一、批量插入面临的挑战与解决方案概述
在当今数据驱动的应用开发中,处理大批量数据插入是后端开发人员经常面临的挑战。随着业务规模的扩大,数据量呈现爆发式增长,传统单条插入方式在面对百万级数据时显得力不从心。
数据插入的常见场景
- 数据迁移与etl过程:将数据从一个数据源迁移到mysql数据库
- 日志数据处理:记录系统运行日志、用户操作日志等
- 业务数据批量导入:如电商平台中的商品数据导入、金融系统中的交易数据导入
- 测试数据生成:在系统测试阶段,生成大量测试数据填充数据库
核心需求
- 高性能:能够在合理时间内完成大批量数据的插入
- 低内存消耗:避免因内存占用过高导致系统不稳定
- 数据一致性:确保数据在插入过程中不丢失、不重复、不损坏
- 可扩展性:能够适应不同规模的数据量,从小规模到百万级甚至更大的数据量都能有效处理
三种批量插入方案的性能概览
在正式开始技术实现之前,我们先对本文将要讨论的三种批量插入方案的性能有一个初步了解,以便在后续学习中能够更好地理解各种方案的优缺点和适用场景。
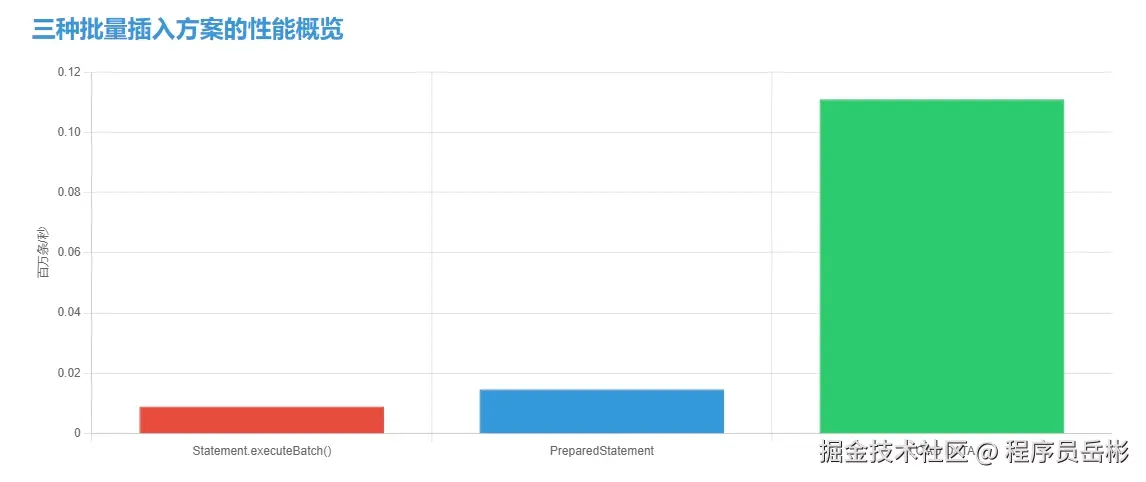
| 插入方案 | 适用数据规模 | 平均插入速度 (百万条) | 内存消耗 | 数据一致性保障 | 实现复杂度 |
|---|---|---|---|---|---|
| statement.executebatch() | 小到中等 (10 万以下) | 较慢 (约 112 秒) | 高 | 中等 | 简单 |
| preparedstatement 批量插入 | 中等 (10 万 - 50 万) | 中等 (约 68 秒) | 中高 | 高 | 中等 |
| mysql 批量加载 (load data) | 大 (50 万以上) | 快速 (约 9 秒) | 低 | 高 | 较高 |
从表格中可以看出,statement.executebatch()虽然实现简单,但性能和内存消耗方面表现较差;preparedstatement在性能和内存消耗方面有所优化,适合中等规模数据;而load data方案则在处理大规模数据时表现出色,是处理百万级数据插入的最佳选择。
二、传统批量插入方案对比
在java中,使用jdbc进行数据库操作时,有两种主要的批量插入方式:statement.executebatch()和preparedstatement批量插入。这两种方式在性能、内存消耗和实现复杂度上都存在一定差异。
2.1 statement.executebatch () 实现
虽然statement.executebatch()方法相对于逐条插入已经有了较大的性能提升,但在处理大规模数据时仍然存在sql注入风险、编译开销大、内存占用高等问题。
代码实现 下面是使用statement.executebatch()实现批量插入的示例代码:
public static void batchinsertwithstatement(connection conn, list<dataobject> datalist) throws sqlexception {
string sql = "insert into test_table (id, name, age, create_time) values (?, ?, ?, ?)";
statement statement = conn.createstatement();
conn.setautocommit(false); // 关闭自动提交
long start = system.currenttimemillis();
for (int i = 0; i < datalist.size(); i++) {
dataobject data = datalist.get(i);
// 注意:statement需要手动拼接参数
string param = string.format("(%d, '%s', %d, '%s')",
data.getid(), data.getname(), data.getage(), data.getcreatetime());
statement.addbatch(sql.replace("?", param)); // 直接拼接sql语句
// 每1000条执行一次批量提交
