一、直接使用代码
更详细内容请参考阿里云官网文档的python部分oss-python
import oss2
from itertools import islice
# 1 代码嵌入方式配置
# 填写ram用户的访问密钥(accesskey id和accesskey secret)。
accesskeyid = 'youraccesskeyid'
accesskeysecret = 'youraccesskeysecret'
# 使用代码嵌入的ram用户的访问密钥配置访问凭证。
auth = oss2.auth(accesskeyid, accesskeysecret)
# endpoint填写bucket所在地域对应的endpoint。以华东1(杭州)为例,endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。
endpoint = 'http://oss-cn-shanghai.aliyuncs.com'
# 填写bucket名称。
bucketname = 'z-libai-test'
bucket = oss2.bucket(auth, endpoint, bucketname)
# 上传文件到oss。
# objectname由包含文件后缀,不包含bucket名称组成的object完整路径,例如abc/efg/123.jpg。
objectname = '3_jwh/25_filetest/test1.lab'
# localfile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
localfile = 'e:\\vscodepros\\python\\oss\\test001.txt'
bucket.put_object_from_file(objectname, localfile)
# 生成下载链接
filelink = 'http://'+bucketname+'.oss-cn-shanghai.aliyuncs.com/'+objectname
print(filelink)
#下载oss文件到本地文件。
# objectname由包含文件后缀,不包含bucket名称组成的object完整路径,例如abc/efg/123.jpg。
# localfile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
bucket.get_object_to_file('yourobjectname', 'yourlocalfile')
# oss2.objectiterator用于遍历文件。列举10个文件
for b in islice(oss2.objectiterator(bucket), 10):
print(b.key)
# 列举bucket下的所有文件。
for obj in oss2.objectiterator(bucket):
print(obj.key)
# 列举指定前缀的所有文件
# 列举fun文件夹下的所有文件,包括子目录下的文件。
for obj in oss2.objectiterator(bucket, prefix='fun/'):
print(obj.key)
# 列举指定起始位置后的所有文件
# 列举指定字符串之后的所有文件。即使存储空间中存在marker的同名object,返回结果中也不会包含这个object。
for obj in oss2.objectiterator(bucket, marker="x2.txt"):
print(obj.key)
# 列举指定目录下的文件和子目录
# 列举fun文件夹下的文件与子文件夹名称,不列举子文件夹下的文件。
for obj in oss2.objectiterator(bucket, prefix = 'fun/', delimiter = '/'):
# 通过is_prefix方法判断obj是否为文件夹。
if obj.is_prefix(): # 判断obj为文件夹。
print('directory: ' + obj.key)
else: # 判断obj为文件。
print('file: ' + obj.key)
# 获取指定目录下的文件大小
def calculatefolderlength(bucket, folder):
length = 0
for obj in oss2.objectiterator(bucket, prefix=folder):
length += obj.size
return length
for obj in oss2.objectiterator(bucket, delimiter='/'):
if obj.is_prefix(): # 判断obj为文件夹。
length = calculatefolderlength(bucket, obj.key)
print('directory: ' + obj.key + ' length:' + str(length) + "byte.")
else: # 判断obj为文件。
print('file:' + obj.key + ' length:' + str(obj.size) + "byte.")
