springboot集成easy-es
easy-es(简称ee)是一款基于elasticsearch(简称es)官方提供的resthighlevelclient打造的orm开发框架,在 resthighlevelclient 的基础上,只做增强不做改变,为简化开发、提高效率而生
一、集成demo
1、添加依赖
<!-- 排除springboot中内置的es依赖,以防和easy-es中的依赖冲突-->
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-web</artifactid>
<exclusions>
<exclusion>
<groupid>org.elasticsearch.client</groupid>
<artifactid>elasticsearch-rest-high-level-client</artifactid>
</exclusion>
<exclusion>
<groupid>org.elasticsearch</groupid>
<artifactid>elasticsearch</artifactid>
</exclusion>
</exclusions>
</dependency>
<!--引入es的坐标-->
<dependency>
<groupid>org.elasticsearch.client</groupid>
<artifactid>elasticsearch-rest-high-level-client</artifactid>
<version>7.14.1</version>
</dependency>
<dependency>
<groupid>org.elasticsearch.client</groupid>
<artifactid>elasticsearch-rest-client</artifactid>
<version>7.14.1</version>
</dependency>
<dependency>
<groupid>org.elasticsearch</groupid>
<artifactid>elasticsearch</artifactid>
<version>7.14.1</version>
</dependency>
<dependency>
<groupid>cn.easy-es</groupid>
<artifactid>easy-es-boot-starter</artifactid>
<version>1.1.1</version>
</dependency>2、配置信息
# 默认为true,若为false时,则认为不启用本框架 easy-es.enable: true #填你的es连接地址 easy-es.address : 127.0.0.1:9200 # username: 有设置才填写,非必须 easy-es.username : elastic # password: 有设置才填写,非必须 easy-es.password : 123456
3、启动类中添加 @esmapperscan 注解,扫描 mapper 文件夹
@springbootapplication
@esmapperscan("com.example.elasticsearch.mapper")
public class application {
public static void main(string[] args) {
springapplication.run(application.class, args);
}
}4、实体类和mapper
@data
public class document {
/**
* es中的唯一id,当您字段命名为id且类型为string时,且不需要采用uuid及自定义id类型时,可省略此注解
*/
@indexid(type = idtype.none)
private string id;
/**
* 文档标题,不指定类型默认被创建为keyword类型,可进行精确查询
*/
private string title;
/**
* 文档内容,指定了类型及存储/查询分词器
*/
@indexfield(fieldtype = fieldtype.text, analyzer = analyzer.ik_smart, searchanalyzer = analyzer.ik_max_word)
private string content;
}
public interface documentmapper extends baseesmapper<document> {
}5、测试
@restcontroller
public class easyescontroller {
@autowired
private documentmapper documentmapper;
@getmapping("/insert")
public integer insert() {
// 初始化-> 新增数据
document document = new document();
document.settitle("老汉");
document.setcontent("推*技术过硬");
