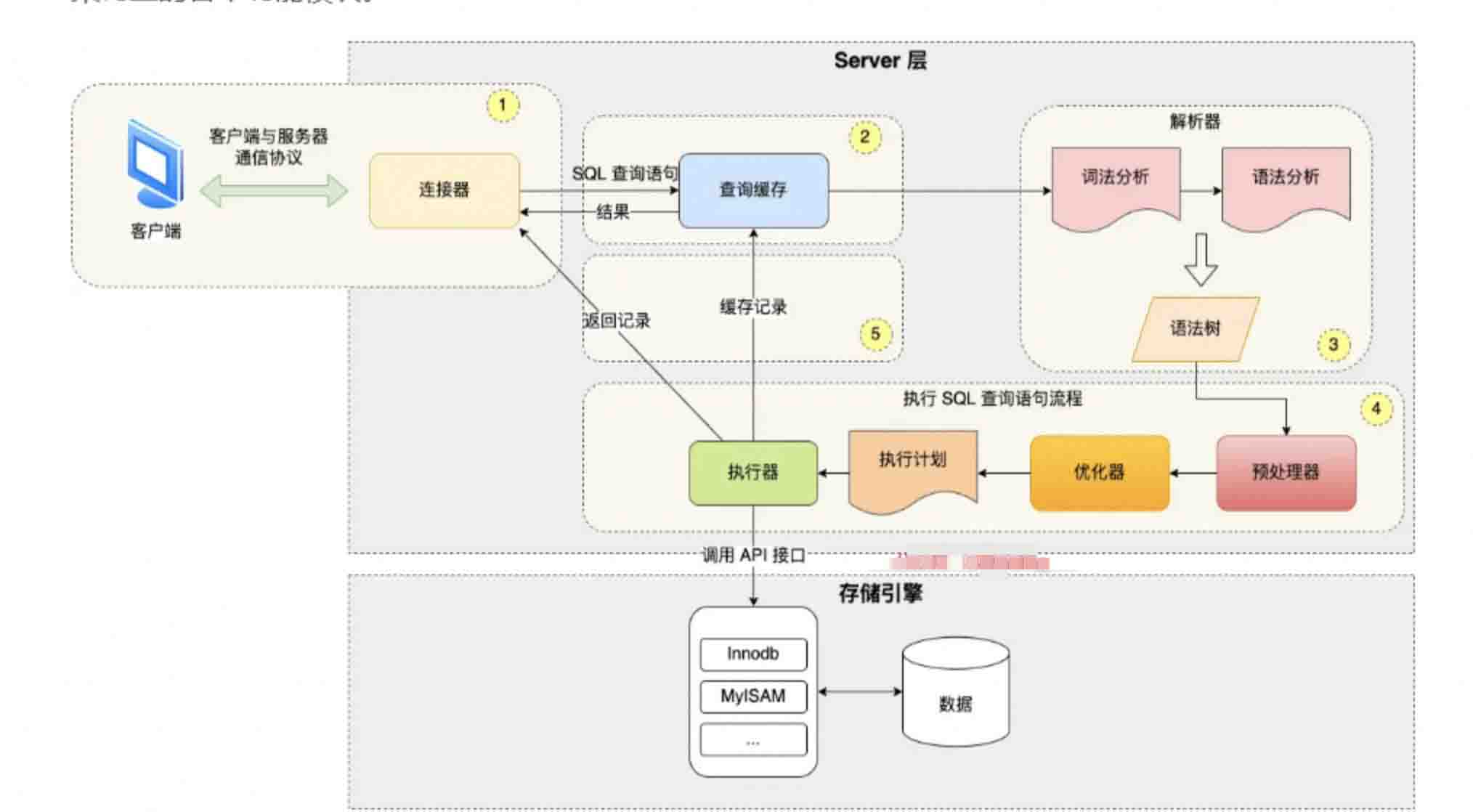
关于sql在mysql中的执行过程:mysql中select查询语句的执行过程
如下图所示:
在 mysql 中,深分页(deep pagination)是指当使用limit和offset进行分页查询时,随着offset值的增大,查询性能显著下降的现象。
例如,查询第 10000 页(每页 10 条数据)时,offset为 99990,mysql 需要扫描前面 99990 行才能找到目标数据,导致性能瓶颈。
1、深分页
是对大型数据集进行分页查询时,尤其是当需要获取较后页的数据时,性能可能会受到影响。
传统的分页方法在数据量较大时,随着页数的增加,性能会迅速下降。
1.1. 传统分页
当数据进行查询的时候,需要进行以下过程:

select * from table_name order by id limit offset, size;
- limit:控制每页返回的记录数(size)。
- offset:跳过前多少条记录(offset)。
1.2. 问题原因
1、扫描大量数据:
mysql需要跳过大量的数据行才能返回请求的数据。在数据量较大的表中,扫描的成本是巨大的,导致查询延迟增加。
2、锁竞争问题:
在使用offset进行分页时,数据表的锁可能被频繁地获取和释放,尤其是在高并发的情况下,会导致锁竞争问题,进一步影响数据库的响应速度。
3、i/o瓶颈:
深分页查询会对i/o性能产生压力,因为每次查询都需要读取大量的磁盘数据,尤其是在使用mysql的磁盘存储时,i/o操作会显著影响性能。
2、深分页的优化方案
2.1、索引介绍
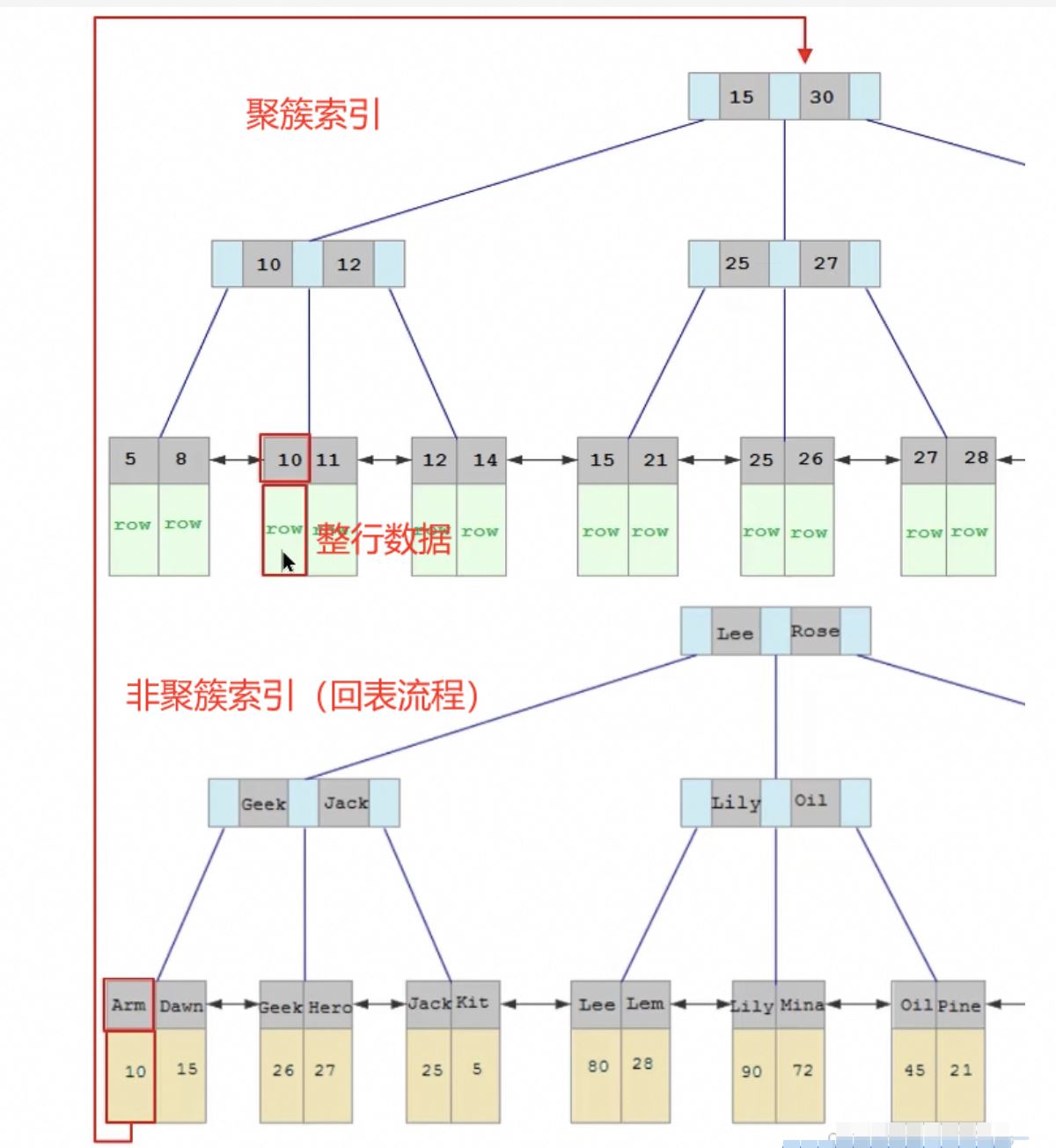
在mysql中索引分为聚簇索引和非聚簇索引。
1、b+树索引的特点:
- 节点存储:b+树是一种自平衡的树结构,其中每个节点可以有多个子节点。
- 非叶子节点存储的是指向子节点的指针和分隔值,而叶子节点存储的是实际的数据记录或记录的指针。
- 顺序访问:叶子节点中的数据是按照索引列的顺序存储的,这使得范围查询非常高效。
2、聚簇索引和非聚簇索引:
聚簇索引(主键索引)的叶子节点直接存储行数据,而非聚簇索引(二级索引)的叶子节点存储的是主键值。
如下图所示:
2.2、优化方案分类
1. 基于主键游标的分页
1、原理:
通过记录上一页的最后一个值(如主键或排序字段),作为下一页的起点,避免offset。
2、适用场景:
数据有序且可唯一标识(如id或时间戳)。
3、实现步骤:
