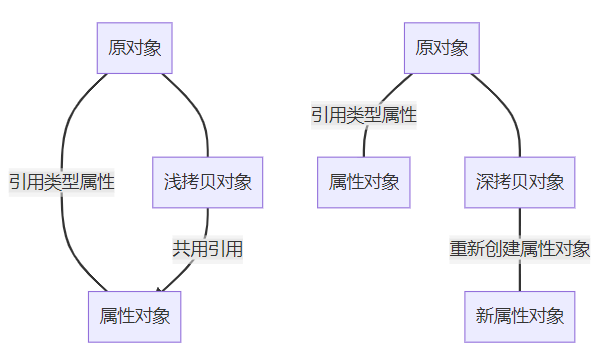
举个例子,有个person类包含name和address属性:
class address {
string city;
}
class person {
string name;
address address;
// 浅拷贝
person shallowcopy() {
person copy = new person();
copy.name = this.name;
copy.address = this.address;
return copy;
}
// 深拷贝
person deepcopy() {
person copy = new person();
copy.name = this.name;
copy.address = new address();
copy.address.city = this.address.city;
return copy;
}
}
二、大文件拷贝:别让你的程序“龟速运行”
之前做文件上传功能,用传统io方式拷贝大文件,结果服务器直接卡住。后来换成nio,速度直接起飞!
传统io就像蚂蚁搬家,一次搬一点,频繁读写磁盘;nio则像卡车运输,直接把数据从一个地方搬到另一个地方,速度快得多。
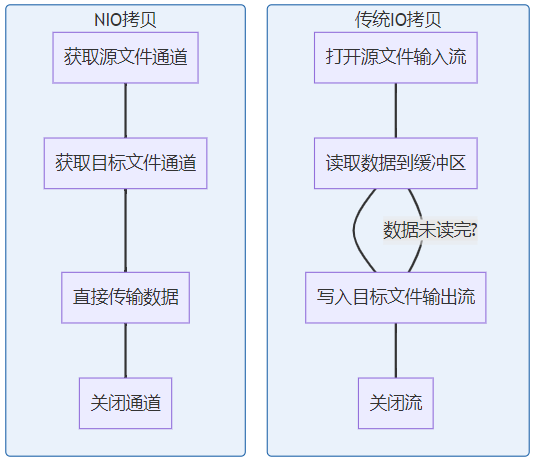
// 传统io方式,适合小文件
public static void copyfilebyio(file source, file dest) throws ioexception {
try (inputstream is = new fileinputstream(source);
outputstream os = new fileoutputstream(dest)) {
byte[] buffer = new byte[1024];
int len;
while ((len = is.read(buffer)) != -1) {
os.write(buffer, 0, len);
}
}
}
// nio方式,适合大文件
public static void copyfilebynio(file source, file dest) throws ioexception {
try (filechannel sourcechannel = new fileinputstream(source).getchannel();
filechannel destchannel = new fileoutputstream(dest).getchannel()) {
destchannel.transferfrom(sourcechannel, 0, sourcechannel.size());
}
}
三、对象拷贝的进阶方案:使用造好的轮子
手动写深拷贝代码太麻烦?别慌,java提供给我们有不少写好的办法。
1. 序列化与反序列化
就像把对象打包成快递,寄出去再拆开。虽然速度慢点,但能保证完全独立的拷贝。不过要注意,所有相关类都得实现serializable接口。
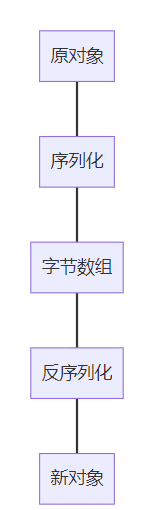
public static <t extends serializable> t deepcopybyserialization(t obj) {
try (bytearrayoutputstream baos = new bytearrayoutputstream();
objectoutputstream oos = new objectoutputstream(baos)) {
oos.writeobject(obj);
try (bytearrayinputstream bais = new bytearrayinputstream(baos.tobytearray());
objectinputstream ois = new objectinputstream(bais)) {
return (t) ois.readobject();
}
} catch (ioexception | classnotfoundexception e) {
throw new runtimeexception(e);
}
}
2. json序列化
用jackson或gson把对象转成json字符串,再转回来,简单粗暴。不过这种方式要求对象的属性都能被json正确解析。

import com.fasterxml.jackson.databind.objectmapper;
public static <t> t deepcopybyjson(t obj, class<t> clazz) {
try {
objectmapper mapper = new objectmapper();
string json = mapper.writevalueasstring(obj);
return mapper.readvalue(json, clazz);
} catch (exception e) {
throw new runtimeexception(e);
}
}
四、数组和集合的拷贝
数组的clone()方法看似简单,实则暗藏玄机:基本类型数组用它是深拷贝,对象数组就是浅拷贝。
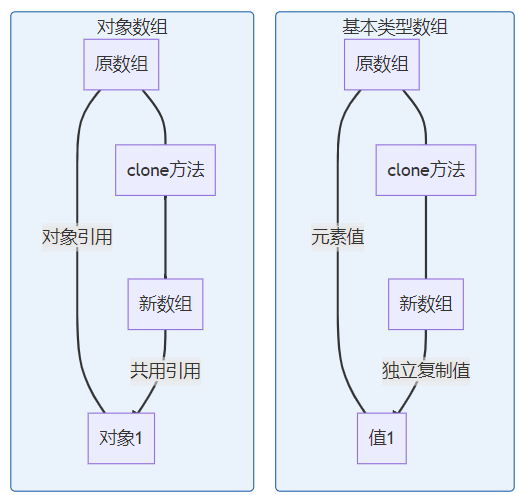
int[] intarray = {1, 2, 3};
int[] copiedintarray = intarray.clone(); // 深拷贝
person[] personarray = new person[2];
person[] copiedpersonarray = personarray.clone(); // 浅拷贝
集合类的构造函数也是浅拷贝,比如new arraylist<>(originallist)。想深拷贝集合,得手动遍历每个元素。
list<person> originallist = new arraylist<>();
list<person> deepcopiedlist = originallist.stream()
.map(person::deepcopy)
.collect(collectors.tolist());
五、第三方库:站在巨人的肩膀上
不想自己造轮子?apache commons lang和dozer能帮你大忙。前者提供了便捷的序列化拷贝工具,后者擅长对象属性映射,用起来超方便。
<!-- apache commons lang依赖 -->
<dependency>
<groupid>org.apache.commons</groupid>
<artifactid>commons-lang3</artifactid>
<version>3.12.0</version>
</dependency>
// 使用示例
person copiedperson = serializationutils.clone(originalperson);
六、总结:看不同场景选择合适的拷贝方式
- 简单对象用浅拷贝,复杂对象用深拷贝
- 大文件优先用nio,小文件用传统io
- 能偷懒就偷懒,善用第三方库
- 多写测试用例,别让拷贝“埋雷”
到此这篇关于java四种拷贝方式实战文章就介绍到这了,更多相关java四种拷贝方式内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论