return documentmapper.insert(document);
}
@getmapping("/search")
public list<document> search() {
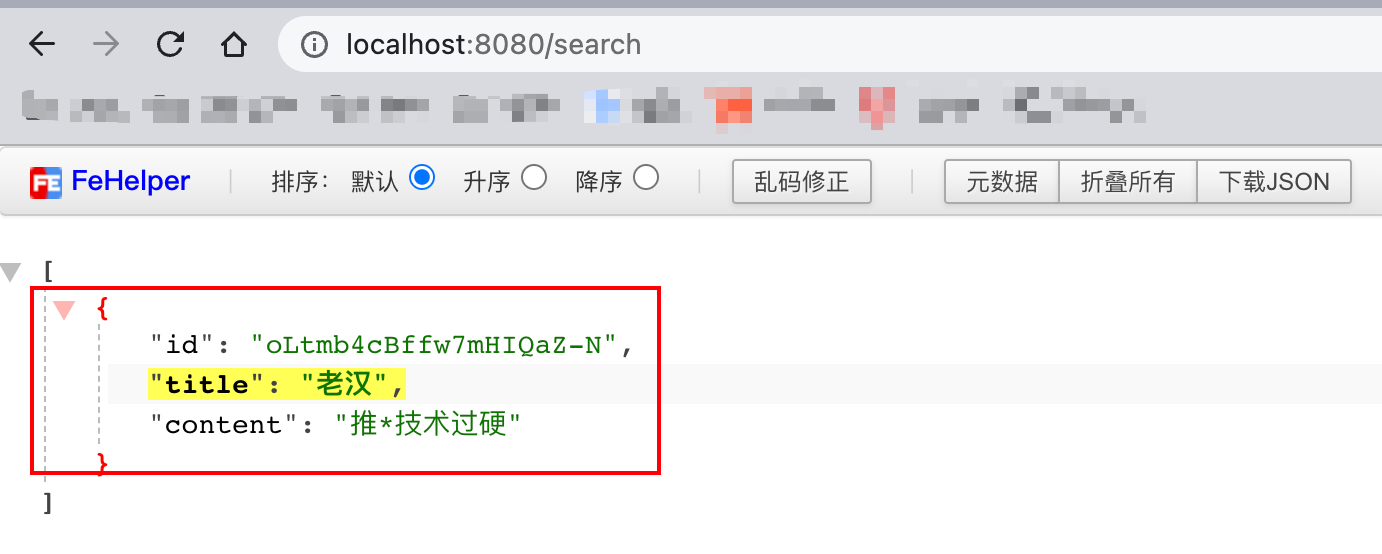
// 查询出所有标题为老汉的文档列表
lambdaesquerywrapper<document> wrapper = new lambdaesquerywrapper<>();
wrapper.eq(document::gettitle, "老汉");
return documentmapper.selectlist(wrapper);
}
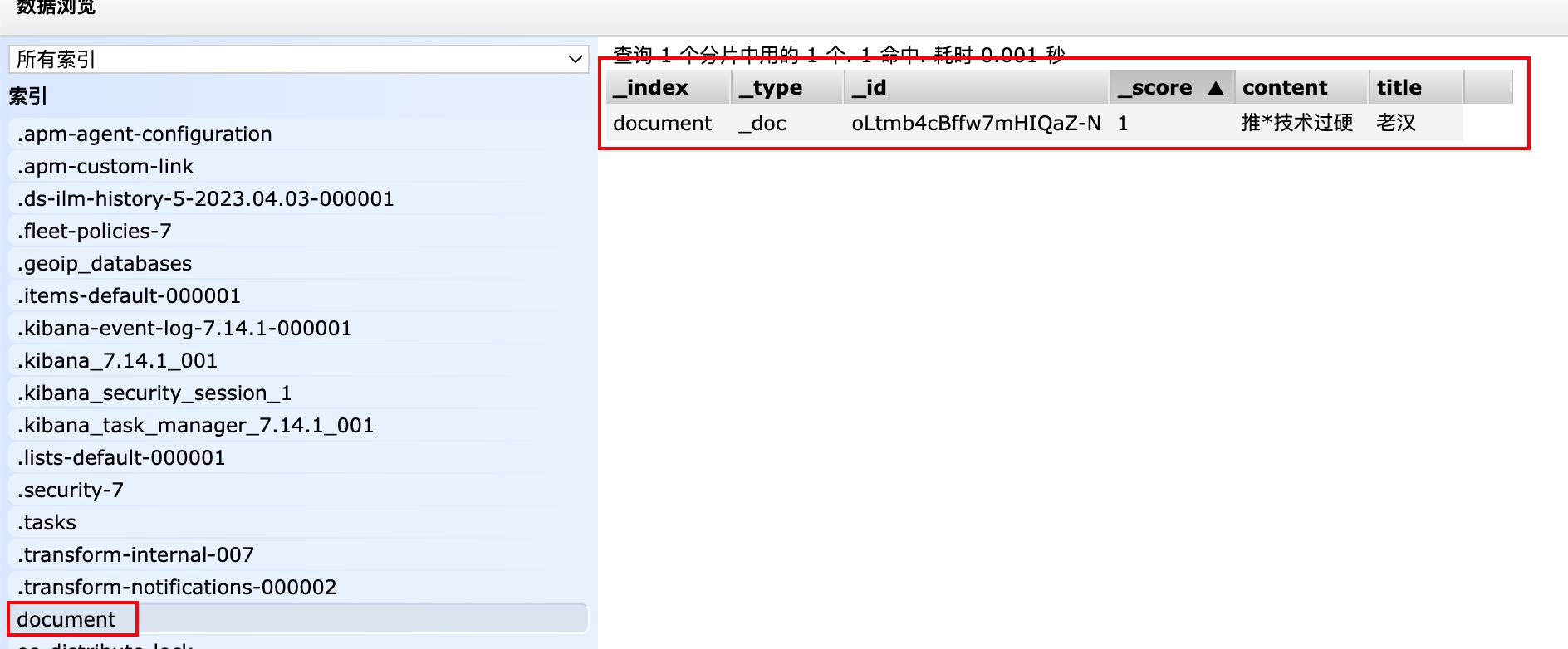
}http://localhost:8080/insert(插入数据)
http://localhost:8080/search(查询数据)
二、索引crud
首先说一下索引的托管模式,ee这里有三种托管模式
- 自动托管之平滑模式(默认):在此模式下,索引的创建更新数据迁移等全生命周期用户均不需要任何操作即可完成
- 自动托管之非平滑模式:在此模式下,索引额创建及更新由ee全自动异步完成,但不处理数据迁移工作
- 手动模式:在此模式下,索引的所有维护工作ee框架均不介入,由用户自行处理,ee提供了开箱即用的索引crud相关api
前置条件
索引crud相关的api都属于手动挡范畴,因此我们执行下述所有api前必须先配置开启手动挡,以免和自动挡冲突
easy-es:
global-config:
process_index_mode: manul # 手动挡模式创建索引
@test
void createindex01(){
// 绝大多数场景推荐使用
documentmapper.createindex();
}
@test
void createindex02(){
// 适用于定时任务按日期创建索引场景
string indexname = localdate.now().format(datetimeformatter.ofpattern("yyyy-mm-dd"));
documentmapper.createindex(indexname);
}
@test
void createindex03() {
// 复杂场景使用
lambdaesindexwrapper<document> wrapper = new lambdaesindexwrapper<>();
// 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引
wrapper.indexname(document.class.getsimplename().tolowercase());
// 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型(支持分词查询)
wrapper.mapping(document::gettitle, fieldtype.keyword, 2.0f)
.mapping(document::getcontent, fieldtype.text, analyzer.ik_smart, analyzer.ik_max_word);
// 设置分片及副本信息,可缺省
wrapper.settings(3, 2);
// 创建索引
boolean isok = documentmapper.createindex(wrapper);
}查询索引
@test
public void testexistsindex() {
// 测试是否存在指定名称的索引
string indexname = document.class.getsimplename().tolowercase();
boolean existsindex = documentmapper.existsindex(indexname);
assertions.asserttrue(existsindex);
}
@test
public void testgetindex() {
getindexresponse indexresponse = documentmapper.getindex();
// 这里打印下索引结构信息 其它分片等信息皆可从indexresponse中取
indexresponse.getmappings().foreach((k, v) -> system.out.println(v.getsourceasmap()));
}
更新索引
/**
* 更新索引
*/
@test
public void testupdateindex() {
// 测试更新索引
lambdaesindexwrapper<document> wrapper = new lambdaesindexwrapper<>();
// 指定要更新哪个索引
string indexname = document.class.getsimplename().tolowercase();
wrapper.indexname(indexname);
wrapper.mapping(document::gettitle, fieldtype.keyword);