假设我们有一个users表,并且希望查询某一页的数据,传统的分页查询如下: select * from users order by id limit 10 offset 1000; 使用游标分页的查询如下: select * from users where id > ? order by id limit 10;
4、优点:
避免offset,直接定位到起始位置。查询效率稳定,不受页数影响。
5、缺点:
无法直接跳转到任意页。
需要业务层维护“游标”(如上一页最后一个记录的id)。
2. 延迟关联
1、原理:
先通过子查询获取主键,再通过主键关联原表获取完整数据。
2、适用场景:
需要关联多表或查询非主键字段的场景。
3、实现步骤:
-- 1. 先查询主键(使用覆盖索引)
select id from table_name order by id limit 99990, 10;
-- 2. 通过主键关联原表获取完整数据
select t.*
from table_name t
join (
select id from table_name order by id limit 99990, 10
) as tmp on t.id = tmp.id;
4、优点:
减少扫描数据量,尤其是当主键字段有索引时。
5、缺点:
需要额外的子查询和 join 操作。
3. 覆盖索引
1、原理:
创建包含查询所需字段的复合索引,避免回表操作。
2、适用场景:
查询字段较少且可被索引覆盖。
3、实现步骤:
-- 创建覆盖索引(假设按 id 排序) create index idx_cover on table_name (id, name, age); -- 使用覆盖索引查询(无需回表) select id, name, age from table_name order by id limit 100000, 10;
4、优点:
索引本身包含所需数据,减少 i/o。
5、缺点:
索引占用额外存储空间。
4. 分区表
1、原理:
将大表按规则(如按时间或范围)拆分为多个分区,查询时只扫描相关分区。
2、适用场景:
数据可按某种规则分区(如按时间)。
3、实现步骤:
1、按时间范围分区
按时间范围分区
create table orders (
id bigint primary key,
user_id int,
create_time datetime
)
partition by range (year(create_time)) (
partition p2022 values less than (2023),
partition p2023 values less than (2024),