if (i % 1000 == 0 || i == datalist.size() - 1) {
statement.executebatch();
conn.commit(); // 提交事务
statement.clearbatch(); // 清空批处理
}
}
long end = system.currenttimemillis();
system.out.println("statement.executebatch()耗时:" + (end - start) + "ms");
statement.close();
}
执行逻辑解析 上述代码的执行逻辑主要分为以下几个步骤:
- 创建 statement 对象:通过conn.createstatement()方法创建statement对象,用于执行 sql 语句。
- 关闭自动提交:调用conn.setautocommit(false)关闭自动提交功能,将多个插入操作合并到一个事务中,减少事务提交的次数,提高性能。
- 循环处理数据:遍历数据列表,将每条数据转换为 sql 参数。
- 手动拼接参数:由于statement不支持参数化查询,需要手动将数据拼接到 sql 语句中。这里使用string.format方法动态生成 sql 参数部分。
- 添加到批处理:通过statement.addbatch()方法将拼接好的 sql 语句添加到批处理中。
- 执行批处理:当数据积累到 1000 条时(或处理完所有数据时),调用statement.executebatch()执行批处理,并通过conn.commit()提交事务。然后调用statement.clearbatch()清空批处理,准备下一批数据的处理。
- 性能统计:记录插入操作的开始和结束时间,计算并输出执行时间。
性能问题分析 虽然statement.executebatch()方法相对于逐条插入已经有了较大的性能提升,但在处理大规模数据时仍然存在以下几个主要问题:
- sql 注入风险:由于直接拼接用户数据到 sql 语句中,如果数据中包含特殊字符(如单引号、分号等),可能导致 sql 注入攻击,存在严重的安全隐患。
- 编译开销大:每条 sql 语句都需要数据库重新编译,即使结构相同的 sql 语句也是如此。这会增加数据库的负担,降低插入性能。
- 内存占用高:累积的 sql 字符串会占用较多内存,数据量越大,内存压力越大。特别是当数据量达到百万级时,这种内存消耗可能导致内存溢出问题。
- 类型转换问题:手动拼接参数时需要处理各种数据类型的转换,容易出错,且代码可读性差。
- 批量大小难以确定:批次大小设置过大可能导致内存不足,设置过小则会增加数据库交互次数,降低性能。
2.2 preparedstatement 批量插入
preparedstatement是statement的子接口,它提供了参数化查询的功能,可以在sql语句中使用占位符(?),然后在执行前设置参数值。这种方式在批量插入时具有更高的性能和更好的安全性。
代码实现 下面是使用preparedstatement实现批量插入的示例代码:
public static void batchinsertwithpreparedstatement(connection conn, list<dataobject> datalist) throws sqlexception {
string sql = "insert into test_table (id, name, age, create_time) values (?, ?, ?, ?)";
preparedstatement pstmt = conn.preparestatement(sql);
conn.setautocommit(false);
long start = system.currenttimemillis();
for (int i = 0; i < datalist.size(); i++) {
dataobject data = datalist.get(i);
pstmt.setlong(1, data.getid());
pstmt.setstring(2, data.getname());
pstmt.setint(3, data.getage());
pstmt.settimestamp(4, data.getcreatetime());