二、详细使用
1. 环境准备
官方文档地址:oss文档python参考
1.1 python环境
参考文章:最新python下载安装及环境搭建教程
1.2 oss的sdk安装
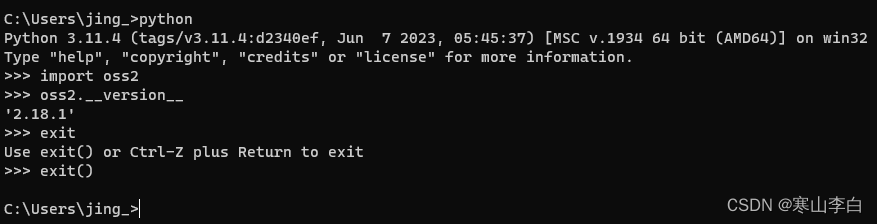
cmd窗口进入后执行命令安装oss的sdk
pip install oss2
执行
python
进入python环境
输入命令查看oss的sdk
import oss2
回车
oss2.__version__
回车
显示oss版本即可
exit()
退出
2. 初始化配置
配置访问凭证(连接oss的参数)
# -*- coding: utf-8 -*- import oss2 # 填写ram用户的访问密钥(accesskey id和accesskey secret)。 accesskeyid = 'youraccesskeyid' accesskeysecret = 'youraccesskeysecret' # 使用代码嵌入的ram用户的访问密钥配置访问凭证。 auth = oss2.auth(accesskeyid, accesskeysecret) # yourendpoint填写bucket所在地域对应的endpoint。以华东1(杭州)为例,endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。 endpoint = 'yourendpoint'
3. bucket配置创建
# 填写bucket名称。# yourbucketname填写存储空间名称。 bucket = oss2.bucket(auth, endpoint, 'yourbucketname') # 设置存储空间为私有读写权限。此步可省略 bucket.create_bucket(oss2.models.bucket_acl_private)
4. 文件上传到oss
# 上传文件到oss。
# yourobjectname由包含文件后缀,不包含bucket名称组成的object完整路径,例如abc/efg/123.jpg。
# yourlocalfile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
bucket.put_object_from_file('yourobjectname', 'yourlocalfile')
5. oss文件链接生成
可通过链接直接下载文件
filelink = 'http://'+'yourlocalfile'+'.oss-cn-shanghai.aliyuncs.com/'+'yourobjectname' print(filelink)
6. oss文件下载到本地
#下载oss文件到本地文件。
# yourobjectname由包含文件后缀,不包含bucket名称组成的object完整路径,例如abc/efg/123.jpg。
# yourlocalfile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
bucket.get_object_to_file('yourobjectname', 'yourlocalfile')
7. 生成文件下载链接
# 生成下载链接 filelink = 'http://'+bucketname+'.oss-cn-shanghai.aliyuncs.com/'+objectname print(filelink)
8. 列举oss文件(指定数量)
需引入islice
from itertools import islice
# oss2.objectiterator用于遍历文件。列举10个文件
for b in islice(oss2.objectiterator(bucket), 10):
print(b.key)
9. 列举oss文件(所有)
# 列举bucket下的所有文件。
for obj in oss2.objectiterator(bucket):
print(obj.key)
10. 列举指定前缀的文件(所有)
# 列举指定前缀的所有文件
# 列举fun文件夹下的所有文件,包括子目录下的文件。
for obj in oss2.objectiterator(bucket, prefix='fun/'):
print(obj.key)
11. 列举指定起始位置的文件(所有)
# 列举指定起始位置后的所有文件
# 列举指定字符串之后的所有文件。即使存储空间中存在marker的同名object,返回结果中也不会包含这个object。
for obj in oss2.objectiterator(bucket, marker="x2.txt"):
print(obj.key)
12. 列举指定目录下的文件和子目录(所有)
# 列举指定目录下的文件和子目录
# 列举fun文件夹下的文件与子文件夹名称,不列举子文件夹下的文件。
for obj in oss2.objectiterator(bucket, prefix = 'fun/', delimiter = '/'):
# 通过is_prefix方法判断obj是否为文件夹。
if obj.is_prefix(): # 判断obj为文件夹。
print('directory: ' + obj.key)
else: # 判断obj为文件。
print('file: ' + obj.key)
13. 删除oss文件
# yourobjectname表示删除oss文件时需要指定包含文件后缀,不包含bucket名称在内的完整路径,例如abc/efg/123.jpg。
bucket.delete_object('yourobjectname')
14. 获取指定目录下的文件大小
def calculatefolderlength(bucket, folder):
length = 0
for obj in oss2.objectiterator(bucket, prefix=folder):
length += obj.size
return length
for obj in oss2.objectiterator(bucket, delimiter='/'):
if obj.is_prefix(): # 判断obj为文件夹。
length = calculatefolderlength(bucket, obj.key)
print('directory: ' + obj.key + ' length:' + str(length) + "byte.")
else: # 判断obj为文件。
print('file:' + obj.key + ' length:' + str(obj.size) + "byte.")
到此这篇关于python实现对阿里云oss对象存储的操作详解的文章就介绍到这了,更多相关python操作阿里云oss内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!






发表评论