partition p2024 values less than (2025)
);
-- 查询2023年的订单,分页
select * from orders
where create_time between '2023-01-01' and '2023-12-31'
order by create_time desc
limit 1000000, 20;
优化效果:仅扫描 p2023 分区,避免全表扫描。
2、按 id 范围分区
create table users (
id bigint primary key,
name varchar(100)
)
partition by range (id) (
partition p1 values less than (1000000),
partition p2 values less than (2000000),
partition p3 values less than (maxvalue)
);
-- 查询 id > 1000000 的用户,分页
select * from users
where id > 1000000
order by id
limit 20;
仅扫描 p2 和 p3 分区,跳过 p1。4、优点:
显著减少扫描数据量。
5、缺点:
分区管理复杂,不适合频繁修改分区规则的场景。
5. 缓存机制
1、原理:
对频繁访问的分页结果进行缓存(如 redis),减少数据库查询。
2、适用场景:
数据更新频率低,分页请求频繁。
3、实现步骤:
- 使用缓存中间件(如 redis)存储分页结果。
- 对于冷数据或过深分页,直接返回缓存或提示用户跳转限制。
4、优点:
显著降低数据库压力。
5、缺点:
数据实时性要求高的场景不适用。
6. 业务层优化
1、限制最大页数:
如限制用户最多查看前 100 页。
2、滑动窗口分页:
允许用户通过“上一页/下一页”滑动访问,而非跳转到任意页。
3、预加载数据:
在用户浏览当前页时,预加载下一页数据。
性能对比

3、总结
深分页是 mysql 处理大数据量时的常见性能瓶颈。优化的核心在于减少扫描数据量和避免 offset 的全表扫描。
根据业务需求选择合适的方案:
- 优先推荐:游标分页或延迟关联(适合大多数场景)。
- 补充方案:覆盖索引、分区表或缓存机制(针对特定需求)。
- 业务层配合:限制分页深度或改用滑动窗口。
通过合理设计索引、查询语句和分页逻辑,可以显著提升深分页的性能,避免 mysql 在大数据量下的性能退化。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论