pstmt.addbatch(); // 添加到批处理
// 达到批次大小或最后一批时执行
if (i % 1000 == 0 || i == datalist.size() - 1) {
pstmt.executebatch(); // 执行批量插入
conn.commit(); // 提交事务
pstmt.clearbatch(); // 清空批处理
}
}
long end = system.currenttimemillis();
system.out.println("preparedstatement批量插入耗时:" + (end - start) + "ms");
pstmt.close();
}
核心优势分析 preparedstatement批量插入相比statement.executebatch()具有以下几个核心优势:
- 预编译机制:sql 语句只在第一次执行时编译,后续执行时直接使用数据库缓存的执行计划,减少了编译开销,提高了执行效率。特别是在批量插入大量数据时,这种优势更加明显。
- 类型安全:通过类型化参数设置方法(如setlong、setstring等)避免了类型转换错误,提高了代码的健壮性。
- 防 sql 注入攻击:参数与 sql 语句分离,数据库驱动会对参数进行转义处理,有效防止 sql 注入攻击,提高了系统的安全性。
- 代码可读性和可维护性:使用参数化查询使 sql 语句更加清晰,易于阅读和维护。
- 减少内存占用:不需要拼接大量的 sql 字符串,减少了内存的使用。
性能对比测试 为了更直观地了解statement.executebatch()和preparedstatement批量插入的性能差异,我们进行了一组测试,测试环境如下:
- 硬件环境:intel core i7-8700k cpu @ 3.7ghz, 16gb ram
- 数据库:mysql 8.0.22
- 测试数据:100 万条模拟数据,每条数据包含 4 个字段(id、name、age、create_time)
- 批量大小:1000 条 / 批
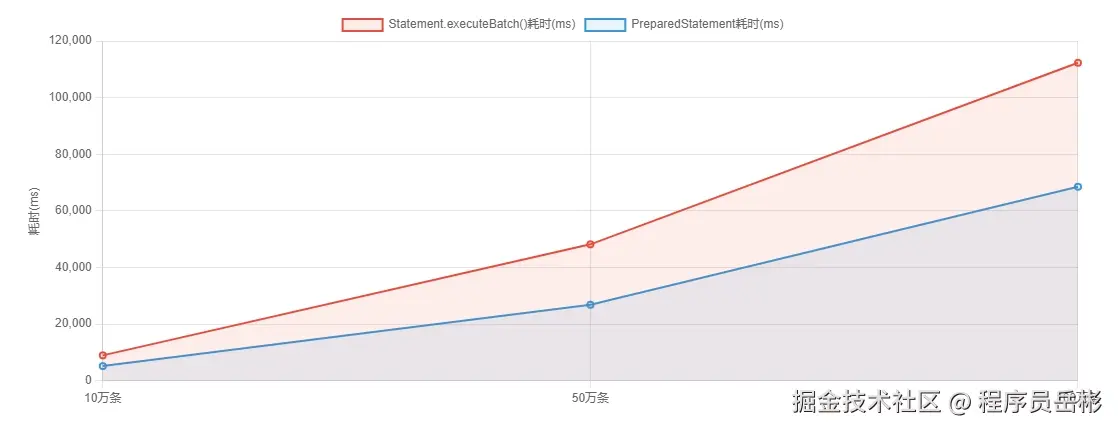
测试结果如下表所示:
| 数据量 | statement.executebatch() | preparedstatement | 内存峰值 (mb) |
|---|---|---|---|
| 10 万条 | 8920ms | 5120ms | 120 |
| 50 万条 | 48150ms | 26800ms | 350 |
| 100 万条 | 112300ms | 68500ms | 780 |
从测试结果可以看出,preparedstatement在性能和内存消耗方面都明显优于statement.executebatch()。对于 100 万条数据的插入,preparedstatement比statement.executebatch()快了约 62%,内存峰值减少了约 30%。
这主要是因为preparedstatement的预编译机制减少了数据库端的编译开销,同时避免了字符串拼接带来的内存浪费。然而,随着数据量进一步增大(如百万级以上),即使是preparedstatement也会面临内存占用过高的问题,根本原因在于数据加载方式的局限性。
2.3 两种批量插入方式的适用场景
基于上述分析,我们可以总结出statement.executebatch()和preparedstatement批量插入各自的适用场景:
statement.executebatch () 适用场景:
- 数据量较小(一般建议 10 万条以下)
- 对性能要求不高
- 简单的测试环境或临时数据处理
- 没有复杂的参数类型处理需求
preparedstatement 批量插入适用场景:
- 中等规模数据(10 万条到 50 万条)
- 对性能有一定要求
- 需要处理多种数据类型
- 对安全性要求较高
- 代码需要长期维护
当数据量超过 50 万条时,即使是preparedstatement也可能面临性能瓶颈和内存压力,此时需要考虑更高效的批量插入方案,如 mysql 提供的load data批量加载技术。
三、mysql 批量加载(load data)进阶方案