wrapper.mapping(document::getcontent, fieldtype.text, analyzer.ik_smart, analyzer.ik_max_word);
wrapper.mapping(document::getinfo, fieldtype.text, analyzer.ik_smart, analyzer.ik_max_word);
boolean isok = documentmapper.updateindex(wrapper);
assertions.asserttrue(isok);
}删除索引
@test
public void testdeleteindex() {
// 指定要删除哪个索引
string indexname = document.class.getsimplename().tolowercase();
boolean isok = documentmapper.deleteindex(indexname);
assertions.asserttrue(isok);
}三、数据curd
// 插入一条记录,默认插入至当前mapper对应的索引
integer insert(t entity);
// 插入一条记录 可指定具体插入的索引,多个用逗号隔开
integer insert(t entity, string... indexnames);
// 批量插入多条记录
integer insertbatch(collection<t> entitylist)
// 批量插入多条记录 可指定具体插入的索引,多个用逗号隔开
integer insertbatch(collection<t> entitylist, string... indexnames);
// 根据 id 删除
integer deletebyid(serializable id);
// 根据 id 删除 可指定具体的索引,多个用逗号隔开
integer deletebyid(serializable id, string... indexnames);
// 根据 entity 条件,删除记录
integer delete(lambdaesquerywrapper<t> wrapper);
// 删除(根据id 批量删除)
integer deletebatchids(collection<? extends serializable> idlist);
// 删除(根据id 批量删除)可指定具体的索引,多个用逗号隔开
integer deletebatchids(collection<? extends serializable> idlist, string... indexnames);
//根据 id 更新
integer updatebyid(t entity);
//根据 id 更新 可指定具体的索引,多个用逗号隔开
integer updatebyid(t entity, string... indexnames);
// 根据id 批量更新
integer updatebatchbyids(collection<t> entitylist);
//根据 id 批量更新 可指定具体的索引,多个用逗号隔开
integer updatebatchbyids(collection<t> entitylist, string... indexnames);
// 根据动态条件 更新记录
integer update(t entity, lambdaesupdatewrapper<t> updatewrapper);
// 获取总数
long selectcount(lambdaesquerywrapper<t> wrapper);
// 获取总数 distinct为是否去重 若为ture则必须在wrapper中指定去重字段
long selectcount(wrapper<t> wrapper, boolean distinct);
// 根据 id 查询
t selectbyid(serializable id);
// 根据 id 查询 可指定具体的索引,多个用逗号隔开
t selectbyid(serializable id, string... indexnames);
// 查询(根据id 批量查询)
list<t> selectbatchids(collection<? extends serializable> idlist);
// 查询(根据id 批量查询)可指定具体的索引,多个用逗号隔开
list<t> selectbatchids(collection<? extends serializable> idlist, string... indexnames);
// 根据动态查询条件,查询一条记录 若存在多条记录 会报错
t selectone(lambdaesquerywrapper<t> wrapper);
// 根据动态查询条件,查询全部记录
list<t> selectlist(lambdaesquerywrapper<t> wrapper);
参数文档:easy-es文档
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。






发表评论