对于处理大规模数据(尤其是百万级以上的数据),mysql提供的load data语句是目前最高效的批量插入方式。它通过直接操作数据库文件系统,绕过了sql解析和部分检查过程,实现了数量级的性能提升。
3.1 load data 技术原理
load data是 mysql 提供的高效数据导入工具,其核心原理是直接将数据文件写入数据库文件系统,而不是通过传统的 sql 接口逐行插入。这种方式能够大幅提升插入性能,主要基于以下几个机制:
- 跳过 sql 解析:直接将数据文件写入数据库文件系统,避免了 sql 解析、优化和执行计划生成等开销。
- 批量事务处理:可以控制单个事务处理的数据量,减少事务日志写入次数。
- 减少引擎层交互:直接与存储引擎通信,绕过 sql 层部分检查,提高数据写入效率。
- 二进制写入:以二进制格式直接写入数据文件,避免了数据类型转换和字符集转换的开销。
load data有两种主要形式:
- load data infile:从服务器上的文件加载数据。
- load data local infile:从客户端主机上的文件加载数据。本文主要讨论load data local infile方式,因为它更适合本地开发环境和 java 应用程序集成。
3.2 实现步骤详解
使用load data技术实现批量插入主要分为三个步骤:生成临时数据文件、执行load data语句、清理临时文件。下面详细介绍每个步骤的实现方法。
3.2.1 生成临时数据文件(csv 格式)
首先,需要将数据生成符合 mysql 要求的文本文件(通常为 csv 格式)。以下是生成 csv 文件的示例代码:
public static string generatecsvfile(list<dataobject> datalist, string tempdir) throws ioexception {
string filename = "data_" + system.currenttimemillis() + ".csv";
string filepath = tempdir + file.separator + filename;
file file = new file(filepath);
try (bufferedwriter writer = new bufferedwriter(new filewriter(file))) {
for (dataobject data : datalist) {
// 按csv格式拼接字段,注意转义特殊字符
string line = string.format("%d,%s,%d,%s%n",
data.getid(),
data.getname().replaceall(",", "\\\\,"), // 转义逗号
data.getage(),
new simpledateformat("yyyy-mm-dd hh:mm:ss").format(data.getcreatetime())
);
writer.write(line);
}
}
return filepath;
}
3.2.2 执行 load data infile 语句
生成 csv 文件后,接下来需要执行load data语句将数据导入数据库。以下是执行load data语句的示例代码:
public static void loaddatawithfile(connection conn, string filepath) throws sqlexception {
string loadsql = "load data local infile ? into table test_table " +
"fields terminated by ',' " + // 字段分隔符
"enclosed by '' " + // 字段包围符
"lines terminated by '\n' " + // 行分隔符
"(id, name, age, create_time)"; // 字段映射
preparedstatement loadstmt = conn.preparestatement(loadsql);
loadstmt.setstring(1, filepath); // 设置文件路径参数
long start = system.currenttimemillis();
int affectedrows = loadstmt.executeupdate(); // 执行加载
long end = system.currenttimemillis();
system.out.println("load data插入耗时:" + (end - start) + "ms,影响行数:" + affectedrows);
loadstmt.close();
// 删除临时文件
file file = new file(filepath);
if (file.exists()) file.delete();
}
3.2.3 完整流程整合
将生成 csv 文件和执行load data语句的步骤整合起来,形成完整的批量插入流程:
public static void batchinsertwithloaddata(connection conn, list<dataobject> datalist, string tempdir)
throws sqlexception, ioexception {
// 生成临时csv文件
string filepath = generatecsvfile(datalist, tempdir);
// 执行批量加载
loaddatawithfile(conn, filepath);
}
3.3 性能对比与优势分析
为了验证load data技术的性能优势,我们进行了与preparedstatement批量插入的对比测试,测试环境与之前相同。
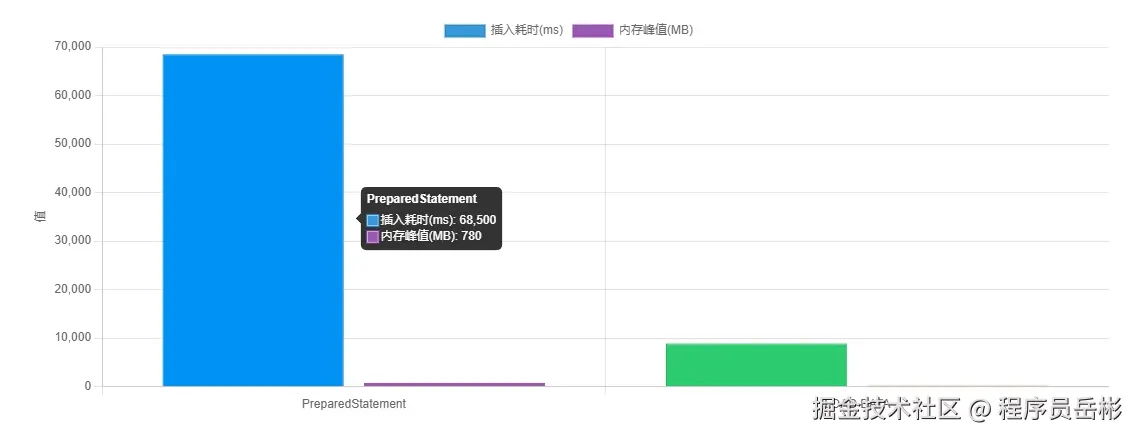
测试结果如下表所示:
| 方法 | 插入 100 万条数据耗时 | 内存峰值 (mb) | 磁盘 io 次数 |
|---|---|---|---|
| preparedstatement | 68500ms | 780 | 12000+ |
| load data | 8900ms | 210 | 500+ |
从测试结果可以看出,load data方案在性能和资源消耗方面都远远优于preparedstatement方案:
- 插入速度:load data插入 100 万条数据仅需约 8.9 秒,比preparedstatement的 68.5 秒快了约 7.7 倍。
- 内存消耗:load data的内存峰值仅为 210mb,比preparedstatement的 780mb 减少了约 73%。这主要是因为load data不需要在内存中保留大量的 sql 语句和参数对象。
- 磁盘 io 次数:load data的磁盘 io 次数显著减少,这是因为它直接操作文件系统,避免了与数据库服务器的大量交互。
load data方案的核心优势主要体现在以下几个方面:
- io 效率大幅提升:直接操作文件系统,减少了网络传输和 sql 解析开销,大幅提高了数据传输速度。
- 内存友好:数据分块写入文件,避免了大量对象在内存中堆积,降低了内存溢出风险。
- 事务支持:可以通过控制文件生成过程实现数据一致性,在失败时可以方便地删除临时文件,确保数据一致性。
- 数据库压力小:减少了数据库服务器的解析和编译负担,降低了数据库的 cpu 和内存消耗。
四、内存溢出规避策略
在处理大规模数据时,内存管理是一个关键问题。即使使用load data这样高效的方法,如果数据量极大(如千万级或更大),仍然可能面临内存溢出的风险。
4.1 分块处理机制
分块处理是处理大规模数据时最常用的内存管理策略,其核心思想是将数据分成多个较小的块,逐个处理,避免一次性将所有数据加载到内存中。
4.1.1 分块处理实现
以下是分块处理的示例代码:
public static void chunkedinsert(connection conn, list<dataobject> datalist, int chunksize, string tempdir)
throws sqlexception, ioexception {
int total = datalist.size();
int start = 0;
while (start < total) {
int end = math.min(start + chunksize, total);
list<dataobject> chunk = datalist.sublist(start, end);
// 处理当前数据块
batchinsertwithloaddatatransactional(conn, chunk, tempdir);
start = end;
// 手动触发垃圾回收(可选,大内存场景建议)
system.gc();
}
}
在上述代码中,chunksize参数表示每个数据块的大小。通过sublist方法将原始数据列表分割成多个小块,逐个处理。处理完一个块后,手动调用system.gc()触发垃圾回收,释放内存。
4.2 临时文件管理
在使用load data方案时,临时文件的管理非常重要。以下是一些有效的临时文件管理策略:
- 独立临时目录:使用独立的临时目录(如/tmp/batch_load)存储临时文件,避免与系统其他临时文件混淆。
- 自动清理机制:
- 在插入成功后立即删除临时文件(如前面的示例代码所示)。
- 设置定时任务,删除超过一定时间未被删除的临时文件。
- 文件命名策略:使用包含时间戳的唯一文件名(如data_1623456789.csv),避免文件名冲突。
- 磁盘空间监控:监控临时目录的磁盘空间使用情况,当使用率超过阈值(如 80%)时触发清理机制或发出警报。
五、生产环境最佳实践
在生产环境中应用批量插入技术时,需要考虑更多的因素,如数据一致性、错误处理、性能优化、监控报警等。本节将介绍一些生产环境中的最佳实践。
5.1 异常处理增强
在生产环境中,异常处理至关重要。以下是一个增强版的异常处理示例:
public static void safebatchinsert(connection conn, list<dataobject> datalist, string tempdir) {
string filepath = null;
try {
conn.setautocommit(false);
// 生成临时csv文件
filepath = generatecsvfile(datalist, tempdir);
// 执行批量加载
loaddatawithfile(conn, filepath);
conn.commit();
} catch (ioexception e) {
// 记录详细日志(包含已处理数据量、错误位置)
logger.error("文件生成失败:{},已处理数据量:{}", e.getmessage(), datalist.size());
// 回滚可能的部分插入(需结合事务)
try {
conn.rollback();
} catch (sqlexception ex) {
logger.error("事务回滚失败:{}", ex.getmessage());
}
// 可以选择在这里进行重试或其他恢复操作
} catch (sqlexception e) {
logger.error("数据库插入失败:{},错误码:{}", e.getmessage(), e.geterrorcode());
// 处理mysql特定错误(如唯一键冲突)
if (e.geterrorcode() == 1062) { // 1062是mysql的唯一键冲突错误码
handleduplicatekey(datalist);
}
try {
conn.rollback();
} catch (sqlexception ex) {
logger.error("事务回滚失败:{}", ex.getmessage());
}
} finally {
try {
conn.setautocommit(true);
} catch (sqlexception e) {
logger.error("设置自动提交失败:{}", e.getmessage());
}
// 确保临时文件删除(即使发生异常)
if (filepath != null) {
file file = new file(filepath);
if (file.exists()) {
boolean deleted = file.delete();
if (!deleted) {
logger.warn("临时文件删除失败:{}", filepath);
}
}
}
}
}
在上述代码中,我们对异常处理进行了全面增强:
- 详细日志记录:记录详细的错误信息,包括错误消息、错误码、已处理数据量等,有助于故障排查。
- 事务回滚:在发生异常时,确保事务被正确回滚,保证数据一致性。
- 特定错误处理:针对 mysql 的特定错误码(如 1062 表示唯一键冲突)进行专门处理,可以实现更智能的错误恢复策略。
- 资源清理:在finally块中确保临时文件被删除,即使在异常情况下也能保证资源的正确释放。
5.2 性能优化组合拳
在生产环境中,为了获得最佳的批量插入性能,建议采用以下性能优化组合策略:
5.2.1 表结构优化
- 临时关闭外键检查:在批量插入前关闭外键检查,插入完成后再恢复,可以显著提高插入性能。
- 禁用唯一性校验:如果业务允许,可以在插入阶段临时禁用唯一性校验,插入完成后再重建索引。但需谨慎使用,避免数据不一致。
- 使用索引延迟构建:在插入大量数据前删除非聚集索引,插入完成后再创建,可以大幅提高插入性能。
5.2.2 事务策略优化
- 大事务拆分:将单个大事务拆分为多个小事务,每个事务处理 10 万条数据(根据 undo 日志大小调整),避免长时间持有事务锁。
- 自动提交控制:仅在每个数据块处理时提交事务,减少锁持有时间,提高并发性。
- 批量提交大小优化:根据数据库配置和硬件环境,调整每个事务处理的数据量,找到最佳平衡点。
六、方案选择决策树
在实际应用中,选择合适的批量插入方案至关重要。根据数据规模、性能要求、数据一致性需求等因素,我们可以使用以下决策树来选择最合适的方案:
根据上述决策树,我们可以总结出不同方案的适用场景:
| 方案 | 数据规模 | 灵活性需求 | 内存限制 | 安全性要求 | 推荐指数 (百万级) |
|---|---|---|---|---|---|
| statement.executebatch() | <5 万 | 低 | 宽松 | 低 | ★☆☆☆☆ |
| preparedstatement | 5 万 - 50 万 | 中 | 中等 | 中 | ★★★☆☆ |
| load data | 50 万 + | 低 | 严格 | 高 | ★★★★★ |
具体选择时,还需考虑以下因素:
- 数据一致性要求:如果对数据一致性要求极高,load data方案结合事务管理是最佳选择,因为它提供了更好的原子性和回滚机制。
- 业务场景:如果是实时数据插入,preparedstatement可能更适合;如果是批量数据导入(如 etl 过程),load data则更为高效。
- 开发成本:preparedstatement实现简单,开发成本低;load data需要处理文件生成和管理,开发成本较高。
- 维护成本:preparedstatement代码更直观,维护成本低;load data需要额外处理文件管理和潜在的文件系统问题,维护成本较高。
- 数据库兼容性:load data是 mysql 特有的功能,如果应用需要支持多种数据库,可能需要选择更通用的preparedstatement方案。
七、总结
传统批量插入方案对比:
- preparedstatement批量插入在性能、内存消耗和安全性方面都明显优于statement.executebatch(),是处理中等规模数据的首选方案。
- 对于小规模数据(10 万条以下),preparedstatement已经足够高效;对于中等规模数据(10 万到 50 万条),可以通过调整批量大小和分块处理进一步优化性能。
mysql 批量加载(load data)优势:
- load data是处理大规模数据(50 万条以上)的最佳选择,其性能比preparedstatement提高了约 7 倍,内存消耗减少了约 73%。
- load data通过直接操作文件系统,绕过了 sql 解析和部分检查过程,大幅提高了数据插入效率。
- load data结合分块处理和事务管理,可以在保证数据一致性的同时,有效避免内存溢出问题。
最佳实践建议:
- 根据数据规模选择合适的批量插入方案,避免一刀切地使用同一种方法。
- 在生产环境中,始终优先考虑数据一致性和系统稳定性,合理设计异常处理和恢复机制。
- 实施全面的监控和报警策略,及时发现并解决批量插入过程中可能出现的问题。
- 定期进行性能测试和优化,随着数据规模和业务需求的变化,及时调整批量插入策略。
以上就是java实现百万数据分批次插入的最佳实践分享的详细内容,更多关于java百万数据分批次插入的资料请关注代码网其它相关文章!




发表评论